 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLagrangian Relaxation Score-based Generation for Mixed Integer linear Programming
Mar 25, 2026Predict-and-search (PaS) methods have shown promise for accelerating mixed-integer linear programming (MILP) solving. However, existing approaches typically assume variable independence and rely on deterministic single-point predictions, which limits solution diversityand often necessitates extensive downstream search for high-quality solutions. In this paper, we propose \textbf{SRG}, a generative framework based on Lagrangian relaxation-guided stochastic differential equations (SDEs), with theoretical guarantees on solution quality. SRG leverages convolutional kernels to capture inter-variable dependencies while integrating Lagrangian relaxation to guide the sampling process toward feasible and near-optimal regions. Rather than producing a single estimate, SRG generates diverse, high-quality solution candidates that collectively define compact and effective trust-region subproblems for standard MILP solvers. Across multiple public benchmarks, SRG consistently outperforms existing machine learning baselines in solution quality. Moreover, SRG demonstrates strong zero-shot transferability: on unseen cross-scale/problem instances, it achieves competitive optimality with state-of-the-art exact solvers while significantly reducing computational overhead through faster search and superior solution quality.
R-Search: Empowering LLM Reasoning with Search via Multi-Reward Reinforcement Learning
Jun 04, 2025Large language models (LLMs) have notably progressed in multi-step and long-chain reasoning. However, extending their reasoning capabilities to encompass deep interactions with search remains a non-trivial challenge, as models often fail to identify optimal reasoning-search interaction trajectories, resulting in suboptimal responses. We propose R-Search, a novel reinforcement learning framework for Reasoning-Search integration, designed to enable LLMs to autonomously execute multi-step reasoning with deep search interaction, and learn optimal reasoning search interaction trajectories via multi-reward signals, improving response quality in complex logic- and knowledge-intensive tasks. R-Search guides the LLM to dynamically decide when to retrieve or reason, while globally integrating key evidence to enhance deep knowledge interaction between reasoning and search. During RL training, R-Search provides multi-stage, multi-type rewards to jointly optimize the reasoning-search trajectory. Experiments on seven datasets show that R-Search outperforms advanced RAG baselines by up to 32.2% (in-domain) and 25.1% (out-of-domain). The code and data are available at https://github.com/QingFei1/R-Search.
Towards Multi-Source Retrieval-Augmented Generation via Synergizing Reasoning and Preference-Driven Retrieval
Nov 01, 2024



Retrieval-Augmented Generation (RAG) has emerged as a reliable external knowledge augmentation technique to mitigate hallucination issues and parameterized knowledge limitations in Large Language Models (LLMs). Existing Adaptive RAG (ARAG) systems struggle to effectively explore multiple retrieval sources due to their inability to select the right source at the right time. To address this, we propose a multi-source ARAG framework, termed MSPR, which synergizes reasoning and preference-driven retrieval to adaptive decide "when and what to retrieve" and "which retrieval source to use". To better adapt to retrieval sources of differing characteristics, we also employ retrieval action adjustment and answer feedback strategy. They enable our framework to fully explore the high-quality primary source while supplementing it with secondary sources at the right time. Extensive and multi-dimensional experiments conducted on three datasets demonstrate the superiority and effectiveness of MSPR.
LongRAG: A Dual-Perspective Retrieval-Augmented Generation Paradigm for Long-Context Question Answering
Oct 23, 2024Long-Context Question Answering (LCQA), a challenging task, aims to reason over long-context documents to yield accurate answers to questions. Existing long-context Large Language Models (LLMs) for LCQA often struggle with the "lost in the middle" issue. Retrieval-Augmented Generation (RAG) mitigates this issue by providing external factual evidence. However, its chunking strategy disrupts the global long-context information, and its low-quality retrieval in long contexts hinders LLMs from identifying effective factual details due to substantial noise. To this end, we propose LongRAG, a general, dual-perspective, and robust LLM-based RAG system paradigm for LCQA to enhance RAG's understanding of complex long-context knowledge (i.e., global information and factual details). We design LongRAG as a plug-and-play paradigm, facilitating adaptation to various domains and LLMs. Extensive experiments on three multi-hop datasets demonstrate that LongRAG significantly outperforms long-context LLMs (up by 6.94%), advanced RAG (up by 6.16%), and Vanilla RAG (up by 17.25%). Furthermore, we conduct quantitative ablation studies and multi-dimensional analyses, highlighting the effectiveness of the system's components and fine-tuning strategies. Data and code are available at https://github.com/QingFei1/LongRAG.
Retriever-and-Memory: Towards Adaptive Note-Enhanced Retrieval-Augmented Generation
Oct 11, 2024



