 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRADE: Probing Knowledge Gaps in LLMs through Gradient Subspace Dynamics
Apr 03, 2026Detecting whether a model's internal knowledge is sufficient to correctly answer a given question is a fundamental challenge in deploying responsible LLMs. In addition to verbalising the confidence by LLM self-report, more recent methods explore the model internals, such as the hidden states of the response tokens to capture how much knowledge is activated. We argue that such activated knowledge may not align with what the query requires, e.g., capturing the stylistic and length-related features that are uninformative for answering the query. To fill the gap, we propose GRADE (Gradient Dynamics for knowledge gap detection), which quantifies the knowledge gap via the cross-layer rank ratio of the gradient to that of the corresponding hidden state subspace. This is motivated by the property of gradients as estimators of the required knowledge updates for a given target. We validate \modelname{} on six benchmarks, demonstrating its effectiveness and robustness to input perturbations. In addition, we present a case study showing how the gradient chain can generate interpretable explanations of knowledge gaps for long-form answers.
Replacing Parameters with Preferences: Federated Alignment of Heterogeneous Vision-Language Models
Jan 31, 2026VLMs have broad potential in privacy-sensitive domains such as healthcare and finance, yet strict data-sharing constraints render centralized training infeasible. FL mitigates this issue by enabling decentralized training, but practical deployments face challenges due to client heterogeneity in computational resources, application requirements, and model architectures. We argue that while replacing data with model parameters characterizes the present of FL, replacing parameters with preferences represents a more scalable and privacy-preserving future. Motivated by this perspective, we propose MoR, a federated alignment framework based on GRPO with Mixture-of-Rewards for heterogeneous VLMs. MoR initializes a visual foundation model as a KL-regularized reference, while each client locally trains a reward model from local preference annotations, capturing specific evaluation signals without exposing raw data. To reconcile heterogeneous rewards, we introduce a routing-based fusion mechanism that adaptively aggregates client reward signals. Finally, the server performs GRPO with this mixed reward to optimize the base VLM. Experiments on three public VQA benchmarks demonstrate that MoR consistently outperforms federated alignment baselines in generalization, robustness, and cross-client adaptability. Our approach provides a scalable solution for privacy-preserving alignment of heterogeneous VLMs under federated settings.
SAMTok: Representing Any Mask with Two Words
Jan 22, 2026Pixel-wise capabilities are essential for building interactive intelligent systems. However, pixel-wise multi-modal LLMs (MLLMs) remain difficult to scale due to complex region-level encoders, specialized segmentation decoders, and incompatible training objectives. To address these challenges, we present SAMTok, a discrete mask tokenizer that converts any region mask into two special tokens and reconstructs the mask using these tokens with high fidelity. By treating masks as new language tokens, SAMTok enables base MLLMs (such as the QwenVL series) to learn pixel-wise capabilities through standard next-token prediction and simple reinforcement learning, without architectural modifications and specialized loss design. SAMTok builds on SAM2 and is trained on 209M diverse masks using a mask encoder and residual vector quantizer to produce discrete, compact, and information-rich tokens. With 5M SAMTok-formatted mask understanding and generation data samples, QwenVL-SAMTok attains state-of-the-art or comparable results on region captioning, region VQA, grounded conversation, referring segmentation, scene graph parsing, and multi-round interactive segmentation. We further introduce a textual answer-matching reward that enables efficient reinforcement learning for mask generation, delivering substantial improvements on GRES and GCG benchmarks. Our results demonstrate a scalable and straightforward paradigm for equipping MLLMs with strong pixel-wise capabilities. Our code and models are available.
