 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Lack of Stable Internal Beliefs in LLMs
Mar 26, 2026Persona-driven large language models (LLMs) require consistent behavioral tendencies across interactions to simulate human-like personality traits, such as persistence or reliability. However, current LLMs often lack stable internal representations that anchor their responses over extended dialogues. This work explores whether LLMs can maintain "implicit consistency", defined as persistent adherence to an unstated goal in multi-turn interactions. We designed a 20-question-style riddle game paradigm where an LLM is tasked with secretly selecting a target and responding to users' guesses with "yes/no" answers. Through evaluations, we find that LLMs struggle to preserve latent consistency: their implicit "goals" shift across turns unless explicitly provided their selected target in context. These findings highlight critical limitations in the building of persona-driven LLMs and underscore the need for mechanisms that anchor implicit goals over time, which is a key to realistic personality modeling in interactive applications such as dialogue systems.
Group Representational Position Encoding
Dec 08, 2025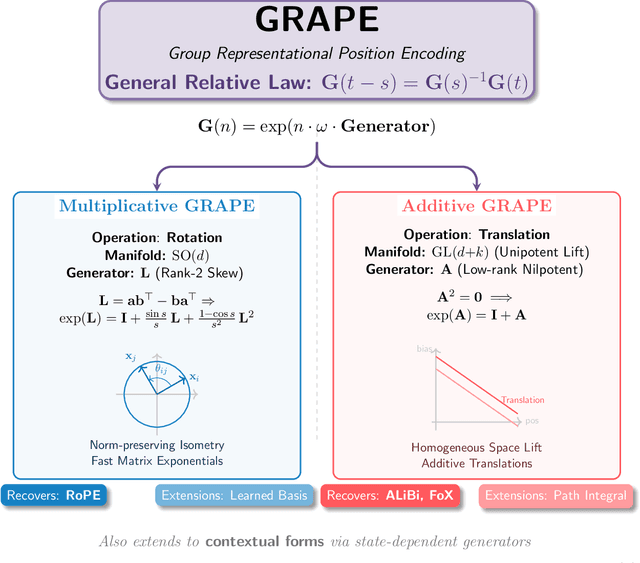
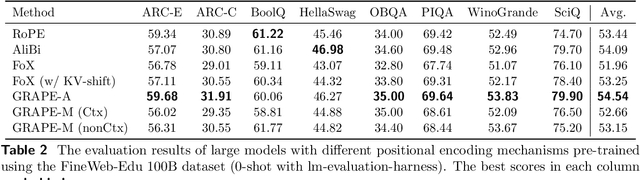
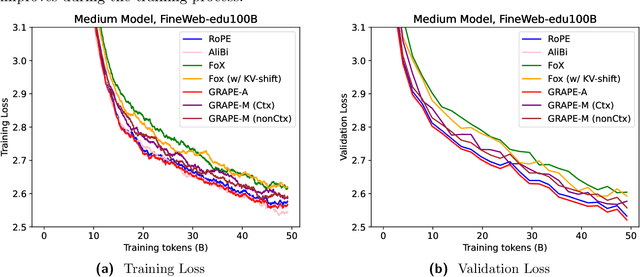

We present GRAPE (Group RepresentAtional Position Encoding), a unified framework for positional encoding based on group actions. GRAPE brings together two families of mechanisms: (i) multiplicative rotations (Multiplicative GRAPE) in $\mathrm{SO}(d)$ and (ii) additive logit biases (Additive GRAPE) arising from unipotent actions in the general linear group $\mathrm{GL}$. In Multiplicative GRAPE, a position $n \in \mathbb{Z}$ (or $t \in \mathbb{R}$) acts as $\mathbf{G}(n)=\exp(n\,ω\,\mathbf{L})$ with a rank-2 skew generator $\mathbf{L} \in \mathbb{R}^{d \times d}$, yielding a relative, compositional, norm-preserving map with a closed-form matrix exponential. RoPE is recovered exactly when the $d/2$ planes are the canonical coordinate pairs with log-uniform spectrum. Learned commuting subspaces and compact non-commuting mixtures strictly extend this geometry to capture cross-subspace feature coupling at $O(d)$ and $O(r d)$ cost per head, respectively. In Additive GRAPE, additive logits arise as rank-1 (or low-rank) unipotent actions, recovering ALiBi and the Forgetting Transformer (FoX) as exact special cases while preserving an exact relative law and streaming cacheability. Altogether, GRAPE supplies a principled design space for positional geometry in long-context models, subsuming RoPE and ALiBi as special cases. Project Page: https://github.com/model-architectures/GRAPE.