Retrieval-Augmented Generation (RAG) mitigates issues of the factual errors and hallucinated outputs generated by Large Language Models (LLMs) in open-domain question-answering tasks (OpenQA) via introducing external knowledge. For complex QA, however, existing RAG methods use LLMs to actively predict retrieval timing and directly use the retrieved information for generation, regardless of whether the retrieval timing accurately reflects the actual information needs, or sufficiently considers prior retrieved knowledge, which may result in insufficient information gathering and interaction, yielding low-quality answers. To address these, we propose a generic RAG approach called Adaptive Note-Enhanced RAG (Adaptive-Note) for complex QA tasks, which includes the iterative information collector, adaptive memory reviewer, and task-oriented generator, while following a new Retriever-and-Memory paradigm. Specifically, Adaptive-Note introduces an overarching view of knowledge growth, iteratively gathering new information in the form of notes and updating them into the existing optimal knowledge structure, enhancing high-quality knowledge interactions. In addition, we employ an adaptive, note-based stop-exploration strategy to decide "what to retrieve and when to stop" to encourage sufficient knowledge exploration. We conduct extensive experiments on five complex QA datasets, and the results demonstrate the superiority and effectiveness of our method and its components. The code and data are at https://github.com/thunlp/Adaptive-Note.
Pioneering Reliable Assessment in Text-to-Image Knowledge Editing: Leveraging a Fine-Grained Dataset and an Innovative Criterion
Sep 26, 2024During pre-training, the Text-to-Image (T2I) diffusion models encode factual knowledge into their parameters. These parameterized facts enable realistic image generation, but they may become obsolete over time, thereby misrepresenting the current state of the world. Knowledge editing techniques aim to update model knowledge in a targeted way. However, facing the dual challenges posed by inadequate editing datasets and unreliable evaluation criterion, the development of T2I knowledge editing encounter difficulties in effectively generalizing injected knowledge. In this work, we design a T2I knowledge editing framework by comprehensively spanning on three phases: First, we curate a dataset \textbf{CAKE}, comprising paraphrase and multi-object test, to enable more fine-grained assessment on knowledge generalization. Second, we propose a novel criterion, \textbf{adaptive CLIP threshold}, to effectively filter out false successful images under the current criterion and achieve reliable editing evaluation. Finally, we introduce \textbf{MPE}, a simple but effective approach for T2I knowledge editing. Instead of tuning parameters, MPE precisely recognizes and edits the outdated part of the conditioning text-prompt to accommodate the up-to-date knowledge. A straightforward implementation of MPE (Based on in-context learning) exhibits better overall performance than previous model editors. We hope these efforts can further promote faithful evaluation of T2I knowledge editing methods.
RAGEval: Scenario Specific RAG Evaluation Dataset Generation Framework
Aug 02, 2024



Retrieval-Augmented Generation (RAG) systems have demonstrated their advantages in alleviating the hallucination of Large Language Models (LLMs). Existing RAG benchmarks mainly focus on evaluating whether LLMs can correctly answer the general knowledge. However, they are unable to evaluate the effectiveness of the RAG system in dealing with the data from different vertical domains. This paper introduces RAGEval, a framework for automatically generating evaluation datasets to evaluate the knowledge usage ability of different LLMs in different scenarios. Specifically, RAGEval summarizes a schema from seed documents, applies the configurations to generate diverse documents, and constructs question-answering pairs according to both articles and configurations. We propose three novel metrics, Completeness, Hallucination, and Irrelevance, to carefully evaluate the responses generated by LLMs. By benchmarking RAG models in vertical domains, RAGEval has the ability to better evaluate the knowledge usage ability of LLMs, which avoids the confusion regarding the source of knowledge in answering question in existing QA datasets--whether it comes from parameterized memory or retrieval.
Balancing User Preferences by Social Networks: A Condition-Guided Social Recommendation Model for Mitigating Popularity Bias
May 27, 2024



