 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaperBanana: Automating Academic Illustration for AI Scientists
Jan 30, 2026Despite rapid advances in autonomous AI scientists powered by language models, generating publication-ready illustrations remains a labor-intensive bottleneck in the research workflow. To lift this burden, we introduce PaperBanana, an agentic framework for automated generation of publication-ready academic illustrations. Powered by state-of-the-art VLMs and image generation models, PaperBanana orchestrates specialized agents to retrieve references, plan content and style, render images, and iteratively refine via self-critique. To rigorously evaluate our framework, we introduce PaperBananaBench, comprising 292 test cases for methodology diagrams curated from NeurIPS 2025 publications, covering diverse research domains and illustration styles. Comprehensive experiments demonstrate that PaperBanana consistently outperforms leading baselines in faithfulness, conciseness, readability, and aesthetics. We further show that our method effectively extends to the generation of high-quality statistical plots. Collectively, PaperBanana paves the way for the automated generation of publication-ready illustrations.
SonicBench: Dissecting the Physical Perception Bottleneck in Large Audio Language Models
Jan 16, 2026Large Audio Language Models (LALMs) excel at semantic and paralinguistic tasks, yet their ability to perceive the fundamental physical attributes of audio such as pitch, loudness, and spatial location remains under-explored. To bridge this gap, we introduce SonicBench, a psychophysically grounded benchmark that systematically evaluates 12 core physical attributes across five perceptual dimensions. Unlike previous datasets, SonicBench uses a controllable generation toolbox to construct stimuli for two complementary paradigms: recognition (absolute judgment) and comparison (relative judgment). This design allows us to probe not only sensory precision but also relational reasoning capabilities, a domain where humans typically exhibit greater proficiency. Our evaluation reveals a substantial deficiency in LALMs' foundational auditory understanding; most models perform near random guessing and, contrary to human patterns, fail to show the expected advantage on comparison tasks. Furthermore, explicit reasoning yields minimal gains. However, our linear probing analysis demonstrates crucially that frozen audio encoders do successfully capture these physical cues (accuracy at least 60%), suggesting that the primary bottleneck lies in the alignment and decoding stages, where models fail to leverage the sensory signals they have already captured.
MiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
DocLens : A Tool-Augmented Multi-Agent Framework for Long Visual Document Understanding
Nov 14, 2025Comprehending long visual documents, where information is distributed across extensive pages of text and visual elements, is a critical but challenging task for modern Vision-Language Models (VLMs). Existing approaches falter on a fundamental challenge: evidence localization. They struggle to retrieve relevant pages and overlook fine-grained details within visual elements, leading to limited performance and model hallucination. To address this, we propose DocLens, a tool-augmented multi-agent framework that effectively ``zooms in'' on evidence like a lens. It first navigates from the full document to specific visual elements on relevant pages, then employs a sampling-adjudication mechanism to generate a single, reliable answer. Paired with Gemini-2.5-Pro, DocLens achieves state-of-the-art performance on MMLongBench-Doc and FinRAGBench-V, surpassing even human experts. The framework's superiority is particularly evident on vision-centric and unanswerable queries, demonstrating the power of its enhanced localization capabilities.
PricingLogic: Evaluating LLMs Reasoning on Complex Tourism Pricing Tasks
Oct 14, 2025
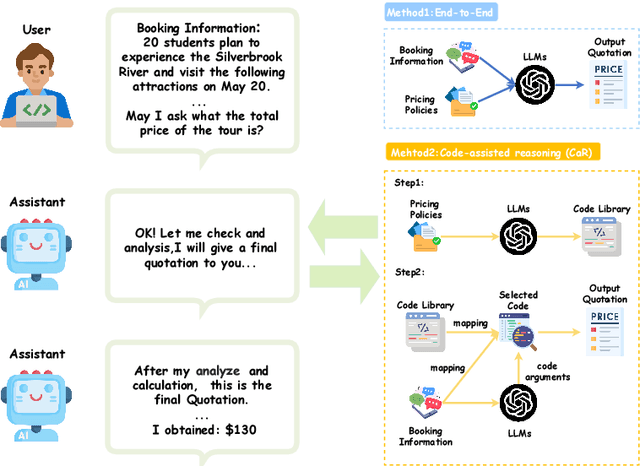


We present PricingLogic, the first benchmark that probes whether Large Language Models(LLMs) can reliably automate tourism-related prices when multiple, overlapping fare rules apply. Travel agencies are eager to offload this error-prone task onto AI systems; however, deploying LLMs without verified reliability could result in significant financial losses and erode customer trust. PricingLogic comprises 300 natural-language questions based on booking requests derived from 42 real-world pricing policies, spanning two levels of difficulty: (i) basic customer-type pricing and (ii)bundled-tour calculations involving interacting discounts. Evaluations of a line of LLMs reveal a steep performance drop on the harder tier,exposing systematic failures in rule interpretation and arithmetic reasoning.These results highlight that, despite their general capabilities, today's LLMs remain unreliable in revenue-critical applications without further safeguards or domain adaptation. Our code and dataset are available at https://github.com/EIT-NLP/PricingLogic.