RecTok: Reconstruction Distillation along Rectified Flow
Dec 17, 2025Visual tokenizers play a crucial role in diffusion models. The dimensionality of latent space governs both reconstruction fidelity and the semantic expressiveness of the latent feature. However, a fundamental trade-off is inherent between dimensionality and generation quality, constraining existing methods to low-dimensional latent spaces. Although recent works have leveraged vision foundation models to enrich the semantics of visual tokenizers and accelerate convergence, high-dimensional tokenizers still underperform their low-dimensional counterparts. In this work, we propose RecTok, which overcomes the limitations of high-dimensional visual tokenizers through two key innovations: flow semantic distillation and reconstruction--alignment distillation. Our key insight is to make the forward flow in flow matching semantically rich, which serves as the training space of diffusion transformers, rather than focusing on the latent space as in previous works. Specifically, our method distills the semantic information in VFMs into the forward flow trajectories in flow matching. And we further enhance the semantics by introducing a masked feature reconstruction loss. Our RecTok achieves superior image reconstruction, generation quality, and discriminative performance. It achieves state-of-the-art results on the gFID-50K under both with and without classifier-free guidance settings, while maintaining a semantically rich latent space structure. Furthermore, as the latent dimensionality increases, we observe consistent improvements. Code and model are available at https://shi-qingyu.github.io/rectok.github.io.
Open-o3 Video: Grounded Video Reasoning with Explicit Spatio-Temporal Evidence
Oct 23, 2025Most video reasoning models only generate textual reasoning traces without indicating when and where key evidence appears. Recent models such as OpenAI-o3 have sparked wide interest in evidence-centered reasoning for images, yet extending this ability to videos is more challenging, as it requires joint temporal tracking and spatial localization across dynamic scenes. We introduce Open-o3 Video, a non-agent framework that integrates explicit spatio-temporal evidence into video reasoning, and carefully collect training data and design training strategies to address the aforementioned challenges. The model highlights key timestamps, objects, and bounding boxes alongside its answers, allowing reasoning to be grounded in concrete visual observations. To enable this functionality, we first curate and build two high-quality datasets, STGR-CoT-30k for SFT and STGR-RL-36k for RL, with carefully constructed temporal and spatial annotations, since most existing datasets offer either temporal spans for videos or spatial boxes on images, lacking unified spatio-temporal supervision and reasoning traces. Then, we adopt a cold-start reinforcement learning strategy with multiple specially designed rewards that jointly encourage answer accuracy, temporal alignment, and spatial precision. On V-STAR benchmark, Open-o3 Video achieves state-of-the-art performance, raising mAM by 14.4% and mLGM by 24.2% on the Qwen2.5-VL baseline. Consistent improvements are also observed on a broad range of video understanding benchmarks, including VideoMME, WorldSense, VideoMMMU, and TVGBench. Beyond accuracy, the reasoning traces produced by Open-o3 Video also provide valuable signals for test-time scaling, enabling confidence-aware verification and improving answer reliability.
Learning to Erase Private Knowledge from Multi-Documents for Retrieval-Augmented Large Language Models
Apr 14, 2025



Retrieval-Augmented Generation (RAG) is a promising technique for applying LLMs to proprietary domains. However, retrieved documents may contain sensitive knowledge, posing risks of privacy leakage in generative results. Thus, effectively erasing private information from retrieved documents is a key challenge for RAG. Unlike traditional text anonymization, RAG should consider: (1) the inherent multi-document reasoning may face de-anonymization attacks; (2) private knowledge varies by scenarios, so users should be allowed to customize which information to erase; (3) preserving sufficient publicly available knowledge for generation tasks. This paper introduces the privacy erasure task for RAG and proposes Eraser4RAG, a private knowledge eraser which effectively removes user-defined private knowledge from documents while preserving sufficient public knowledge for generation. Specifically, we first construct a global knowledge graph to identify potential knowledge across documents, aiming to defend against de-anonymization attacks. Then we randomly split it into private and public sub-graphs, and fine-tune Flan-T5 to rewrite the retrieved documents excluding private triples. Finally, PPO algorithm optimizes the rewriting model to minimize private triples and maximize public triples retention. Experiments on four QA datasets demonstrate that Eraser4RAG achieves superior erase performance than GPT-4o.
