 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
Xiaomi MiMo-VL-Miloco Technical Report
Dec 22, 2025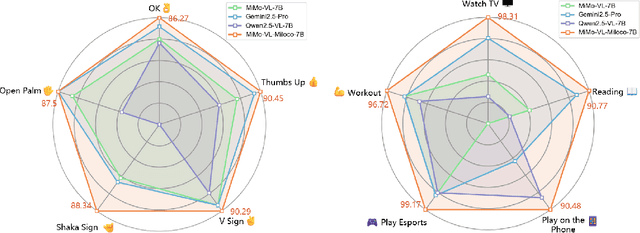
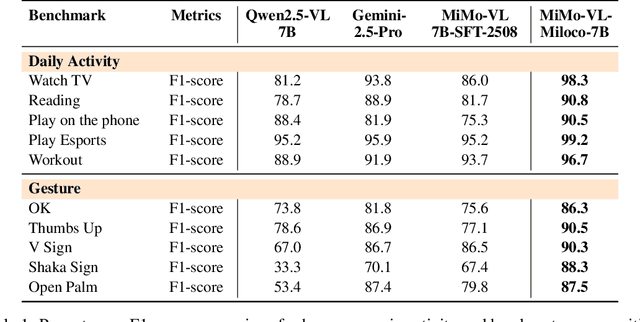

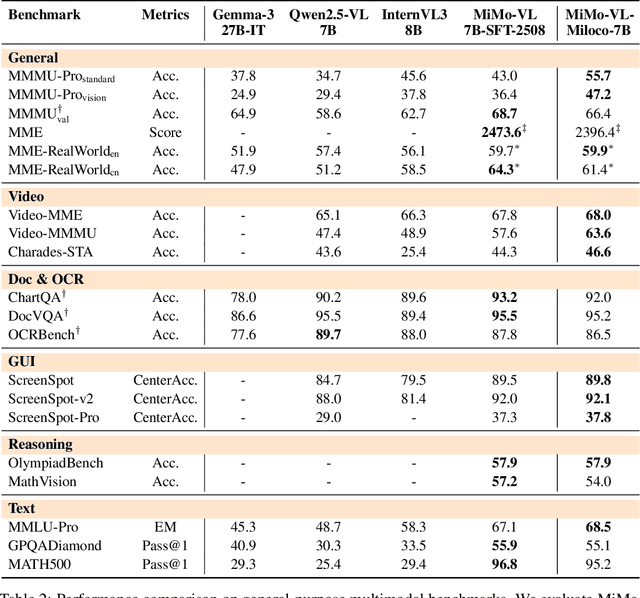
We open-source MiMo-VL-Miloco-7B and its quantized variant MiMo-VL-Miloco-7B-GGUF, a pair of home-centric vision-language models that achieve strong performance on both home-scenario understanding and general multimodal reasoning. Built on the MiMo-VL-7B backbone, MiMo-VL-Miloco-7B is specialized for smart-home environments, attaining leading F1 scores on gesture recognition and common home-scenario understanding, while also delivering consistent gains across video benchmarks such as Video-MME, Video-MMMU, and Charades-STA, as well as language understanding benchmarks including MMMU-Pro and MMLU-Pro. In our experiments, MiMo-VL-Miloco-7B outperforms strong closed-source and open-source baselines on home-scenario understanding and several multimodal reasoning benchmarks. To balance specialization and generality, we design a two-stage training pipeline that combines supervised fine-tuning with reinforcement learning based on Group Relative Policy Optimization, leveraging efficient multi-domain data. We further incorporate chain-of-thought supervision and token-budget-aware reasoning, enabling the model to learn knowledge in a data-efficient manner while also performing reasoning efficiently. Our analysis shows that targeted home-scenario training not only enhances activity and gesture understanding, but also improves text-only reasoning with only modest trade-offs on document-centric tasks. Model checkpoints, quantized GGUF weights, and our home-scenario evaluation toolkit are publicly available at https://github.com/XiaoMi/xiaomi-mimo-vl-miloco to support research and deployment in real-world smart-home applications.
