 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Math Word Problems via Iterative Question Composing
Paper and Code
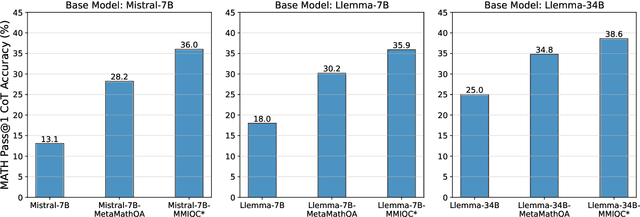



Despite the advancements in large language models (LLMs) for mathematical reasoning, solving competition-level math problems remains a significant challenge, especially for open-source LLMs without external tools. We introduce the MMIQC dataset, comprising a mixture of processed web data and synthetic question-response pairs, aimed at enhancing the mathematical reasoning capabilities of base language models. Models fine-tuned on MMIQC consistently surpass their counterparts in performance on the MATH benchmark across various model sizes. Notably, Qwen-72B-MMIQC achieves a 45.0% accuracy, exceeding the previous open-source state-of-the-art by 8.2% and outperforming the initial version GPT-4 released in 2023. Extensive evaluation results on Hungarian high school finals suggest that such improvement can generalize to unseen data. Our ablation study on MMIQC reveals that a large part of the improvement can be attributed to our novel augmentation method, Iterative Question Composing (IQC), which involves iteratively composing new questions from seed problems using an LLM and applying rejection sampling through another LLM. The MMIQC dataset is available on the HuggingFace hub at https://huggingface.co/datasets/Vivacem/MMIQC. Our code is available at https://github.com/iiis-ai/IterativeQuestionComposing.