 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Lack of Stable Internal Beliefs in LLMs
Mar 26, 2026Persona-driven large language models (LLMs) require consistent behavioral tendencies across interactions to simulate human-like personality traits, such as persistence or reliability. However, current LLMs often lack stable internal representations that anchor their responses over extended dialogues. This work explores whether LLMs can maintain "implicit consistency", defined as persistent adherence to an unstated goal in multi-turn interactions. We designed a 20-question-style riddle game paradigm where an LLM is tasked with secretly selecting a target and responding to users' guesses with "yes/no" answers. Through evaluations, we find that LLMs struggle to preserve latent consistency: their implicit "goals" shift across turns unless explicitly provided their selected target in context. These findings highlight critical limitations in the building of persona-driven LLMs and underscore the need for mechanisms that anchor implicit goals over time, which is a key to realistic personality modeling in interactive applications such as dialogue systems.
Group Representational Position Encoding
Dec 08, 2025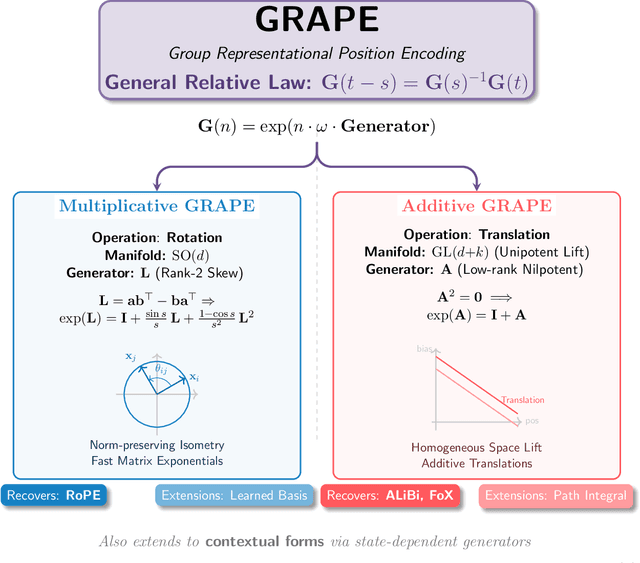
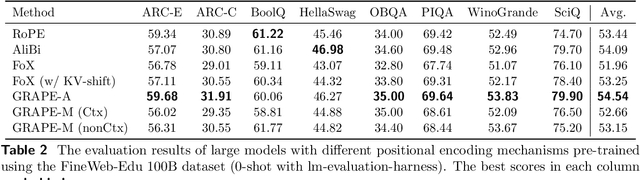
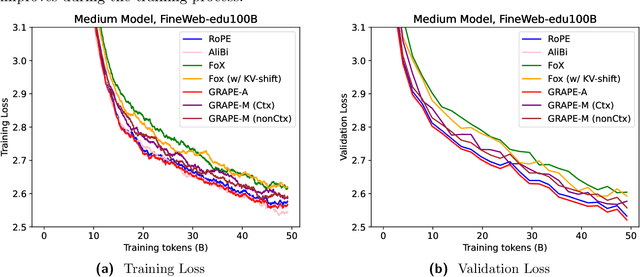