Clarifying Before Reasoning: A Coq Prover with Structural Context
Jul 03, 2025In this work, we investigate whether improving task clarity can enhance reasoning ability of large language models, focusing on theorem proving in Coq. We introduce a concept-level metric to evaluate task clarity and show that adding structured semantic context to the standard input used by modern LLMs, leads to a 1.85$\times$ improvement in clarity score (44.5\%~$\rightarrow$~82.3\%). Using the general-purpose model \texttt{DeepSeek-V3}, our approach leads to a 2.1$\times$ improvement in proof success (21.8\%~$\rightarrow$~45.8\%) and outperforms the previous state-of-the-art \texttt{Graph2Tac} (33.2\%). We evaluate this on 1,386 theorems randomly sampled from 15 standard Coq packages, following the same evaluation protocol as \texttt{Graph2Tac}. Furthermore, fine-tuning smaller models on our structured data can achieve even higher performance (48.6\%). Our method uses selective concept unfolding to enrich task descriptions, and employs a Planner--Executor architecture. These findings highlight the value of structured task representations in bridging the gap between understanding and reasoning.
Existing LLMs Are Not Self-Consistent For Simple Tasks
Jun 23, 2025Large Language Models (LLMs) have grown increasingly powerful, yet ensuring their decisions remain transparent and trustworthy requires self-consistency -- no contradictions in their internal reasoning. Our study reveals that even on simple tasks, such as comparing points on a line or a plane, or reasoning in a family tree, all smaller models are highly inconsistent, and even state-of-the-art models like DeepSeek-R1 and GPT-o4-mini are not fully self-consistent. To quantify and mitigate these inconsistencies, we introduce inconsistency metrics and propose two automated methods -- a graph-based and an energy-based approach. While these fixes provide partial improvements, they also highlight the complexity and importance of self-consistency in building more reliable and interpretable AI. The code and data are available at https://github.com/scorpio-nova/llm-self-consistency.
Tensor Product Attention Is All You Need
Jan 11, 2025



Scaling language models to handle longer input sequences typically necessitates large key-value (KV) caches, resulting in substantial memory overhead during inference. In this paper, we propose Tensor Product Attention (TPA), a novel attention mechanism that uses tensor decompositions to represent queries, keys, and values compactly, significantly shrinking KV cache size at inference time. By factorizing these representations into contextual low-rank components (contextual factorization) and seamlessly integrating with RoPE, TPA achieves improved model quality alongside memory efficiency. Based on TPA, we introduce the Tensor ProducT ATTenTion Transformer (T6), a new model architecture for sequence modeling. Through extensive empirical evaluation of language modeling tasks, we demonstrate that T6 exceeds the performance of standard Transformer baselines including MHA, MQA, GQA, and MLA across various metrics, including perplexity and a range of renowned evaluation benchmarks. Notably, TPAs memory efficiency enables the processing of significantly longer sequences under fixed resource constraints, addressing a critical scalability challenge in modern language models. The code is available at https://github.com/tensorgi/T6.