Existing LLMs Are Not Self-Consistent For Simple Tasks
Jun 23, 2025Large Language Models (LLMs) have grown increasingly powerful, yet ensuring their decisions remain transparent and trustworthy requires self-consistency -- no contradictions in their internal reasoning. Our study reveals that even on simple tasks, such as comparing points on a line or a plane, or reasoning in a family tree, all smaller models are highly inconsistent, and even state-of-the-art models like DeepSeek-R1 and GPT-o4-mini are not fully self-consistent. To quantify and mitigate these inconsistencies, we introduce inconsistency metrics and propose two automated methods -- a graph-based and an energy-based approach. While these fixes provide partial improvements, they also highlight the complexity and importance of self-consistency in building more reliable and interpretable AI. The code and data are available at https://github.com/scorpio-nova/llm-self-consistency.
MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to Posttraining
May 12, 2025We present MiMo-7B, a large language model born for reasoning tasks, with optimization across both pre-training and post-training stages. During pre-training, we enhance the data preprocessing pipeline and employ a three-stage data mixing strategy to strengthen the base model's reasoning potential. MiMo-7B-Base is pre-trained on 25 trillion tokens, with additional Multi-Token Prediction objective for enhanced performance and accelerated inference speed. During post-training, we curate a dataset of 130K verifiable mathematics and programming problems for reinforcement learning, integrating a test-difficulty-driven code-reward scheme to alleviate sparse-reward issues and employing strategic data resampling to stabilize training. Extensive evaluations show that MiMo-7B-Base possesses exceptional reasoning potential, outperforming even much larger 32B models. The final RL-tuned model, MiMo-7B-RL, achieves superior performance on mathematics, code and general reasoning tasks, surpassing the performance of OpenAI o1-mini. The model checkpoints are available at https://github.com/xiaomimimo/MiMo.
CatCode: A Comprehensive Evaluation Framework for LLMs On the Mixture of Code and Text
Mar 04, 2024Large language models (LLMs) such as ChatGPT are increasingly proficient in understanding and generating a mixture of code and text. Evaluation based on such $\textit{mixture}$ can lead to a more comprehensive understanding of the models' abilities in solving coding problems. However, in this context, current evaluation methods are either limited in task coverage or lack standardization. To address this issue, we propose using category theory as a framework for evaluation. Specifically, morphisms within a code category can represent code debugging and transformation, functors between two categories represent code translation, and functors between a code category and a natural language category represent code generation, explanation, and reproduction. We present an automatic evaluation framework called $\textbf{CatCode}$ ($\textbf{Cat}$egory $\textbf{Code}$) that can comprehensively assess the coding abilities of LLMs, including ChatGPT, Text-Davinci, and CodeGeeX.
Variational Latent-State GPT for Semi-supervised Task-Oriented Dialog Systems
Sep 09, 2021
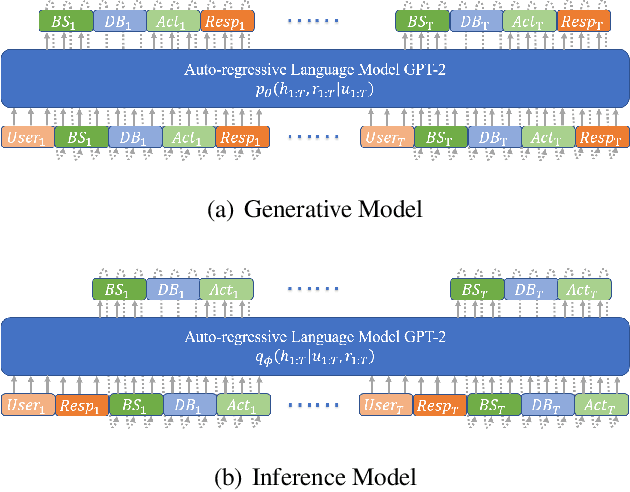

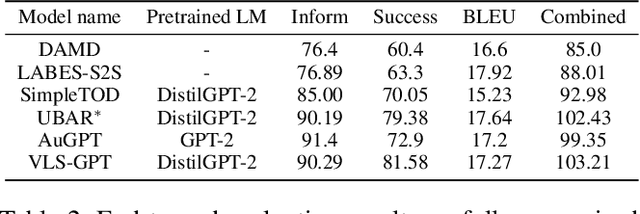
Recently, two approaches, fine-tuning large pre-trained language models and variational training, have attracted significant interests, separately, for semi-supervised end-to-end task-oriented dialog (TOD) systems. In this paper, we propose Variational Latent-State GPT model (VLS-GPT), which is the first to combine the strengths of the two approaches. Among many options of models, we propose the generative model and the inference model for variational learning of the end-to-end TOD system, both as auto-regressive language models based on GPT-2, which can be further trained over a mix of labeled and unlabeled dialog data in a semi-supervised manner. We develop the strategy of sampling-then-forward-computation, which successfully overcomes the memory explosion issue of using GPT in variational learning and speeds up training. Semi-supervised TOD experiments are conducted on two benchmark multi-domain datasets of different languages - MultiWOZ2.1 and CrossWOZ. VLS-GPT is shown to significantly outperform both supervised-only and semi-supervised baselines.
