 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Scribble-Guided Image Editing: Generalization, Instruction Adherence, and Multi-Tasking
May 25, 2026Scribble-guided image editing allows users to combine simple scribble annotations with text prompts to specify both where and how an image should be edited, enabling flexible interaction with precise spatial control. However, existing models still exhibit unstable performance under this paradigm, especially in multi-task scenarios. To improve performance, we conduct empirical studies using an open-source editing model and reveal an asymmetry in generalization: instruction-level generalization, including across editing tasks and from single-task to multi-task settings, is more challenging than image-domain generalization, such as from synthetic to real-world images or from mosaicked to regular images. This suggests that the primary bottleneck lies in insufficient learning for diverse editing instructions rather than in the image domain gap. Motivated by this insight, we propose three strategies: (a) a Coverage-then-Realism Curriculum, a two-stage pipeline that first builds large-scale synthetic, instruction-rich data for broad task supervision, then curates a small set of real-world data to refine generation realism; (b) Multi-Task Mosaicking, which constructs multi-task training samples by concatenating single-task examples at nearly zero cost while enabling the learned capability to generalize to non-mosaicked images; and (c) an Edit-Focused Loss, which leverages the changed regions between input and output images in synthetic data to focus training on edited regions, improving both learning efficiency and editing accuracy. With these strategies, we substantially improve both single-task and multi-task scribble-guided editing on the VIBE benchmark, achieving state-of-the-art results. We will publicly release our dataset and model.
GAN-based Domain Adaptation for Image-aware Layout Generation in Advertising Poster Design
Apr 08, 2026Layout plays a crucial role in graphic design and poster generation. Recently, the application of deep learning models for layout generation has gained significant attention. This paper focuses on using a GAN-based model conditioned on images to generate advertising poster graphic layouts, requiring a dataset of paired product images and layouts. To address this task, we introduce the Content-aware Graphic Layout Dataset (CGL-Dataset), consisting of 60,548 paired inpainted posters with annotations and 121,000 clean product images. The inpainting artifacts introduce a domain gap between the inpainted posters and clean images. To bridge this gap, we design two GAN-based models. The first model, CGL-GAN, uses Gaussian blur on the inpainted regions to generate layouts. The second model combines unsupervised domain adaptation by introducing a GAN with a pixel-level discriminator (PD), abbreviated as PDA-GAN, to generate image-aware layouts based on the visual texture of input images. The PD is connected to shallow-level feature maps and computes the GAN loss for each input-image pixel. Additionally, we propose three novel content-aware metrics to assess the model's ability to capture the intricate relationships between graphic elements and image content. Quantitative and qualitative evaluations demonstrate that PDA-GAN achieves state-of-the-art performance and generates high-quality image-aware layouts.
FactorHD: A Hyperdimensional Computing Model for Multi-Object Multi-Class Representation and Factorization
Jul 16, 2025Neuro-symbolic artificial intelligence (neuro-symbolic AI) excels in logical analysis and reasoning. Hyperdimensional Computing (HDC), a promising brain-inspired computational model, is integral to neuro-symbolic AI. Various HDC models have been proposed to represent class-instance and class-class relations, but when representing the more complex class-subclass relation, where multiple objects associate different levels of classes and subclasses, they face challenges for factorization, a crucial task for neuro-symbolic AI systems. In this article, we propose FactorHD, a novel HDC model capable of representing and factorizing the complex class-subclass relation efficiently. FactorHD features a symbolic encoding method that embeds an extra memorization clause, preserving more information for multiple objects. In addition, it employs an efficient factorization algorithm that selectively eliminates redundant classes by identifying the memorization clause of the target class. Such model significantly enhances computing efficiency and accuracy in representing and factorizing multiple objects with class-subclass relation, overcoming limitations of existing HDC models such as "superposition catastrophe" and "the problem of 2". Evaluations show that FactorHD achieves approximately 5667x speedup at a representation size of 10^9 compared to existing HDC models. When integrated with the ResNet-18 neural network, FactorHD achieves 92.48% factorization accuracy on the Cifar-10 dataset.
ALF: Advertiser Large Foundation Model for Multi-Modal Advertiser Understanding
Apr 26, 2025



We present ALF (Advertiser Large Foundation model), a multi-modal transformer architecture for understanding advertiser behavior and intent across text, image, video and structured data modalities. Through contrastive learning and multi-task optimization, ALF creates unified advertiser representations that capture both content and behavioral patterns. Our model achieves state-of-the-art performance on critical tasks including fraud detection, policy violation identification, and advertiser similarity matching. In production deployment, ALF reduces false positives by 90% while maintaining 99.8% precision on abuse detection tasks. The architecture's effectiveness stems from its novel combination of multi-modal transformations, inter-sample attention mechanism, spectrally normalized projections, and calibrated probabilistic outputs.
