 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecMoE: Communication-Efficient Secure MoE Inference via Select-Then-Compute
Jan 11, 2026Privacy-preserving Transformer inference has gained attention due to the potential leakage of private information. Despite recent progress, existing frameworks still fall short of practical model scales, with gaps up to a hundredfold. A possible way to close this gap is the Mixture of Experts (MoE) architecture, which has emerged as a promising technique to scale up model capacity with minimal overhead. However, given that the current secure two-party (2-PC) protocols allow the server to homomorphically compute the FFN layer with its plaintext model weight, under the MoE setting, this could reveal which expert is activated to the server, exposing token-level privacy about the client's input. While naively evaluating all the experts before selection could protect privacy, it nullifies MoE sparsity and incurs the heavy computational overhead that sparse MoE seeks to avoid. To address the privacy and efficiency limitations above, we propose a 2-PC privacy-preserving inference framework, \SecMoE. Unifying per-entry circuits in both the MoE layer and piecewise polynomial functions, \SecMoE obliviously selects the extracted parameters from circuits and only computes one encrypted entry, which we refer to as Select-Then-Compute. This makes the model for private inference scale to 63$\times$ larger while only having a 15.2$\times$ increase in end-to-end runtime. Extensive experiments show that, under 5 expert settings, \SecMoE lowers the end-to-end private inference communication by 1.8$\sim$7.1$\times$ and achieves 1.3$\sim$3.8$\times$ speedup compared to the state-of-the-art (SOTA) protocols.
MiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
DIVE into MoE: Diversity-Enhanced Reconstruction of Large Language Models from Dense into Mixture-of-Experts
Jun 11, 2025



Large language models (LLMs) with the Mixture-of-Experts (MoE) architecture achieve high cost-efficiency by selectively activating a subset of the parameters. Despite the inference efficiency of MoE LLMs, the training of extensive experts from scratch incurs substantial overhead, whereas reconstructing a dense LLM into an MoE LLM significantly reduces the training budget. However, existing reconstruction methods often overlook the diversity among experts, leading to potential redundancy. In this paper, we come up with the observation that a specific LLM exhibits notable diversity after being pruned on different calibration datasets, based on which we present a Diversity-Enhanced reconstruction method named DIVE. The recipe of DIVE includes domain affinity mining, pruning-based expert reconstruction, and efficient retraining. Specifically, the reconstruction includes pruning and reassembly of the feed-forward network (FFN) module. After reconstruction, we efficiently retrain the model on routers, experts and normalization modules. We implement DIVE on Llama-style LLMs with open-source training corpora. Experiments show that DIVE achieves training efficiency with minimal accuracy trade-offs, outperforming existing pruning and MoE reconstruction methods with the same number of activated parameters.
TailorKV: A Hybrid Framework for Long-Context Inference via Tailored KV Cache Optimization
May 26, 2025



The Key-Value (KV) cache in generative large language models (LLMs) introduces substantial memory overhead. Existing works mitigate this burden by offloading or compressing the KV cache. However, loading the entire cache incurs significant latency due to PCIe bandwidth bottlenecks in CPU-GPU communication, while aggressive compression causes notable performance degradation. We identify that certain layers in the LLM need to maintain global information and are unsuitable for selective loading. In contrast, other layers primarily focus on a few tokens with dominant activations that potentially incur substantial quantization error. This observation leads to a key insight that loading dominant tokens and quantizing all tokens can complement each other. Building on this insight, we propose a hybrid compression method, TailorKV, which seamlessly integrates quantization and offloading. TailorKV develops an inference framework along with a hardware-friendly implementation that leverages these complementary characteristics. Extensive long-context evaluations exhibit that TailorKV achieves nearly lossless performance under aggressive compression settings, outperforming the state-of-the-art. Particularly, the Llama-3.1-8B with 128k context can be served within a single RTX 3090 GPU, reaching 82 ms per token during decoding.
MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to Posttraining
May 12, 2025We present MiMo-7B, a large language model born for reasoning tasks, with optimization across both pre-training and post-training stages. During pre-training, we enhance the data preprocessing pipeline and employ a three-stage data mixing strategy to strengthen the base model's reasoning potential. MiMo-7B-Base is pre-trained on 25 trillion tokens, with additional Multi-Token Prediction objective for enhanced performance and accelerated inference speed. During post-training, we curate a dataset of 130K verifiable mathematics and programming problems for reinforcement learning, integrating a test-difficulty-driven code-reward scheme to alleviate sparse-reward issues and employing strategic data resampling to stabilize training. Extensive evaluations show that MiMo-7B-Base possesses exceptional reasoning potential, outperforming even much larger 32B models. The final RL-tuned model, MiMo-7B-RL, achieves superior performance on mathematics, code and general reasoning tasks, surpassing the performance of OpenAI o1-mini. The model checkpoints are available at https://github.com/xiaomimimo/MiMo.