MTL-LoRA: Low-Rank Adaptation for Multi-Task Learning
Oct 15, 2024



Parameter-efficient fine-tuning (PEFT) has been widely employed for domain adaptation, with LoRA being one of the most prominent methods due to its simplicity and effectiveness. However, in multi-task learning (MTL) scenarios, LoRA tends to obscure the distinction between tasks by projecting sparse high-dimensional features from different tasks into the same dense low-dimensional intrinsic space. This leads to task interference and suboptimal performance for LoRA and its variants. To tackle this challenge, we propose MTL-LoRA, which retains the advantages of low-rank adaptation while significantly enhancing multi-task learning capabilities. MTL-LoRA augments LoRA by incorporating additional task-adaptive parameters that differentiate task-specific information and effectively capture shared knowledge across various tasks within low-dimensional spaces. This approach enables large language models (LLMs) pre-trained on general corpus to adapt to different target task domains with a limited number of trainable parameters. Comprehensive experimental results, including evaluations on public academic benchmarks for natural language understanding, commonsense reasoning, and image-text understanding, as well as real-world industrial text Ads relevance datasets, demonstrate that MTL-LoRA outperforms LoRA and its various variants with comparable or even fewer learnable parameters in multitask learning.
MaFeRw: Query Rewriting with Multi-Aspect Feedbacks for Retrieval-Augmented Large Language Models
Aug 30, 2024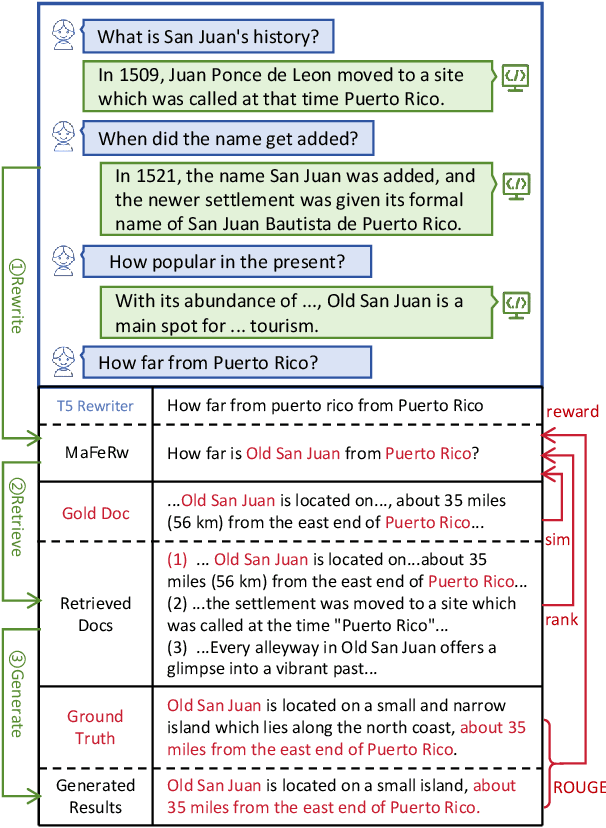

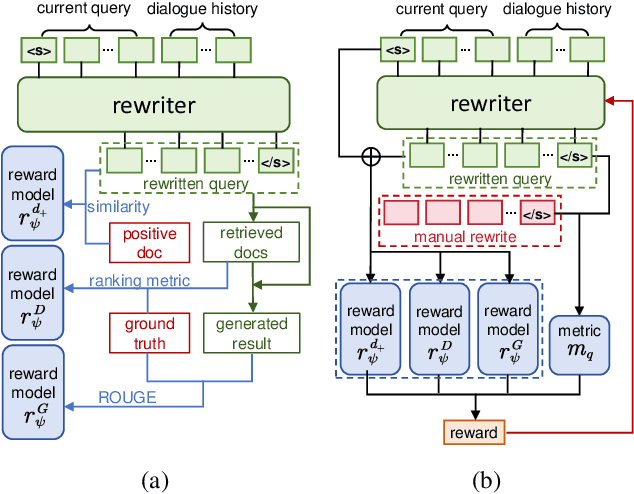

In a real-world RAG system, the current query often involves spoken ellipses and ambiguous references from dialogue contexts, necessitating query rewriting to better describe user's information needs. However, traditional context-based rewriting has minimal enhancement on downstream generation tasks due to the lengthy process from query rewriting to response generation. Some researchers try to utilize reinforcement learning with generation feedback to assist the rewriter, but these sparse rewards provide little guidance in most cases, leading to unstable training and generation results. We find that user's needs are also reflected in the gold document, retrieved documents and ground truth. Therefore, by feeding back these multi-aspect dense rewards to query rewriting, more stable and satisfactory responses can be achieved. In this paper, we propose a novel query rewriting method MaFeRw, which improves RAG performance by integrating multi-aspect feedback from both the retrieval process and generated results. Specifically, we first use manual data to train a T5 model for the rewriter initialization. Next, we design three metrics as reinforcement learning feedback: the similarity between the rewritten query and the gold document, the ranking metrics, and ROUGE between the generation and the ground truth. Inspired by RLAIF, we train three kinds of reward models for the above metrics to achieve more efficient training. Finally, we combine the scores of these reward models as feedback, and use PPO algorithm to explore the optimal query rewriting strategy. Experimental results on two conversational RAG datasets demonstrate that MaFeRw achieves superior generation metrics and more stable training compared to baselines.
