 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaBitQCache: Rotated Binary Quantization for KVCache in Long Context LLM Inference
Jun 30, 2026Long-context Large Language Model inference is severely bottlenecked by the massive Key-Value (KV) cache, yet existing sparse attention methods often suffer from static fixed-budget (Top-k) retrieval or rely on proxy scores that are computationally expensive and biased. To address these limitations, we propose RaBitQCache, a novel sparse attention framework that utilizes randomized rotated binary quantization and high-throughput binary-INT4 arithmetic to efficiently estimate attention weights. Our proxy score serves as an unbiased estimator with a proven error bound, enabling adaptive Top-p retrieval that dynamically adjusts the token budget based on actual attention sparsity. We further implement a hardware-aware system with asynchronous pipelining and lazy updates to mask overhead. Evaluations demonstrate that RaBitQCache significantly accelerates inference and reduces memory I/O while preserving generation quality compared to state-of-the-art baselines. Code is available at https://github.com/Sakuraaa0/RaBitQCache.git.
MOPD: Multi-Teacher On-Policy Distillation for Capability Integration in LLM Post-Training
Jun 29, 2026Modern large language models (LLMs) rely on reinforcement learning during post-training to push specific capabilities, yet integrating multiple capabilities into one model remains hard. Existing methods, such as Off-Policy Finetune and Mix-RL, are either inefficient or lose performance. In this work, we propose Multi-teacher On-Policy Distillation (MOPD), a post-training paradigm for combining the capabilities of multiple domain RL teachers: we first run per-domain specialised RL to obtain a set of domain teachers, then distill these teachers into the student on its own rollouts. This eliminates exposure bias and provides a dense optimization signal. On Qwen3-30B-A3B, MOPD outperforms Mix-RL, Cascade RL, Off-Policy Finetune, and Param-Merge baselines, inheriting nearly all of each teacher's capability. MOPD also enables parallel, independent development of domain teachers, removing the cross-domain coupling typical of multi-domain post-training. MOPD has been deployed in the post-training of MiMo-V2-Flash, an industrial-scale frontier model, demonstrating its practical value for capability integration in frontier-scale LLMs.
ARL-Tangram: Unleash the Resource Efficiency in Agentic Reinforcement Learning
Mar 13, 2026Agentic reinforcement learning (RL) has emerged as a transformative workload in cloud clusters, enabling large language models (LLMs) to solve complex problems through interactions with real world. However, unlike traditional RL, agentic RL demands substantial external cloud resources, e.g., CPUs for code execution and GPUs for reward models, that exist outside the primary training cluster. Existing agentic RL framework typically rely on static over-provisioning, i.e., resources are often tied to long-lived trajectories or isolated by tasks, which leads to severe resource inefficiency. We propose the action-level orchestration, and incorporate it into ARL-Tangram, a unified resource management system that enables fine-grained external resource sharing and elasticity. ARL-Tangram utilizes a unified action-level formulation and an elastic scheduling algorithm to minimize action completion time (ACT) while satisfying heterogeneous resource constraints. Further, heterogeneous resource managers are tailored to efficiently support the action-level execution on resources with heterogeneous characteristics and topologies. Evaluation on real-world agentic RL tasks demonstrates that ARL-Tangram improves average ACT by up to 4.3$\times$, speeds up the step duration of RL training by up to 1.5$\times$, and saves the external resources by up to 71.2$\%$. This system has been deployed to support the training of the MiMo series models.
HySparse: A Hybrid Sparse Attention Architecture with Oracle Token Selection and KV Cache Sharing
Feb 03, 2026This work introduces Hybrid Sparse Attention (HySparse), a new architecture that interleaves each full attention layer with several sparse attention layers. While conceptually simple, HySparse strategically derives each sparse layer's token selection and KV caches directly from the preceding full attention layer. This architecture resolves two fundamental limitations of prior sparse attention methods. First, conventional approaches typically rely on additional proxies to predict token importance, introducing extra complexity and potentially suboptimal performance. In contrast, HySparse uses the full attention layer as a precise oracle to identify important tokens. Second, existing sparse attention designs often reduce computation without saving KV cache. HySparse enables sparse attention layers to reuse the full attention KV cache, thereby reducing both computation and memory. We evaluate HySparse on both 7B dense and 80B MoE models. Across all settings, HySparse consistently outperforms both full attention and hybrid SWA baselines. Notably, in the 80B MoE model with 49 total layers, only 5 layers employ full attention, yet HySparse achieves substantial performance gains while reducing KV cache storage by nearly 10x.