PsyQA: A Chinese Dataset for Generating Long Counseling Text for Mental Health Support
Jun 03, 2021
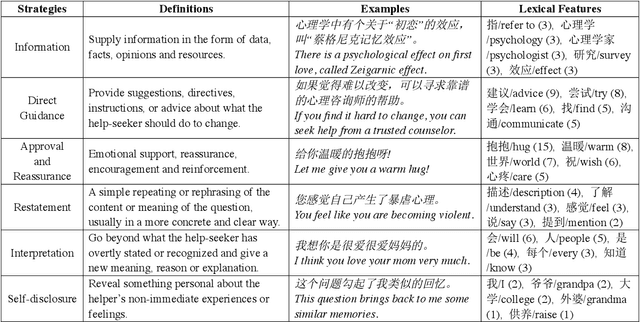
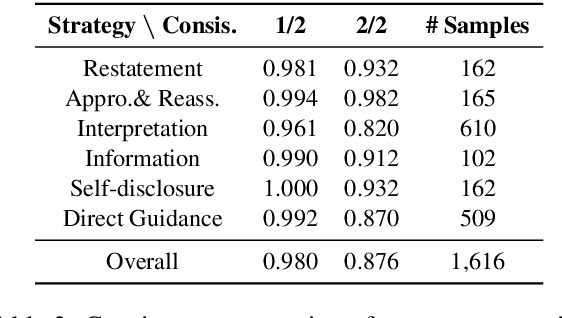
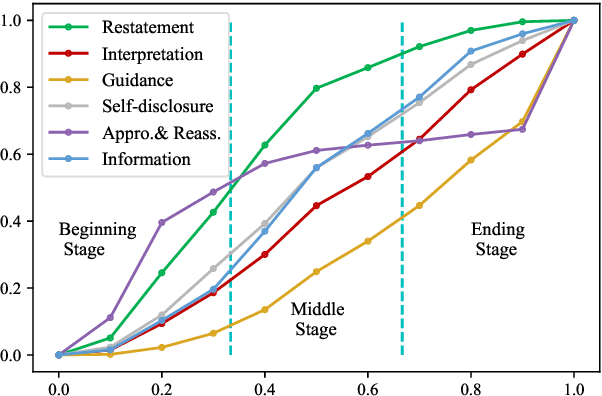
Great research interests have been attracted to devise AI services that are able to provide mental health support. However, the lack of corpora is a main obstacle to this research, particularly in Chinese language. In this paper, we propose PsyQA, a Chinese dataset of psychological health support in the form of question and answer pair. PsyQA is crawled from a Chinese mental health service platform, and contains 22K questions and 56K long and well-structured answers. Based on the psychological counseling theories, we annotate a portion of answer texts with typical strategies for providing support, and further present in-depth analysis of both lexical features and strategy patterns in the counseling answers. We also evaluate the performance of generating counseling answers with the generative pretrained models. Results show that utilizing strategies enhances the fluency and helpfulness of generated answers, but there is still a large space for future research.