 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExDR: Explanation-driven Dynamic Retrieval Enhancement for Multimodal Fake News Detection
Jan 22, 2026The rapid spread of multimodal fake news poses a serious societal threat, as its evolving nature and reliance on timely factual details challenge existing detection methods. Dynamic Retrieval-Augmented Generation provides a promising solution by triggering keyword-based retrieval and incorporating external knowledge, thus enabling both efficient and accurate evidence selection. However, it still faces challenges in addressing issues such as redundant retrieval, coarse similarity, and irrelevant evidence when applied to deceptive content. In this paper, we propose ExDR, an Explanation-driven Dynamic Retrieval-Augmented Generation framework for Multimodal Fake News Detection. Our framework systematically leverages model-generated explanations in both the retrieval triggering and evidence retrieval modules. It assesses triggering confidence from three complementary dimensions, constructs entity-aware indices by fusing deceptive entities, and retrieves contrastive evidence based on deception-specific features to challenge the initial claim and enhance the final prediction. Experiments on two benchmark datasets, AMG and MR2, demonstrate that ExDR consistently outperforms previous methods in retrieval triggering accuracy, retrieval quality, and overall detection performance, highlighting its effectiveness and generalization capability.
R-Search: Empowering LLM Reasoning with Search via Multi-Reward Reinforcement Learning
Jun 04, 2025Large language models (LLMs) have notably progressed in multi-step and long-chain reasoning. However, extending their reasoning capabilities to encompass deep interactions with search remains a non-trivial challenge, as models often fail to identify optimal reasoning-search interaction trajectories, resulting in suboptimal responses. We propose R-Search, a novel reinforcement learning framework for Reasoning-Search integration, designed to enable LLMs to autonomously execute multi-step reasoning with deep search interaction, and learn optimal reasoning search interaction trajectories via multi-reward signals, improving response quality in complex logic- and knowledge-intensive tasks. R-Search guides the LLM to dynamically decide when to retrieve or reason, while globally integrating key evidence to enhance deep knowledge interaction between reasoning and search. During RL training, R-Search provides multi-stage, multi-type rewards to jointly optimize the reasoning-search trajectory. Experiments on seven datasets show that R-Search outperforms advanced RAG baselines by up to 32.2% (in-domain) and 25.1% (out-of-domain). The code and data are available at https://github.com/QingFei1/R-Search.
Towards Multi-Source Retrieval-Augmented Generation via Synergizing Reasoning and Preference-Driven Retrieval
Nov 01, 2024



Retrieval-Augmented Generation (RAG) has emerged as a reliable external knowledge augmentation technique to mitigate hallucination issues and parameterized knowledge limitations in Large Language Models (LLMs). Existing Adaptive RAG (ARAG) systems struggle to effectively explore multiple retrieval sources due to their inability to select the right source at the right time. To address this, we propose a multi-source ARAG framework, termed MSPR, which synergizes reasoning and preference-driven retrieval to adaptive decide "when and what to retrieve" and "which retrieval source to use". To better adapt to retrieval sources of differing characteristics, we also employ retrieval action adjustment and answer feedback strategy. They enable our framework to fully explore the high-quality primary source while supplementing it with secondary sources at the right time. Extensive and multi-dimensional experiments conducted on three datasets demonstrate the superiority and effectiveness of MSPR.
LongRAG: A Dual-Perspective Retrieval-Augmented Generation Paradigm for Long-Context Question Answering
Oct 23, 2024Long-Context Question Answering (LCQA), a challenging task, aims to reason over long-context documents to yield accurate answers to questions. Existing long-context Large Language Models (LLMs) for LCQA often struggle with the "lost in the middle" issue. Retrieval-Augmented Generation (RAG) mitigates this issue by providing external factual evidence. However, its chunking strategy disrupts the global long-context information, and its low-quality retrieval in long contexts hinders LLMs from identifying effective factual details due to substantial noise. To this end, we propose LongRAG, a general, dual-perspective, and robust LLM-based RAG system paradigm for LCQA to enhance RAG's understanding of complex long-context knowledge (i.e., global information and factual details). We design LongRAG as a plug-and-play paradigm, facilitating adaptation to various domains and LLMs. Extensive experiments on three multi-hop datasets demonstrate that LongRAG significantly outperforms long-context LLMs (up by 6.94%), advanced RAG (up by 6.16%), and Vanilla RAG (up by 17.25%). Furthermore, we conduct quantitative ablation studies and multi-dimensional analyses, highlighting the effectiveness of the system's components and fine-tuning strategies. Data and code are available at https://github.com/QingFei1/LongRAG.