You Can't Ignore Either: Unifying Structure and Feature Denoising for Robust Graph Learning
Aug 01, 2024Recent research on the robustness of Graph Neural Networks (GNNs) under noises or attacks has attracted great attention due to its importance in real-world applications. Most previous methods explore a single noise source, recovering corrupt node embedding by reliable structures bias or developing structure learning with reliable node features. However, the noises and attacks may come from both structures and features in graphs, making the graph denoising a dilemma and challenging problem. In this paper, we develop a unified graph denoising (UGD) framework to unravel the deadlock between structure and feature denoising. Specifically, a high-order neighborhood proximity evaluation method is proposed to recognize noisy edges, considering features may be perturbed simultaneously. Moreover, we propose to refine noisy features with reconstruction based on a graph auto-encoder. An iterative updating algorithm is further designed to optimize the framework and acquire a clean graph, thus enabling robust graph learning for downstream tasks. Our UGD framework is self-supervised and can be easily implemented as a plug-and-play module. We carry out extensive experiments, which proves the effectiveness and advantages of our method. Code is avalaible at https://github.com/YoungTimmy/UGD.
Defending Against Sophisticated Poisoning Attacks with RL-based Aggregation in Federated Learning
Jun 20, 2024



Federated learning is highly susceptible to model poisoning attacks, especially those meticulously crafted for servers. Traditional defense methods mainly focus on updating assessments or robust aggregation against manually crafted myopic attacks. When facing advanced attacks, their defense stability is notably insufficient. Therefore, it is imperative to develop adaptive defenses against such advanced poisoning attacks. We find that benign clients exhibit significantly higher data distribution stability than malicious clients in federated learning in both CV and NLP tasks. Therefore, the malicious clients can be recognized by observing the stability of their data distribution. In this paper, we propose AdaAggRL, an RL-based Adaptive Aggregation method, to defend against sophisticated poisoning attacks. Specifically, we first utilize distribution learning to simulate the clients' data distributions. Then, we use the maximum mean discrepancy (MMD) to calculate the pairwise similarity of the current local model data distribution, its historical data distribution, and global model data distribution. Finally, we use policy learning to adaptively determine the aggregation weights based on the above similarities. Experiments on four real-world datasets demonstrate that the proposed defense model significantly outperforms widely adopted defense models for sophisticated attacks.