On the Diagram of Thought
Sep 16, 2024


We introduce Diagram of Thought (DoT), a framework that models iterative reasoning in large language models (LLMs) as the construction of a directed acyclic graph (DAG) within a single model. Unlike traditional approaches that represent reasoning as linear chains or trees, DoT organizes propositions, critiques, refinements, and verifications into a cohesive DAG structure, allowing the model to explore complex reasoning pathways while maintaining logical consistency. Each node in the diagram corresponds to a proposition that has been proposed, critiqued, refined, or verified, enabling the LLM to iteratively improve its reasoning through natural language feedback. By leveraging auto-regressive next-token prediction with role-specific tokens, DoT facilitates seamless transitions between proposing ideas and critically evaluating them, providing richer feedback than binary signals. Furthermore, we formalize the DoT framework using Topos Theory, providing a mathematical foundation that ensures logical consistency and soundness in the reasoning process. This approach enhances both the training and inference processes within a single LLM, eliminating the need for multiple models or external control mechanisms. DoT offers a conceptual framework for designing next-generation reasoning-specialized models, emphasizing training efficiency, robust reasoning capabilities, and theoretical grounding. The code is available at https://github.com/diagram-of-thought/diagram-of-thought.
AutoMathText: Autonomous Data Selection with Language Models for Mathematical Texts
Feb 12, 2024To improve language models' proficiency in mathematical reasoning via continual pretraining, we introduce a novel strategy that leverages base language models for autonomous data selection. Departing from conventional supervised fine-tuning or trained classifiers with human-annotated data, our approach utilizes meta-prompted language models as zero-shot verifiers to autonomously evaluate and select high-quality mathematical content, and we release the curated open-source AutoMathText dataset encompassing over 200GB of data. To demonstrate the efficacy of our method, we continuously pretrained a 7B-parameter Mistral language model on the AutoMathText dataset, achieving substantial improvements in downstream performance on the MATH dataset with a token amount reduced by orders of magnitude compared to previous continuous pretraining works. Our method showcases a 2 times increase in pretraining token efficiency compared to baselines, underscoring the potential of our approach in enhancing models' mathematical reasoning capabilities. The AutoMathText dataset is available at https://huggingface.co/datasets/math-ai/AutoMathText. The code is available at https://github.com/yifanzhang-pro/AutoMathText.
Augmenting Math Word Problems via Iterative Question Composing
Jan 30, 2024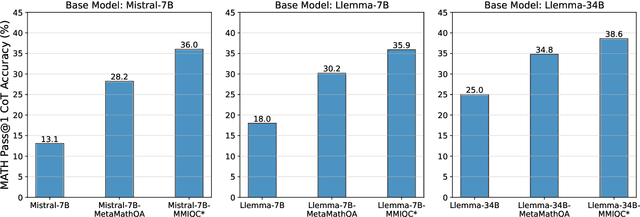



Despite the advancements in large language models (LLMs) for mathematical reasoning, solving competition-level math problems remains a significant challenge, especially for open-source LLMs without external tools. We introduce the MMIQC dataset, comprising a mixture of processed web data and synthetic question-response pairs, aimed at enhancing the mathematical reasoning capabilities of base language models. Models fine-tuned on MMIQC consistently surpass their counterparts in performance on the MATH benchmark across various model sizes. Notably, Qwen-72B-MMIQC achieves a 45.0% accuracy, exceeding the previous open-source state-of-the-art by 8.2% and outperforming the initial version GPT-4 released in 2023. Extensive evaluation results on Hungarian high school finals suggest that such improvement can generalize to unseen data. Our ablation study on MMIQC reveals that a large part of the improvement can be attributed to our novel augmentation method, Iterative Question Composing (IQC), which involves iteratively composing new questions from seed problems using an LLM and applying rejection sampling through another LLM. The MMIQC dataset is available on the HuggingFace hub at https://huggingface.co/datasets/Vivacem/MMIQC. Our code is available at https://github.com/iiis-ai/IterativeQuestionComposing.
