 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Lack of Stable Internal Beliefs in LLMs
Mar 26, 2026Persona-driven large language models (LLMs) require consistent behavioral tendencies across interactions to simulate human-like personality traits, such as persistence or reliability. However, current LLMs often lack stable internal representations that anchor their responses over extended dialogues. This work explores whether LLMs can maintain "implicit consistency", defined as persistent adherence to an unstated goal in multi-turn interactions. We designed a 20-question-style riddle game paradigm where an LLM is tasked with secretly selecting a target and responding to users' guesses with "yes/no" answers. Through evaluations, we find that LLMs struggle to preserve latent consistency: their implicit "goals" shift across turns unless explicitly provided their selected target in context. These findings highlight critical limitations in the building of persona-driven LLMs and underscore the need for mechanisms that anchor implicit goals over time, which is a key to realistic personality modeling in interactive applications such as dialogue systems.
From Atoms to Trees: Building a Structured Feature Forest with Hierarchical Sparse Autoencoders
Feb 12, 2026Sparse autoencoders (SAEs) have proven effective for extracting monosemantic features from large language models (LLMs), yet these features are typically identified in isolation. However, broad evidence suggests that LLMs capture the intrinsic structure of natural language, where the phenomenon of "feature splitting" in particular indicates that such structure is hierarchical. To capture this, we propose the Hierarchical Sparse Autoencoder (HSAE), which jointly learns a series of SAEs and the parent-child relationships between their features. HSAE strengthens the alignment between parent and child features through two novel mechanisms: a structural constraint loss and a random feature perturbation mechanism. Extensive experiments across various LLMs and layers demonstrate that HSAE consistently recovers semantically meaningful hierarchies, supported by both qualitative case studies and rigorous quantitative metrics. At the same time, HSAE preserves the reconstruction fidelity and interpretability of standard SAEs across different dictionary sizes. Our work provides a powerful, scalable tool for discovering and analyzing the multi-scale conceptual structures embedded in LLM representations.
InverseScope: Scalable Activation Inversion for Interpreting Large Language Models
Jun 09, 2025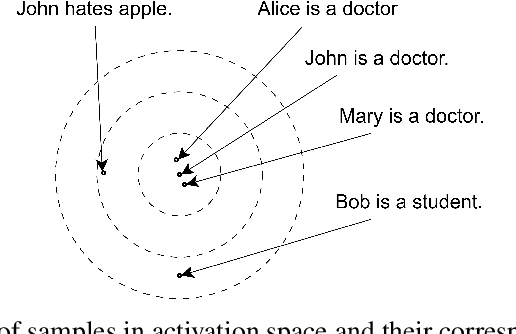


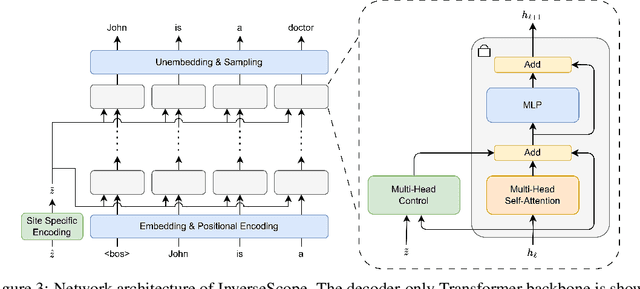
Understanding the internal representations of large language models (LLMs) is a central challenge in interpretability research. Existing feature interpretability methods often rely on strong assumptions about the structure of representations that may not hold in practice. In this work, we introduce InverseScope, an assumption-light and scalable framework for interpreting neural activations via input inversion. Given a target activation, we define a distribution over inputs that generate similar activations and analyze this distribution to infer the encoded features. To address the inefficiency of sampling in high-dimensional spaces, we propose a novel conditional generation architecture that significantly improves sample efficiency compared to previous methods. We further introduce a quantitative evaluation protocol that tests interpretability hypotheses using feature consistency rate computed over the sampled inputs. InverseScope scales inversion-based interpretability methods to larger models and practical tasks, enabling systematic and quantitative analysis of internal representations in real-world LLMs.