PosterMaker: Towards High-Quality Product Poster Generation with Accurate Text Rendering
Apr 09, 2025Product posters, which integrate subject, scene, and text, are crucial promotional tools for attracting customers. Creating such posters using modern image generation methods is valuable, while the main challenge lies in accurately rendering text, especially for complex writing systems like Chinese, which contains over 10,000 individual characters. In this work, we identify the key to precise text rendering as constructing a character-discriminative visual feature as a control signal. Based on this insight, we propose a robust character-wise representation as control and we develop TextRenderNet, which achieves a high text rendering accuracy of over 90%. Another challenge in poster generation is maintaining the fidelity of user-specific products. We address this by introducing SceneGenNet, an inpainting-based model, and propose subject fidelity feedback learning to further enhance fidelity. Based on TextRenderNet and SceneGenNet, we present PosterMaker, an end-to-end generation framework. To optimize PosterMaker efficiently, we implement a two-stage training strategy that decouples text rendering and background generation learning. Experimental results show that PosterMaker outperforms existing baselines by a remarkable margin, which demonstrates its effectiveness.
PAID: A Framework of Product-Centric Advertising Image Design
Jan 24, 2025In E-commerce platforms, a full advertising image is composed of a background image and marketing taglines. Automatic ad image design reduces human costs and plays a crucial role. For the convenience of users, a novel automatic framework named Product-Centric Advertising Image Design (PAID) is proposed in this work. PAID takes the product foreground image, required taglines, and target size as input and creates an ad image automatically. PAID consists of four sequential stages: prompt generation, layout generation, background image generation, and graphics rendering. Different expert models are trained to conduct these sub-tasks. A visual language model (VLM) based prompt generation model is leveraged to produce a product-matching background prompt. The layout generation model jointly predicts text and image layout according to the background prompt, product, and taglines to achieve the best harmony. An SDXL-based layout-controlled inpainting model is trained to generate an aesthetic background image. Previous ad image design methods take a background image as input and then predict the layout of taglines, which limits the spatial layout due to fixed image content. Innovatively, our PAID adjusts the stages to produce an unrestricted layout. To complete the PAID framework, we created two high-quality datasets, PITA and PIL. Extensive experimental results show that PAID creates more visually pleasing advertising images than previous methods.
SceneBooth: Diffusion-based Framework for Subject-preserved Text-to-Image Generation
Jan 07, 2025



Due to the demand for personalizing image generation, subject-driven text-to-image generation method, which creates novel renditions of an input subject based on text prompts, has received growing research interest. Existing methods often learn subject representation and incorporate it into the prompt embedding to guide image generation, but they struggle with preserving subject fidelity. To solve this issue, this paper approaches a novel framework named SceneBooth for subject-preserved text-to-image generation, which consumes inputs of a subject image, object phrases and text prompts. Instead of learning the subject representation and generating a subject, our SceneBooth fixes the given subject image and generates its background image guided by the text prompts. To this end, our SceneBooth introduces two key components, i.e., a multimodal layout generation module and a background painting module. The former determines the position and scale of the subject by generating appropriate scene layouts that align with text captions, object phrases, and subject visual information. The latter integrates two adapters (ControlNet and Gated Self-Attention) into the latent diffusion model to generate a background that harmonizes with the subject guided by scene layouts and text descriptions. In this manner, our SceneBooth ensures accurate preservation of the subject's appearance in the output. Quantitative and qualitative experimental results demonstrate that SceneBooth significantly outperforms baseline methods in terms of subject preservation, image harmonization and overall quality.
Low-Rank Adaptation for Foundation Models: A Comprehensive Review
Dec 31, 2024The rapid advancement of foundation modelslarge-scale neural networks trained on diverse, extensive datasetshas revolutionized artificial intelligence, enabling unprecedented advancements across domains such as natural language processing, computer vision, and scientific discovery. However, the substantial parameter count of these models, often reaching billions or trillions, poses significant challenges in adapting them to specific downstream tasks. Low-Rank Adaptation (LoRA) has emerged as a highly promising approach for mitigating these challenges, offering a parameter-efficient mechanism to fine-tune foundation models with minimal computational overhead. This survey provides the first comprehensive review of LoRA techniques beyond large Language Models to general foundation models, including recent techniques foundations, emerging frontiers and applications of low-rank adaptation across multiple domains. Finally, this survey discusses key challenges and future research directions in theoretical understanding, scalability, and robustness. This survey serves as a valuable resource for researchers and practitioners working with efficient foundation model adaptation.