MultiJustice: A Chinese Dataset for Multi-Party, Multi-Charge Legal Prediction
Jul 09, 2025Legal judgment prediction offers a compelling method to aid legal practitioners and researchers. However, the research question remains relatively under-explored: Should multiple defendants and charges be treated separately in LJP? To address this, we introduce a new dataset namely multi-person multi-charge prediction (MPMCP), and seek the answer by evaluating the performance of several prevailing legal large language models (LLMs) on four practical legal judgment scenarios: (S1) single defendant with a single charge, (S2) single defendant with multiple charges, (S3) multiple defendants with a single charge, and (S4) multiple defendants with multiple charges. We evaluate the dataset across two LJP tasks, i.e., charge prediction and penalty term prediction. We have conducted extensive experiments and found that the scenario involving multiple defendants and multiple charges (S4) poses the greatest challenges, followed by S2, S3, and S1. The impact varies significantly depending on the model. For example, in S4 compared to S1, InternLM2 achieves approximately 4.5% lower F1-score and 2.8% higher LogD, while Lawformer demonstrates around 19.7% lower F1-score and 19.0% higher LogD. Our dataset and code are available at https://github.com/lololo-xiao/MultiJustice-MPMCP.
A Survey on Latent Reasoning
Jul 08, 2025



Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, especially when guided by explicit chain-of-thought (CoT) reasoning that verbalizes intermediate steps. While CoT improves both interpretability and accuracy, its dependence on natural language reasoning limits the model's expressive bandwidth. Latent reasoning tackles this bottleneck by performing multi-step inference entirely in the model's continuous hidden state, eliminating token-level supervision. To advance latent reasoning research, this survey provides a comprehensive overview of the emerging field of latent reasoning. We begin by examining the foundational role of neural network layers as the computational substrate for reasoning, highlighting how hierarchical representations support complex transformations. Next, we explore diverse latent reasoning methodologies, including activation-based recurrence, hidden state propagation, and fine-tuning strategies that compress or internalize explicit reasoning traces. Finally, we discuss advanced paradigms such as infinite-depth latent reasoning via masked diffusion models, which enable globally consistent and reversible reasoning processes. By unifying these perspectives, we aim to clarify the conceptual landscape of latent reasoning and chart future directions for research at the frontier of LLM cognition. An associated GitHub repository collecting the latest papers and repos is available at: https://github.com/multimodal-art-projection/LatentCoT-Horizon/.
PLD: A Choice-Theoretic List-Wise Knowledge Distillation
Jun 14, 2025Knowledge distillation is a model compression technique in which a compact "student" network is trained to replicate the predictive behavior of a larger "teacher" network. In logit-based knowledge distillation it has become the de facto approach to augment cross-entropy with a distillation term. Typically this term is either a KL divergence-matching marginal probabilities or a correlation-based loss capturing intra- and inter-class relationships but in every case it sits as an add-on to cross-entropy with its own weight that must be carefully tuned. In this paper we adopt a choice-theoretic perspective and recast knowledge distillation under the Plackett-Luce model by interpreting teacher logits as "worth" scores. We introduce Plackett-Luce Distillation (PLD), a weighted list-wise ranking loss in which the teacher model transfers knowledge of its full ranking of classes, weighting each ranked choice by its own confidence. PLD directly optimizes a single teacher-optimal ranking of the true label first, followed by the remaining classes in descending teacher confidence, yielding a convex, translation-invariant surrogate that subsumes weighted cross-entropy. Empirically on standard image classification benchmarks, PLD improves Top-1 accuracy by an average of +0.42% over DIST (arXiv:2205.10536) and +1.04% over KD (arXiv:1503.02531) in homogeneous settings and by +0.48% and +1.09% over DIST and KD, respectively, in heterogeneous settings.