Jailbreak Instruction-Tuned LLMs via end-of-sentence MLP Re-weighting
Oct 14, 2024
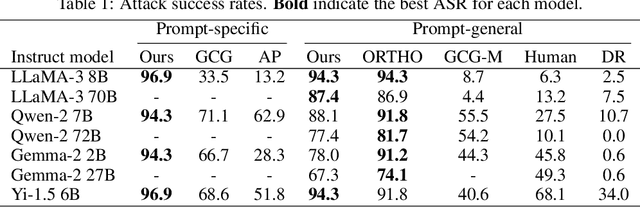
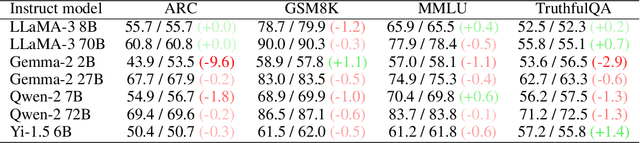
In this paper, we investigate the safety mechanisms of instruction fine-tuned large language models (LLMs). We discover that re-weighting MLP neurons can significantly compromise a model's safety, especially for MLPs in end-of-sentence inferences. We hypothesize that LLMs evaluate the harmfulness of prompts during end-of-sentence inferences, and MLP layers plays a critical role in this process. Based on this hypothesis, we develop 2 novel white-box jailbreak methods: a prompt-specific method and a prompt-general method. The prompt-specific method targets individual prompts and optimizes the attack on the fly, while the prompt-general method is pre-trained offline and can generalize to unseen harmful prompts. Our methods demonstrate robust performance across 7 popular open-source LLMs, size ranging from 2B to 72B. Furthermore, our study provides insights into vulnerabilities of instruction-tuned LLM's safety and deepens the understanding of the internal mechanisms of LLMs.
RAGEval: Scenario Specific RAG Evaluation Dataset Generation Framework
Aug 02, 2024



Retrieval-Augmented Generation (RAG) systems have demonstrated their advantages in alleviating the hallucination of Large Language Models (LLMs). Existing RAG benchmarks mainly focus on evaluating whether LLMs can correctly answer the general knowledge. However, they are unable to evaluate the effectiveness of the RAG system in dealing with the data from different vertical domains. This paper introduces RAGEval, a framework for automatically generating evaluation datasets to evaluate the knowledge usage ability of different LLMs in different scenarios. Specifically, RAGEval summarizes a schema from seed documents, applies the configurations to generate diverse documents, and constructs question-answering pairs according to both articles and configurations. We propose three novel metrics, Completeness, Hallucination, and Irrelevance, to carefully evaluate the responses generated by LLMs. By benchmarking RAG models in vertical domains, RAGEval has the ability to better evaluate the knowledge usage ability of LLMs, which avoids the confusion regarding the source of knowledge in answering question in existing QA datasets--whether it comes from parameterized memory or retrieval.
AutoMathText: Autonomous Data Selection with Language Models for Mathematical Texts
Feb 12, 2024To improve language models' proficiency in mathematical reasoning via continual pretraining, we introduce a novel strategy that leverages base language models for autonomous data selection. Departing from conventional supervised fine-tuning or trained classifiers with human-annotated data, our approach utilizes meta-prompted language models as zero-shot verifiers to autonomously evaluate and select high-quality mathematical content, and we release the curated open-source AutoMathText dataset encompassing over 200GB of data. To demonstrate the efficacy of our method, we continuously pretrained a 7B-parameter Mistral language model on the AutoMathText dataset, achieving substantial improvements in downstream performance on the MATH dataset with a token amount reduced by orders of magnitude compared to previous continuous pretraining works. Our method showcases a 2 times increase in pretraining token efficiency compared to baselines, underscoring the potential of our approach in enhancing models' mathematical reasoning capabilities. The AutoMathText dataset is available at https://huggingface.co/datasets/math-ai/AutoMathText. The code is available at https://github.com/yifanzhang-pro/AutoMathText.
Augmenting Math Word Problems via Iterative Question Composing
Jan 30, 2024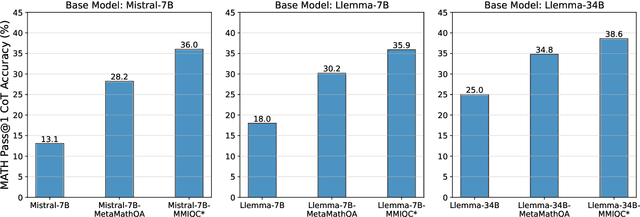



Despite the advancements in large language models (LLMs) for mathematical reasoning, solving competition-level math problems remains a significant challenge, especially for open-source LLMs without external tools. We introduce the MMIQC dataset, comprising a mixture of processed web data and synthetic question-response pairs, aimed at enhancing the mathematical reasoning capabilities of base language models. Models fine-tuned on MMIQC consistently surpass their counterparts in performance on the MATH benchmark across various model sizes. Notably, Qwen-72B-MMIQC achieves a 45.0% accuracy, exceeding the previous open-source state-of-the-art by 8.2% and outperforming the initial version GPT-4 released in 2023. Extensive evaluation results on Hungarian high school finals suggest that such improvement can generalize to unseen data. Our ablation study on MMIQC reveals that a large part of the improvement can be attributed to our novel augmentation method, Iterative Question Composing (IQC), which involves iteratively composing new questions from seed problems using an LLM and applying rejection sampling through another LLM. The MMIQC dataset is available on the HuggingFace hub at https://huggingface.co/datasets/Vivacem/MMIQC. Our code is available at https://github.com/iiis-ai/IterativeQuestionComposing.