We present GRAPE (Group RepresentAtional Position Encoding), a unified framework for positional encoding based on group actions. GRAPE brings together two families of mechanisms: (i) multiplicative rotations (Multiplicative GRAPE) in $\mathrm{SO}(d)$ and (ii) additive logit biases (Additive GRAPE) arising from unipotent actions in the general linear group $\mathrm{GL}$. In Multiplicative GRAPE, a position $n \in \mathbb{Z}$ (or $t \in \mathbb{R}$) acts as $\mathbf{G}(n)=\exp(n\,ω\,\mathbf{L})$ with a rank-2 skew generator $\mathbf{L} \in \mathbb{R}^{d \times d}$, yielding a relative, compositional, norm-preserving map with a closed-form matrix exponential. RoPE is recovered exactly when the $d/2$ planes are the canonical coordinate pairs with log-uniform spectrum. Learned commuting subspaces and compact non-commuting mixtures strictly extend this geometry to capture cross-subspace feature coupling at $O(d)$ and $O(r d)$ cost per head, respectively. In Additive GRAPE, additive logits arise as rank-1 (or low-rank) unipotent actions, recovering ALiBi and the Forgetting Transformer (FoX) as exact special cases while preserving an exact relative law and streaming cacheability. Altogether, GRAPE supplies a principled design space for positional geometry in long-context models, subsuming RoPE and ALiBi as special cases. Project Page: https://github.com/model-architectures/GRAPE.
Clarifying Before Reasoning: A Coq Prover with Structural Context
Jul 03, 2025In this work, we investigate whether improving task clarity can enhance reasoning ability of large language models, focusing on theorem proving in Coq. We introduce a concept-level metric to evaluate task clarity and show that adding structured semantic context to the standard input used by modern LLMs, leads to a 1.85$\times$ improvement in clarity score (44.5\%~$\rightarrow$~82.3\%). Using the general-purpose model \texttt{DeepSeek-V3}, our approach leads to a 2.1$\times$ improvement in proof success (21.8\%~$\rightarrow$~45.8\%) and outperforms the previous state-of-the-art \texttt{Graph2Tac} (33.2\%). We evaluate this on 1,386 theorems randomly sampled from 15 standard Coq packages, following the same evaluation protocol as \texttt{Graph2Tac}. Furthermore, fine-tuning smaller models on our structured data can achieve even higher performance (48.6\%). Our method uses selective concept unfolding to enrich task descriptions, and employs a Planner--Executor architecture. These findings highlight the value of structured task representations in bridging the gap between understanding and reasoning.
Existing LLMs Are Not Self-Consistent For Simple Tasks
Jun 23, 2025Large Language Models (LLMs) have grown increasingly powerful, yet ensuring their decisions remain transparent and trustworthy requires self-consistency -- no contradictions in their internal reasoning. Our study reveals that even on simple tasks, such as comparing points on a line or a plane, or reasoning in a family tree, all smaller models are highly inconsistent, and even state-of-the-art models like DeepSeek-R1 and GPT-o4-mini are not fully self-consistent. To quantify and mitigate these inconsistencies, we introduce inconsistency metrics and propose two automated methods -- a graph-based and an energy-based approach. While these fixes provide partial improvements, they also highlight the complexity and importance of self-consistency in building more reliable and interpretable AI. The code and data are available at https://github.com/scorpio-nova/llm-self-consistency.
On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning
May 23, 2025Policy gradient algorithms have been successfully applied to enhance the reasoning capabilities of large language models (LLMs). Despite the widespread use of Kullback-Leibler (KL) regularization in policy gradient algorithms to stabilize training, the systematic exploration of how different KL divergence formulations can be estimated and integrated into surrogate loss functions for online reinforcement learning (RL) presents a nuanced and systematically explorable design space. In this paper, we propose regularized policy gradient (RPG), a systematic framework for deriving and analyzing KL-regularized policy gradient methods in the online RL setting. We derive policy gradients and corresponding surrogate loss functions for objectives regularized by both forward and reverse KL divergences, considering both normalized and unnormalized policy distributions. Furthermore, we present derivations for fully differentiable loss functions as well as REINFORCE-style gradient estimators, accommodating diverse algorithmic needs. We conduct extensive experiments on RL for LLM reasoning using these methods, showing improved or competitive results in terms of training stability and performance compared to strong baselines such as GRPO, REINFORCE++, and DAPO. The code is available at https://github.com/complex-reasoning/RPG.
Hierarchical Attention Generates Better Proofs
Apr 27, 2025