Social recommendation models weave social interactions into their design to provide uniquely personalized recommendation results for users. However, social networks not only amplify the popularity bias in recommendation models, resulting in more frequent recommendation of hot items and fewer long-tail items, but also include a substantial amount of redundant information that is essentially meaningless for the model's performance. Existing social recommendation models fail to address the issues of popularity bias and the redundancy of social information, as they directly characterize social influence across the entire social network without making targeted adjustments. In this paper, we propose a Condition-Guided Social Recommendation Model (named CGSoRec) to mitigate the model's popularity bias by denoising the social network and adjusting the weights of user's social preferences. More specifically, CGSoRec first includes a Condition-Guided Social Denoising Model (CSD) to remove redundant social relations in the social network for capturing users' social preferences with items more precisely. Then, CGSoRec calculates users' social preferences based on denoised social network and adjusts the weights in users' social preferences to make them can counteract the popularity bias present in the recommendation model. At last, CGSoRec includes a Condition-Guided Diffusion Recommendation Model (CGD) to introduce the adjusted social preferences as conditions to control the recommendation results for a debiased direction. Comprehensive experiments on three real-world datasets demonstrate the effectiveness of our proposed method. The code is in: https://github.com/hexin5515/CGSoRec.
PokeMQA: Programmable knowledge editing for Multi-hop Question Answering
Dec 23, 2023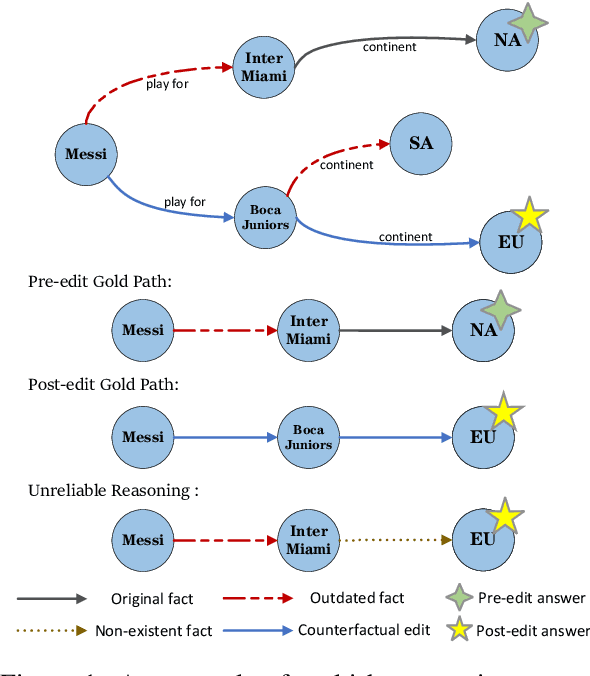



Multi-hop question answering (MQA) is one of the challenging tasks to evaluate machine's comprehension and reasoning abilities, where large language models (LLMs) have widely achieved the human-comparable performance. Due to the dynamics of knowledge facts in real world, knowledge editing has been explored to update model with the up-to-date facts while avoiding expensive re-training or fine-tuning. Starting from the edited fact, the updated model needs to provide cascading changes in the chain of MQA. The previous art simply adopts a mix-up prompt to instruct LLMs conducting multiple reasoning tasks sequentially, including question decomposition, answer generation, and conflict checking via comparing with edited facts. However, the coupling of these functionally-diverse reasoning tasks inhibits LLMs' advantages in comprehending and answering questions while disturbing them with the unskilled task of conflict checking. We thus propose a framework, Programmable knowledge editing for Multi-hop Question Answering (PokeMQA), to decouple the jobs. Specifically, we prompt LLMs to decompose knowledge-augmented multi-hop question, while interacting with a detached trainable scope detector to modulate LLMs behavior depending on external conflict signal. The experiments on three LLM backbones and two benchmark datasets validate our superiority in knowledge editing of MQA, outperforming all competitors by a large margin in almost all settings and consistently producing reliable reasoning process.
SVAM: Saliency-guided Visual Attention Modeling by Autonomous Underwater Robots
Nov 12, 2020



This paper presents a holistic approach to saliency-guided visual attention modeling (SVAM) for use by autonomous underwater robots. Our proposed model, named SVAM-Net, integrates deep visual features at various scales and semantics for effective salient object detection (SOD) in natural underwater images. The SVAM-Net architecture is configured in a unique way to jointly accommodate bottom-up and top-down learning within two separate branches of the network while sharing the same encoding layers. We design dedicated spatial attention modules (SAMs) along these learning pathways to exploit the coarse-level and fine-level semantic features for SOD at four stages of abstractions. The bottom-up branch performs a rough yet reasonably accurate saliency estimation at a fast rate, whereas the deeper top-down branch incorporates a residual refinement module (RRM) that provides fine-grained localization of the salient objects. Extensive performance evaluation of SVAM-Net on benchmark datasets clearly demonstrates its effectiveness for underwater SOD. We also validate its generalization performance by several ocean trials' data that include test images of diverse underwater scenes and waterbodies, and also images with unseen natural objects. Moreover, we analyze its computational feasibility for robotic deployments and demonstrate its utility in several important use cases of visual attention modeling.