Retriever-and-Memory: Towards Adaptive Note-Enhanced Retrieval-Augmented Generation
Oct 11, 2024



Retrieval-Augmented Generation (RAG) mitigates issues of the factual errors and hallucinated outputs generated by Large Language Models (LLMs) in open-domain question-answering tasks (OpenQA) via introducing external knowledge. For complex QA, however, existing RAG methods use LLMs to actively predict retrieval timing and directly use the retrieved information for generation, regardless of whether the retrieval timing accurately reflects the actual information needs, or sufficiently considers prior retrieved knowledge, which may result in insufficient information gathering and interaction, yielding low-quality answers. To address these, we propose a generic RAG approach called Adaptive Note-Enhanced RAG (Adaptive-Note) for complex QA tasks, which includes the iterative information collector, adaptive memory reviewer, and task-oriented generator, while following a new Retriever-and-Memory paradigm. Specifically, Adaptive-Note introduces an overarching view of knowledge growth, iteratively gathering new information in the form of notes and updating them into the existing optimal knowledge structure, enhancing high-quality knowledge interactions. In addition, we employ an adaptive, note-based stop-exploration strategy to decide "what to retrieve and when to stop" to encourage sufficient knowledge exploration. We conduct extensive experiments on five complex QA datasets, and the results demonstrate the superiority and effectiveness of our method and its components. The code and data are at https://github.com/thunlp/Adaptive-Note.
Pruning Large Language Models to Intra-module Low-rank Architecture with Transitional Activations
Jul 08, 2024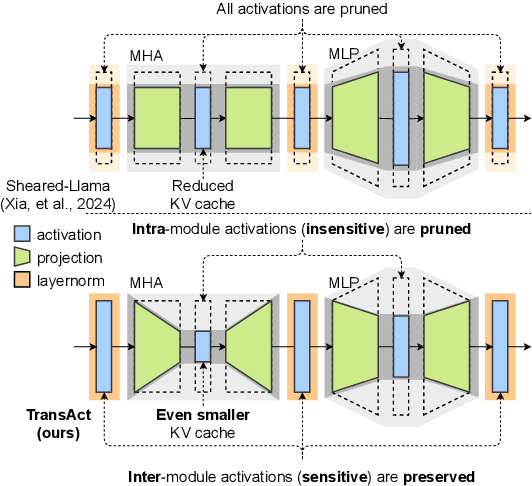
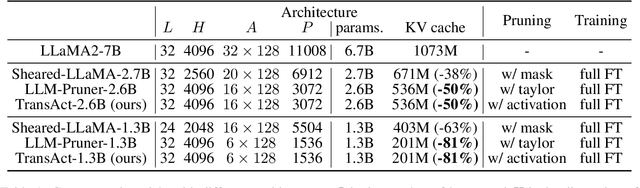
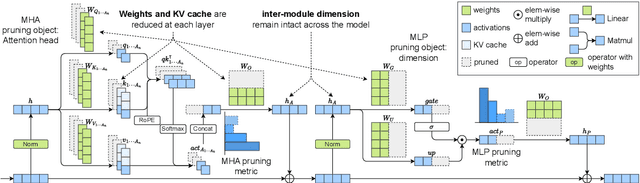
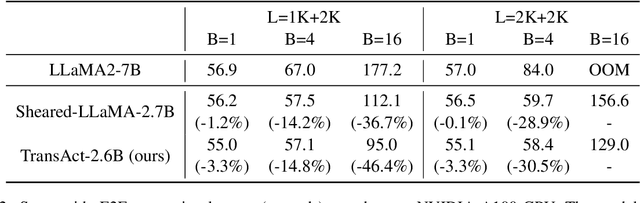
Structured pruning fundamentally reduces computational and memory overheads of large language models (LLMs) and offers a feasible solution for end-side LLM deployment. Structurally pruned models remain dense and high-precision, highly compatible with further tuning and compression. However, as the coarse-grained structured pruning poses large damage to the highly interconnected model, achieving a high compression ratio for scaled-up LLMs remains a challenge. In this paper, we introduce a task-agnostic structured pruning approach coupled with a compact Transformer architecture design. The proposed approach, named TransAct, reduces transitional activations inside multi-head attention (MHA) and multi-layer perceptron (MLP) modules, while preserving the inter-module activations that are sensitive to perturbations. Hence, the LLM is pruned into an intra-module low-rank architecture, significantly reducing weights, KV Cache and attention computation. TransAct is implemented on the LLaMA model and evaluated on downstream benchmarks. Results verify the optimality of our approach at high compression with respect to both efficiency and performance. Further, ablation studies reveal the strength of activation-guided iterative pruning and provide experimental analysis on the redundancy of MHA and MLP modules.