JudgeRLVR: Judge First, Generate Second for Efficient Reasoning
Jan 13, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become a standard paradigm for reasoning in Large Language Models. However, optimizing solely for final-answer correctness often drives models into aimless, verbose exploration, where they rely on exhaustive trial-and-error tactics rather than structured planning to reach solutions. While heuristic constraints like length penalties can reduce verbosity, they often truncate essential reasoning steps, creating a difficult trade-off between efficiency and verification. In this paper, we argue that discriminative capability is a prerequisite for efficient generation: by learning to distinguish valid solutions, a model can internalize a guidance signal that prunes the search space. We propose JudgeRLVR, a two-stage judge-then-generate paradigm. In the first stage, we train the model to judge solution responses with verifiable answers. In the second stage, we fine-tune the same model with vanilla generating RLVR initialized from the judge. Compared to Vanilla RLVR using the same math-domain training data, JudgeRLVR achieves a better quality--efficiency trade-off for Qwen3-30B-A3B: on in-domain math, it delivers about +3.7 points average accuracy gain with -42\% average generation length; on out-of-domain benchmarks, it delivers about +4.5 points average accuracy improvement, demonstrating enhanced generalization.
MiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
SALE : Low-bit Estimation for Efficient Sparse Attention in Long-context LLM Prefilling
May 30, 2025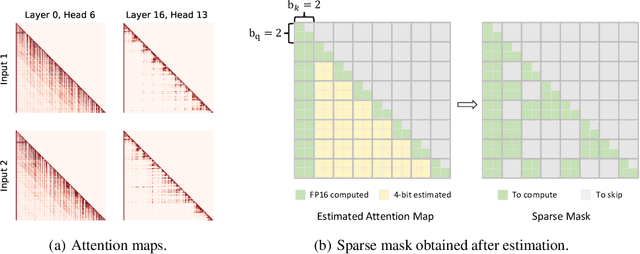
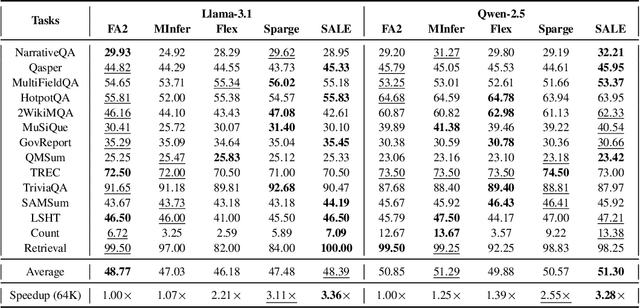
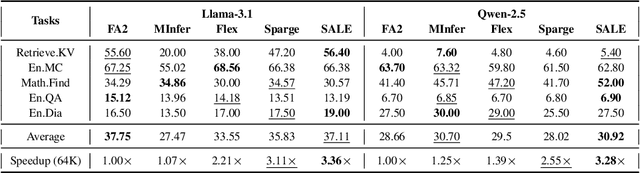
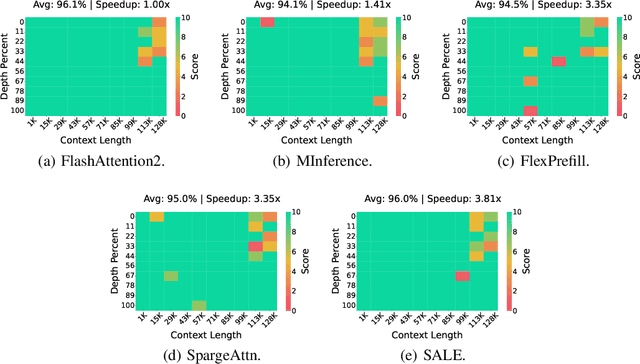
Many advanced Large Language Model (LLM) applications require long-context processing, but the self-attention module becomes a bottleneck during the prefilling stage of inference due to its quadratic time complexity with respect to sequence length. Existing sparse attention methods accelerate attention computation by skipping less significant regions of the attention map. However, these approaches typically perform coarse-grained inspection of the attention map, rendering considerable loss in model accuracy. In this paper, we propose SALE, a fine-grained sparse attention method that accelerates the long-context prefilling stage of LLM with negligible loss in model accuracy. SALE achieves fast and accurate fine-grained attention weight estimation through 4-bit quantized query-key products, followed by block-sparse attention to accelerate prefilling computations. For importance evaluation for query-key pairs, we adopt our Relative Attention Score metric, which offers significantly higher efficiency within our framework. We implement a custom CUDA kernel optimized for our approach for hardware efficiency, reducing the additional overhead to approximately 11% of the full attention latency. Notably, SALE requires no parameter training and can be seamlessly integrated into existing systems with trivial code modifications. Experiments on long-context benchmarks demonstrate that our method outperforms existing approaches in accuracy-efficiency trade-offs, achieving at least 3.36x speedups on Llama-3.1-8B for sequences longer than 64K while maintaining model quality.
MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to Posttraining
May 12, 2025We present MiMo-7B, a large language model born for reasoning tasks, with optimization across both pre-training and post-training stages. During pre-training, we enhance the data preprocessing pipeline and employ a three-stage data mixing strategy to strengthen the base model's reasoning potential. MiMo-7B-Base is pre-trained on 25 trillion tokens, with additional Multi-Token Prediction objective for enhanced performance and accelerated inference speed. During post-training, we curate a dataset of 130K verifiable mathematics and programming problems for reinforcement learning, integrating a test-difficulty-driven code-reward scheme to alleviate sparse-reward issues and employing strategic data resampling to stabilize training. Extensive evaluations show that MiMo-7B-Base possesses exceptional reasoning potential, outperforming even much larger 32B models. The final RL-tuned model, MiMo-7B-RL, achieves superior performance on mathematics, code and general reasoning tasks, surpassing the performance of OpenAI o1-mini. The model checkpoints are available at https://github.com/xiaomimimo/MiMo.
Orbital-Angular-Momentum Embedded Massive MIMO: Achieving Multiplicative Spectrum-Efficiency for mmWave Communications
Aug 13, 2024



By enabling very high bandwidth for radio communications, the millimeter-wave (mmWave), which can easily be integrated with massive-multiple-input-multiple-output (massive-MIMO) due to small antenna size, has been attracting growing attention as a candidate for the fifth-generation (5G) and 5G-beyond wireless communications networks. On the other hand, the communication over the orthogonal states/modes of orbital angular momentum (OAM) is a subset of the solutions offered by massive-MIMO communications. Traditional massive-MIMO based mmWave communications did not concern the potential spectrum-efficiency-gain (SE-gain) offered by orthogonal states of OAM. However, the highly expecting maximum SE-gain for OAM and massive-MIMO communications is the product of SE-gains offered by OAM and multiplexing-MIMO. In this paper, we propose the OAM-embedded-MIMO (OEM) communication framework to obtain the multiplicative SE-gain for joint OAM and massive-MIMO based mmWave wireless communications. We design the parabolic antenna for each uniform circular array antenna to converge OAM signals. Then, we develop the mode-decomposition and multiplexing-detection scheme to obtain the transmit signal on each OAM-mode of each transmit antenna. Also, we develop the OEM-water-filling power allocation policy to achieve the maximum multiplicative SE-gain for OEM communications. The extensive simulations obtained validate and evaluate our developed parabolic antenna based converging method, mode-decomposition and multiplexing-detection scheme, and OEM-water-filling policy, showing that our proposed OEM mmWave communications can significantly increase the spectrum-efficiency as compared with traditional massive-MIMO based mmWave communications.