Large language models (LLMs) have shown promise in formal theorem proving, but their token-level processing often fails to capture the inherent hierarchical nature of mathematical proofs. We introduce \textbf{Hierarchical Attention}, a regularization method that aligns LLMs' attention mechanisms with mathematical reasoning structures. Our approach establishes a five-level hierarchy from foundational elements to high-level concepts, ensuring structured information flow in proof generation. Experiments demonstrate that our method improves proof success rates by 2.05\% on miniF2F and 1.69\% on ProofNet while reducing proof complexity by 23.81\% and 16.50\% respectively. The code is available at https://github.com/Car-pe/HAGBP.
Transformer-Enhanced Variational Autoencoder for Crystal Structure Prediction
Feb 13, 2025Crystal structure forms the foundation for understanding the physical and chemical properties of materials. Generative models have emerged as a new paradigm in crystal structure prediction(CSP), however, accurately capturing key characteristics of crystal structures, such as periodicity and symmetry, remains a significant challenge. In this paper, we propose a Transformer-Enhanced Variational Autoencoder for Crystal Structure Prediction (TransVAE-CSP), who learns the characteristic distribution space of stable materials, enabling both the reconstruction and generation of crystal structures. TransVAE-CSP integrates adaptive distance expansion with irreducible representation to effectively capture the periodicity and symmetry of crystal structures, and the encoder is a transformer network based on an equivariant dot product attention mechanism. Experimental results on the carbon_24, perov_5, and mp_20 datasets demonstrate that TransVAE-CSP outperforms existing methods in structure reconstruction and generation tasks under various modeling metrics, offering a powerful tool for crystal structure design and optimization.
CrySPAI: A new Crystal Structure Prediction Software Based on Artificial Intelligence
Jan 27, 2025



Crystal structure predictions based on the combination of first-principles calculations and machine learning have achieved significant success in materials science. However, most of these approaches are limited to predicting specific systems, which hinders their application to unknown or unexplored domains. In this paper, we present CrySPAI, a crystal structure prediction package developed using artificial intelligence (AI) to predict energetically stable crystal structures of inorganic materials given their chemical compositions. The software consists of three key modules, an evolutionary optimization algorithm (EOA) that searches for all possible crystal structure configurations, density functional theory (DFT) that provides the accurate energy values for these structures, and a deep neural network (DNN) that learns the relationship between crystal structures and their corresponding energies. To optimize the process across these modules, a distributed framework is implemented to parallelize tasks, and an automated workflow has been integrated into CrySPAI for seamless execution. This paper reports the development and implementation of AI AI-based CrySPAI Crystal Prediction Software tool and its unique features.
Tensor Product Attention Is All You Need
Jan 11, 2025



Scaling language models to handle longer input sequences typically necessitates large key-value (KV) caches, resulting in substantial memory overhead during inference. In this paper, we propose Tensor Product Attention (TPA), a novel attention mechanism that uses tensor decompositions to represent queries, keys, and values compactly, significantly shrinking KV cache size at inference time. By factorizing these representations into contextual low-rank components (contextual factorization) and seamlessly integrating with RoPE, TPA achieves improved model quality alongside memory efficiency. Based on TPA, we introduce the Tensor ProducT ATTenTion Transformer (T6), a new model architecture for sequence modeling. Through extensive empirical evaluation of language modeling tasks, we demonstrate that T6 exceeds the performance of standard Transformer baselines including MHA, MQA, GQA, and MLA across various metrics, including perplexity and a range of renowned evaluation benchmarks. Notably, TPAs memory efficiency enables the processing of significantly longer sequences under fixed resource constraints, addressing a critical scalability challenge in modern language models. The code is available at https://github.com/tensorgi/T6.
On the Diagram of Thought
Sep 16, 2024


We introduce Diagram of Thought (DoT), a framework that models iterative reasoning in large language models (LLMs) as the construction of a directed acyclic graph (DAG) within a single model. Unlike traditional approaches that represent reasoning as linear chains or trees, DoT organizes propositions, critiques, refinements, and verifications into a cohesive DAG structure, allowing the model to explore complex reasoning pathways while maintaining logical consistency. Each node in the diagram corresponds to a proposition that has been proposed, critiqued, refined, or verified, enabling the LLM to iteratively improve its reasoning through natural language feedback. By leveraging auto-regressive next-token prediction with role-specific tokens, DoT facilitates seamless transitions between proposing ideas and critically evaluating them, providing richer feedback than binary signals. Furthermore, we formalize the DoT framework using Topos Theory, providing a mathematical foundation that ensures logical consistency and soundness in the reasoning process. This approach enhances both the training and inference processes within a single LLM, eliminating the need for multiple models or external control mechanisms. DoT offers a conceptual framework for designing next-generation reasoning-specialized models, emphasizing training efficiency, robust reasoning capabilities, and theoretical grounding. The code is available at https://github.com/diagram-of-thought/diagram-of-thought.