Language models can learn implicit multi-hop reasoning, but only if they have lots of training data
May 23, 2025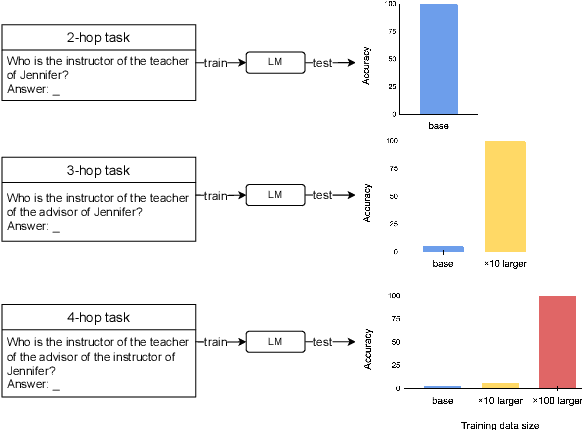
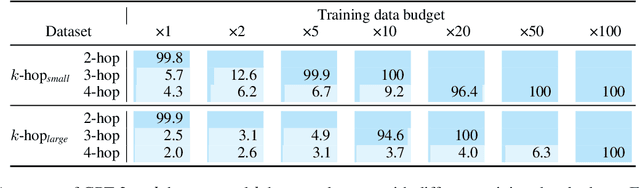
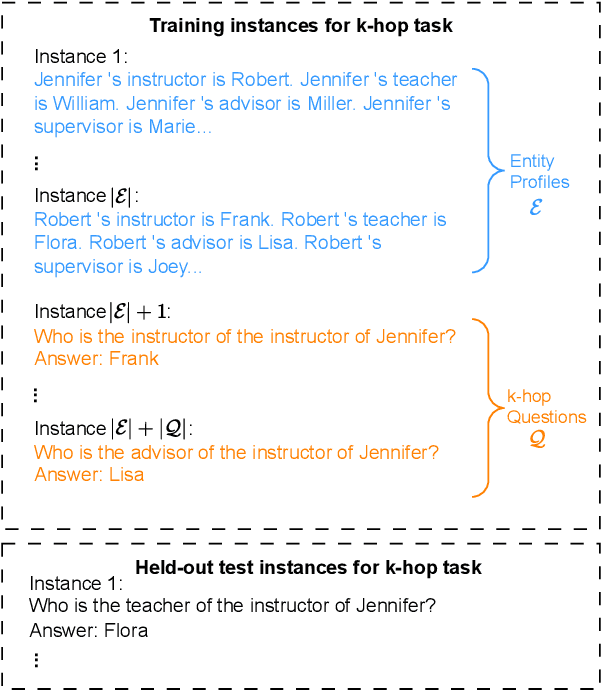
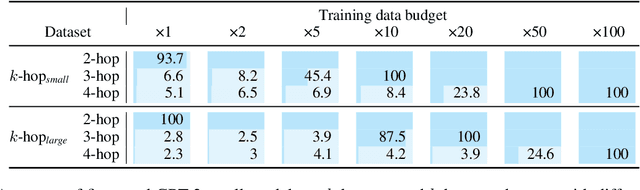
Implicit reasoning is the ability of a language model to solve multi-hop reasoning tasks in a single forward pass, without chain of thought. We investigate this capability using GPT2-style language models trained from scratch on controlled $k$-hop reasoning datasets ($k = 2, 3, 4$). We show that while such models can indeed learn implicit $k$-hop reasoning, the required training data grows exponentially in $k$, and the required number of transformer layers grows linearly in $k$. We offer a theoretical explanation for why this depth growth is necessary. We further find that the data requirement can be mitigated, but not eliminated, through curriculum learning.