Pruning Large Language Models to Intra-module Low-rank Architecture with Transitional Activations
Jul 08, 2024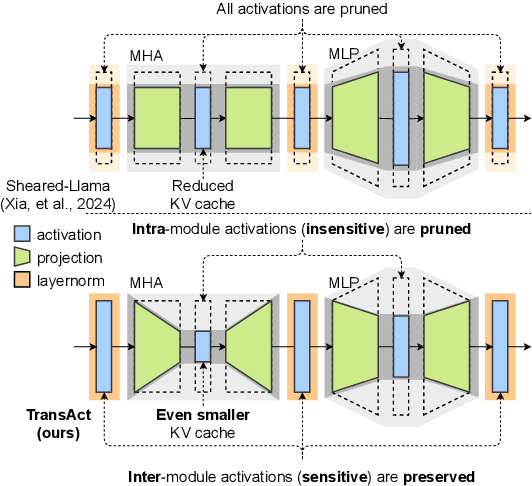
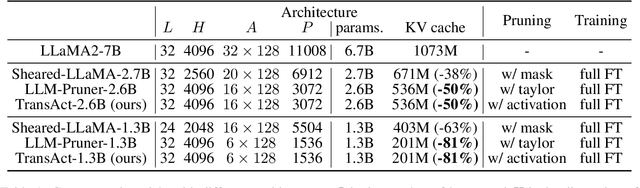
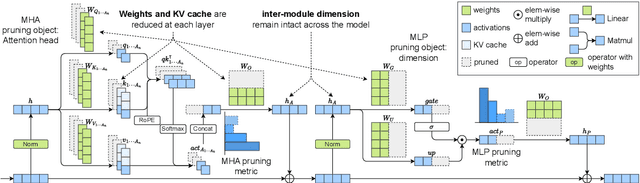
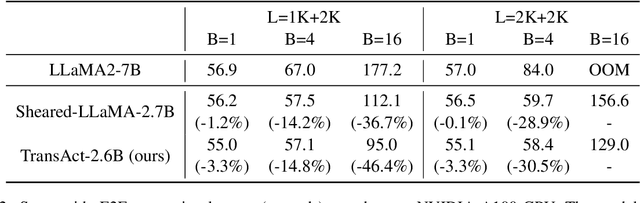
Structured pruning fundamentally reduces computational and memory overheads of large language models (LLMs) and offers a feasible solution for end-side LLM deployment. Structurally pruned models remain dense and high-precision, highly compatible with further tuning and compression. However, as the coarse-grained structured pruning poses large damage to the highly interconnected model, achieving a high compression ratio for scaled-up LLMs remains a challenge. In this paper, we introduce a task-agnostic structured pruning approach coupled with a compact Transformer architecture design. The proposed approach, named TransAct, reduces transitional activations inside multi-head attention (MHA) and multi-layer perceptron (MLP) modules, while preserving the inter-module activations that are sensitive to perturbations. Hence, the LLM is pruned into an intra-module low-rank architecture, significantly reducing weights, KV Cache and attention computation. TransAct is implemented on the LLaMA model and evaluated on downstream benchmarks. Results verify the optimality of our approach at high compression with respect to both efficiency and performance. Further, ablation studies reveal the strength of activation-guided iterative pruning and provide experimental analysis on the redundancy of MHA and MLP modules.
Light-PEFT: Lightening Parameter-Efficient Fine-Tuning via Early Pruning
Jun 06, 2024Parameter-efficient fine-tuning (PEFT) has emerged as the predominant technique for fine-tuning in the era of large language models. However, existing PEFT methods still have inadequate training efficiency. Firstly, the utilization of large-scale foundation models during the training process is excessively redundant for certain fine-tuning tasks. Secondly, as the model size increases, the growth in trainable parameters of empirically added PEFT modules becomes non-negligible and redundant, leading to inefficiency. To achieve task-specific efficient fine-tuning, we propose the Light-PEFT framework, which includes two methods: Masked Early Pruning of the Foundation Model and Multi-Granularity Early Pruning of PEFT. The Light-PEFT framework allows for the simultaneous estimation of redundant parameters in both the foundation model and PEFT modules during the early stage of training. These parameters can then be pruned for more efficient fine-tuning. We validate our approach on GLUE, SuperGLUE, QA tasks, and various models. With Light-PEFT, parameters of the foundation model can be pruned by up to over 40%, while still controlling trainable parameters to be only 25% of the original PEFT method. Compared to utilizing the PEFT method directly, Light-PEFT achieves training and inference speedup, reduces memory usage, and maintains comparable performance and the plug-and-play feature of PEFT.
SMAT: A Self-Reinforcing Framework for Simultaneous Mapping and Tracking in Unbounded Urban Environments
Apr 27, 2023With the increasing prevalence of robots in daily life, it is crucial to enable robots to construct a reliable map online to navigate in unbounded and changing environments. Although existing methods can individually achieve the goals of spatial mapping and dynamic object detection and tracking, limited research has been conducted on an effective combination of these two important abilities. The proposed framework, SMAT (Simultaneous Mapping and Tracking), integrates the front-end dynamic object detection and tracking module with the back-end static mapping module using a self-reinforcing mechanism, which promotes mutual improvement of mapping and tracking performance. The conducted experiments demonstrate the framework's effectiveness in real-world applications, achieving successful long-range navigation and mapping in multiple urban environments using only one LiDAR, a CPU-only onboard computer, and a consumer-level GPS receiver.
COST-EFF: Collaborative Optimization of Spatial and Temporal Efficiency with Slenderized Multi-exit Language Models
Oct 27, 2022Transformer-based pre-trained language models (PLMs) mostly suffer from excessive overhead despite their advanced capacity. For resource-constrained devices, there is an urgent need for a spatially and temporally efficient model which retains the major capacity of PLMs. However, existing statically compressed models are unaware of the diverse complexities between input instances, potentially resulting in redundancy and inadequacy for simple and complex inputs. Also, miniature models with early exiting encounter challenges in the trade-off between making predictions and serving the deeper layers. Motivated by such considerations, we propose a collaborative optimization for PLMs that integrates static model compression and dynamic inference acceleration. Specifically, the PLM is slenderized in width while the depth remains intact, complementing layer-wise early exiting to speed up inference dynamically. To address the trade-off of early exiting, we propose a joint training approach that calibrates slenderization and preserves contributive structures to each exit instead of only the final layer. Experiments are conducted on GLUE benchmark and the results verify the Pareto optimality of our approach at high compression and acceleration rate with 1/8 parameters and 1/19 FLOPs of BERT.