Cumulative Reasoning with Large Language Models
Aug 25, 2023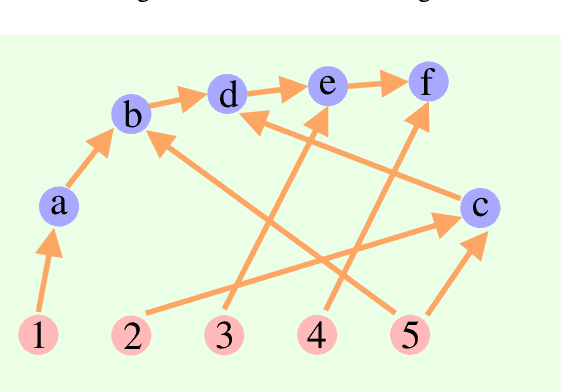
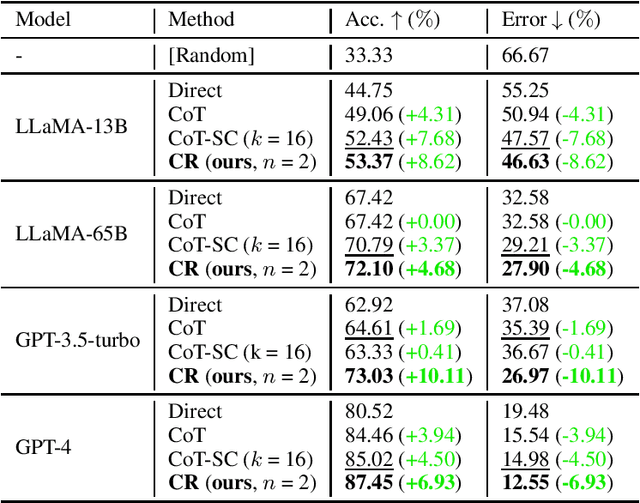
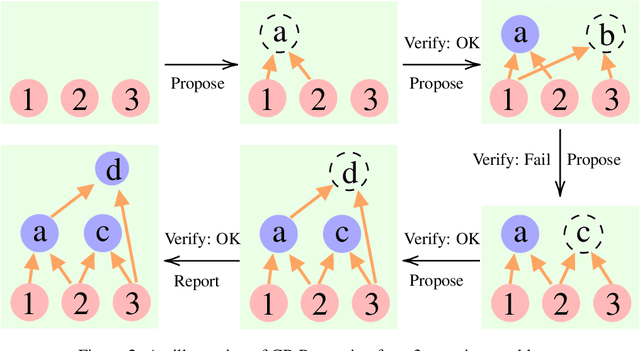
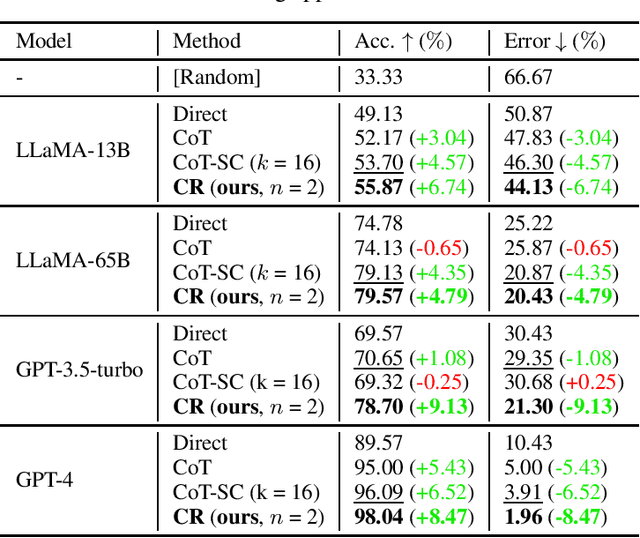
While language models are powerful and versatile, they often fail to address highly complex problems. This is because solving complex problems requires deliberate thinking, which has been only minimally guided during training. In this paper, we propose a new method called Cumulative Reasoning (CR), which employs language models in a cumulative and iterative manner to emulate human thought processes. By decomposing tasks into smaller components, CR streamlines the problem-solving process, rendering it both more manageable and effective. For logical inference tasks, CR consistently outperforms existing methods with an improvement up to 9.3%, and achieves the astonishing accuracy of 98.04% on the curated FOLIO wiki dataset. In the context of the Game of 24, CR achieves an accuracy of 98%, which signifies a substantial enhancement of 24% over the previous state-of-the-art method. Finally, on the MATH dataset, we establish new state-of-the-art results with 58.0% overall accuracy, surpassing the previous best approach by a margin of 4.2%, and achieving 43% relative improvement on the hardest level 5 problems (22.4% to 32.1%). Code is available at https://github.com/iiis-ai/cumulative-reasoning.