Prompt Engineering Through the Lens of Optimal Control
Nov 03, 2023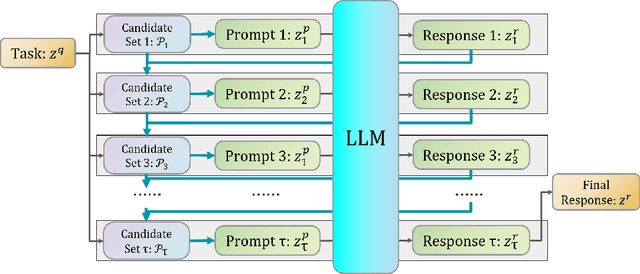
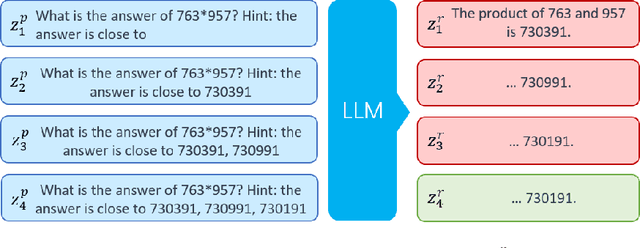
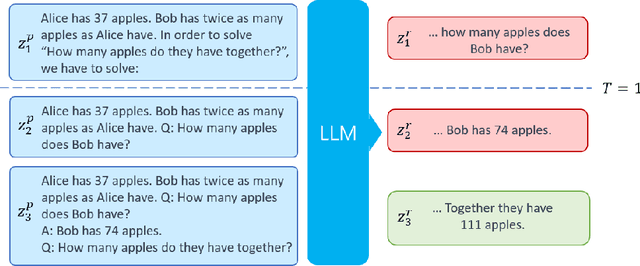
Prompt Engineering (PE) has emerged as a critical technique for guiding Large Language Models (LLMs) in solving intricate tasks. Its importance is highlighted by its potential to significantly enhance the efficiency and effectiveness of human-machine interaction. As tasks grow increasingly complex, recent advanced PE methods have extended beyond the limitations of single-round interactions to embrace multi-round interactions, which allows for a deeper and more nuanced engagement with LLMs. In this paper, we propose an optimal control framework tailored for multi-round interactions with LLMs. This framework provides a unified mathematical structure that not only systematizes the existing PE methods but also sets the stage for rigorous analytical improvements. Furthermore, we extend this framework to include PE via ensemble methods and multi-agent collaboration, thereby enlarging the scope of applicability. By adopting an optimal control perspective, we offer fresh insights into existing PE methods and highlight theoretical challenges that warrant future research. Besides, our work lays a foundation for the development of more effective and interpretable PE methods.
GSLB: The Graph Structure Learning Benchmark
Oct 08, 2023Graph Structure Learning (GSL) has recently garnered considerable attention due to its ability to optimize both the parameters of Graph Neural Networks (GNNs) and the computation graph structure simultaneously. Despite the proliferation of GSL methods developed in recent years, there is no standard experimental setting or fair comparison for performance evaluation, which creates a great obstacle to understanding the progress in this field. To fill this gap, we systematically analyze the performance of GSL in different scenarios and develop a comprehensive Graph Structure Learning Benchmark (GSLB) curated from 20 diverse graph datasets and 16 distinct GSL algorithms. Specifically, GSLB systematically investigates the characteristics of GSL in terms of three dimensions: effectiveness, robustness, and complexity. We comprehensively evaluate state-of-the-art GSL algorithms in node- and graph-level tasks, and analyze their performance in robust learning and model complexity. Further, to facilitate reproducible research, we have developed an easy-to-use library for training, evaluating, and visualizing different GSL methods. Empirical results of our extensive experiments demonstrate the ability of GSL and reveal its potential benefits on various downstream tasks, offering insights and opportunities for future research. The code of GSLB is available at: https://github.com/GSL-Benchmark/GSLB.
Won't Get Fooled Again: Answering Questions with False Premises
Jul 05, 2023



Pre-trained language models (PLMs) have shown unprecedented potential in various fields, especially as the backbones for question-answering (QA) systems. However, they tend to be easily deceived by tricky questions such as "How many eyes does the sun have?". Such frailties of PLMs often allude to the lack of knowledge within them. In this paper, we find that the PLMs already possess the knowledge required to rebut such questions, and the key is how to activate the knowledge. To systematize this observation, we investigate the PLMs' responses to one kind of tricky questions, i.e., the false premises questions (FPQs). We annotate a FalseQA dataset containing 2365 human-written FPQs, with the corresponding explanations for the false premises and the revised true premise questions. Using FalseQA, we discover that PLMs are capable of discriminating FPQs by fine-tuning on moderate numbers (e.g., 256) of examples. PLMs also generate reasonable explanations for the false premise, which serve as rebuttals. Further replaying a few general questions during training allows PLMs to excel on FPQs and general questions simultaneously. Our work suggests that once the rebuttal ability is stimulated, knowledge inside the PLMs can be effectively utilized to handle FPQs, which incentivizes the research on PLM-based QA systems.