GraphMoRE: Mitigating Topological Heterogeneity via Mixture of Riemannian Experts
Dec 15, 2024



Real-world graphs have inherently complex and diverse topological patterns, known as topological heterogeneity. Most existing works learn graph representation in a single constant curvature space that is insufficient to match the complex geometric shapes, resulting in low-quality embeddings with high distortion. This also constitutes a critical challenge for graph foundation models, which are expected to uniformly handle a wide variety of diverse graph data. Recent studies have indicated that product manifold gains the possibility to address topological heterogeneity. However, the product manifold is still homogeneous, which is inadequate and inflexible for representing the mixed heterogeneous topology. In this paper, we propose a novel Graph Mixture of Riemannian Experts (GraphMoRE) framework to effectively tackle topological heterogeneity by personalized fine-grained topology geometry pattern preservation. Specifically, to minimize the embedding distortion, we propose a topology-aware gating mechanism to select the optimal embedding space for each node. By fusing the outputs of diverse Riemannian experts with learned gating weights, we construct personalized mixed curvature spaces for nodes, effectively embedding the graph into a heterogeneous manifold with varying curvatures at different points. Furthermore, to fairly measure pairwise distances between different embedding spaces, we present a concise and effective alignment strategy. Extensive experiments on real-world and synthetic datasets demonstrate that our method achieves superior performance with lower distortion, highlighting its potential for modeling complex graphs with topological heterogeneity, and providing a novel architectural perspective for graph foundation models.
CktGen: Specification-Conditioned Analog Circuit Generation
Oct 01, 2024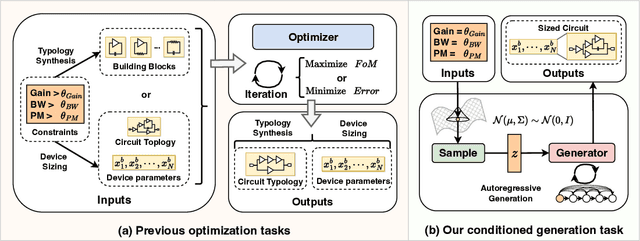

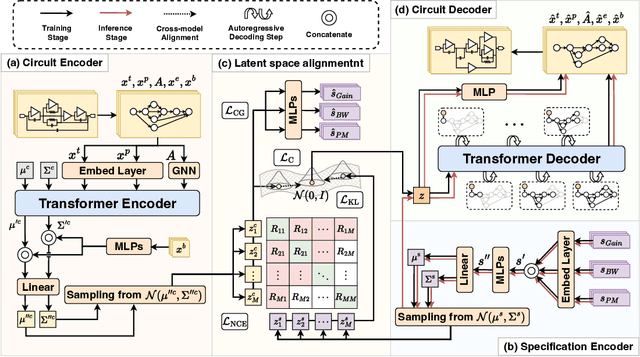
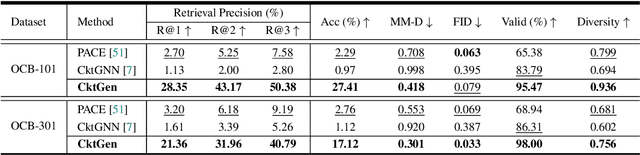
Automatic synthesis of analog circuits presents significant challenges. Existing methods usually treat the task as optimization problems, which limits their transferability and reusability for new requirements. To address this limitation, we introduce a task that directly generates analog circuits based on specified specifications, termed specification-conditioned analog circuit generation. Specifically, we propose CktGen, a simple yet effective variational autoencoder (VAE) model, that maps specifications and circuits into a joint latent space, and reconstructs the circuit from the latent. Moreover, given that a single specification can correspond to multiple distinct circuits, simply minimizing the distance between the mapped latent representations of the circuit and specification does not capture these one-to-many relationships. To address this, we integrate contrastive learning and classifier guidance to prevent model collapse. We conduct comprehensive experiments on the Open Circuit Benchmark (OCB) and introduce new evaluation metrics for cross-model consistency in the specification-to-circuit generation task. Experimental results demonstrate substantial improvements over existing state-of-the-art methods.