Relaxing the Feature Covariance Assumption: Time-Variant Bounds for Benign Overfitting in Linear Regression
Feb 12, 2022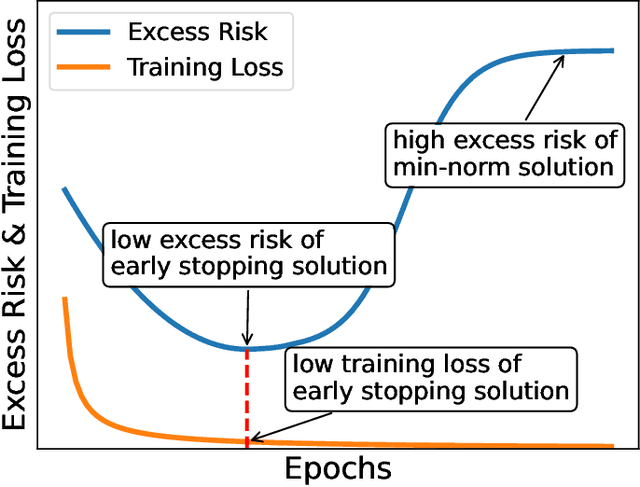
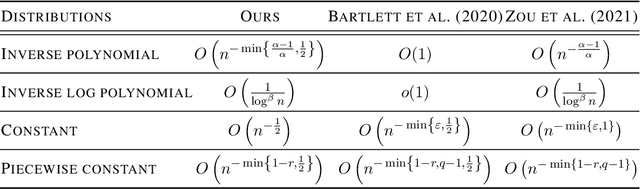
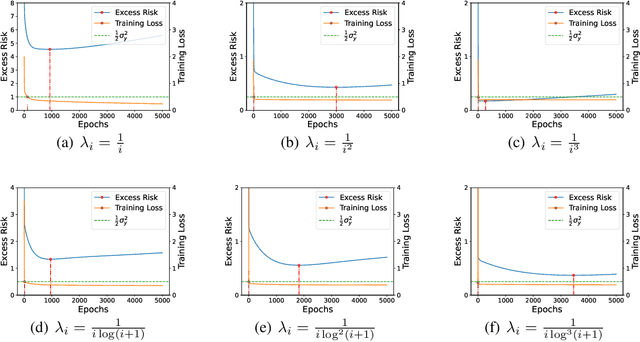
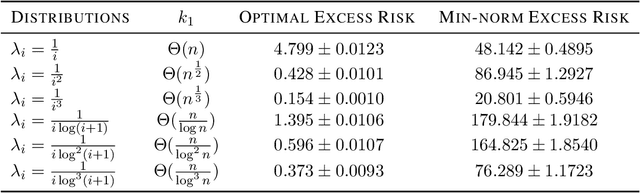
Benign overfitting demonstrates that overparameterized models can perform well on test data while fitting noisy training data. However, it only considers the final min-norm solution in linear regression, which ignores the algorithm information and the corresponding training procedure. In this paper, we generalize the idea of benign overfitting to the whole training trajectory instead of the min-norm solution and derive a time-variant bound based on the trajectory analysis. Starting from the time-variant bound, we further derive a time interval that suffices to guarantee a consistent generalization error for a given feature covariance. Unlike existing approaches, the newly proposed generalization bound is characterized by a time-variant effective dimension of feature covariance. By introducing the time factor, we relax the strict assumption on the feature covariance matrix required in previous benign overfitting under the regimes of overparameterized linear regression with gradient descent. This paper extends the scope of benign overfitting, and experiment results indicate that the proposed bound accords better with empirical evidence.