 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Parameter Arithmetic: Sparse Complementary Fusion for Distribution-Aware Model Merging
Feb 12, 2026Model merging has emerged as a promising paradigm for composing the capabilities of large language models by directly operating in weight space, enabling the integration of specialized models without costly retraining. However, existing merging methods largely rely on parameter-space heuristics, which often introduce severe interference, leading to degraded generalization and unstable generation behaviors such as repetition and incoherent outputs. In this work, we propose Sparse Complementary Fusion with reverse KL (SCF-RKL), a novel model merging framework that explicitly controls functional interference through sparse, distribution-aware updates. Instead of assuming linear additivity in parameter space, SCF-RKL measures the functional divergence between models using reverse Kullback-Leibler divergence and selectively incorporates complementary parameters. This mode-seeking, sparsity-inducing design effectively preserves stable representations while integrating new capabilities. We evaluate SCF-RKL across a wide range of model scales and architectures, covering both reasoning-focused and instruction-tuned models. Extensive experiments on 24 benchmarks spanning advanced reasoning, general reasoning and knowledge, instruction following, and safety demonstrate, vision classification that SCF-RKL consistently outperforms existing model merging methods while maintaining strong generalization and generation stability.
Evaluation is All You Need: Strategic Overclaiming of LLM Reasoning Capabilities Through Evaluation Design
Jun 05, 2025Reasoning models represented by the Deepseek-R1-Distill series have been widely adopted by the open-source community due to their strong performance in mathematics, science, programming, and other domains. However, our study reveals that their benchmark evaluation results are subject to significant fluctuations caused by various factors. Subtle differences in evaluation conditions can lead to substantial variations in results. Similar phenomena are observed in other open-source inference models fine-tuned based on the Deepseek-R1-Distill series, as well as in the QwQ-32B model, making their claimed performance improvements difficult to reproduce reliably. Therefore, we advocate for the establishment of a more rigorous paradigm for model performance evaluation and present our empirical assessments of the Deepseek-R1-Distill series models.
TinyR1-32B-Preview: Boosting Accuracy with Branch-Merge Distillation
Mar 06, 2025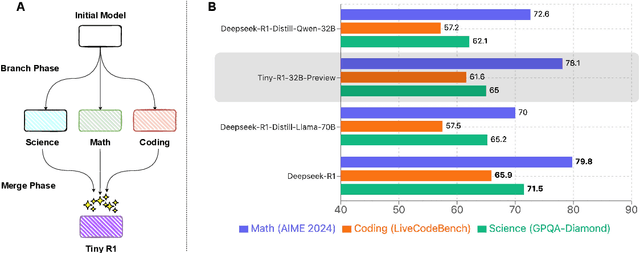
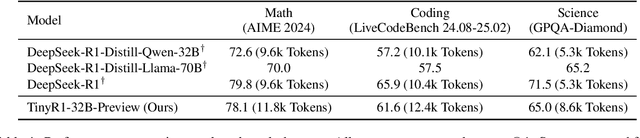
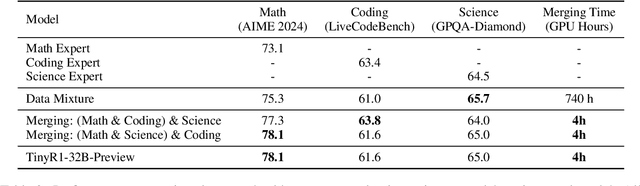
The challenge of reducing the size of Large Language Models (LLMs) while maintaining their performance has gained significant attention. However, existing methods, such as model distillation and transfer learning, often fail to achieve high accuracy. To address this limitation, we introduce the Branch-Merge distillation approach, which enhances model compression through two phases: (1) the Branch Phase, where knowledge from a large teacher model is \textit{selectively distilled} into specialized student models via domain-specific supervised fine-tuning (SFT); And (2) the Merge Phase, where these student models are merged to enable cross-domain knowledge transfer and improve generalization. We validate our distillation approach using DeepSeek-R1 as the teacher and DeepSeek-R1-Distill-Qwen-32B as the student. The resulting merged model, TinyR1-32B-Preview, outperforms its counterpart DeepSeek-R1-Distill-Qwen-32B across multiple benchmarks, including Mathematics (+5.5 points), Coding (+4.4 points) and Science (+2.9 points), while achieving near-equal performance to DeepSeek-R1 on AIME 2024. The Branch-Merge distillation approach provides a scalable solution for creating smaller, high-performing LLMs with reduced computational cost and time.
Chain-of-Thought Matters: Improving Long-Context Language Models with Reasoning Path Supervision
Feb 28, 2025



Recent advances in Large Language Models (LLMs) have highlighted the challenge of handling long-context tasks, where models need to reason over extensive input contexts to aggregate target information. While Chain-of-Thought (CoT) prompting has shown promise for multi-step reasoning, its effectiveness for long-context scenarios remains underexplored. Through systematic investigation across diverse tasks, we demonstrate that CoT's benefits generalize across most long-context scenarios and amplify with increasing context length. Motivated by this critical observation, we propose LongRePS, a process-supervised framework that teaches models to generate high-quality reasoning paths for enhanced long-context performance. Our framework incorporates a self-sampling mechanism to bootstrap reasoning paths and a novel quality assessment protocol specifically designed for long-context scenarios. Experimental results on various long-context benchmarks demonstrate the effectiveness of our approach, achieving significant improvements over outcome supervision baselines on both in-domain tasks (+13.6/+3.8 points for LLaMA/Qwen on MuSiQue) and cross-domain generalization (+9.3/+8.1 points on average across diverse QA tasks). Our code, data and trained models are made public to facilitate future research.
LongAttn: Selecting Long-context Training Data via Token-level Attention
Feb 24, 2025



With the development of large language models (LLMs), there has been an increasing need for significant advancements in handling long contexts. To enhance long-context capabilities, constructing high-quality training data with long-range dependencies is crucial. Existing methods to select long-context data often rely on sentence-level analysis, which can be greatly optimized in both performance and efficiency. In this paper, we propose a novel token-level framework, LongAttn, which leverages the self-attention mechanism of LLMs to measure the long-range dependencies for the data. By calculating token-level dependency strength and distribution uniformity of token scores, LongAttn effectively quantifies long-range dependencies, enabling more accurate and efficient data selection. We filter LongABC-32K from open-source long-context datasets (ArXiv, Book, and Code). Through our comprehensive experiments, LongAttn has demonstrated its excellent effectiveness, scalability, and efficiency. To facilitate future research in long-context data, we released our code and the high-quality long-context training data LongABC-32K.
Stress Testing Generalization: How Minor Modifications Undermine Large Language Model Performance
Feb 18, 2025This paper investigates the fragility of Large Language Models (LLMs) in generalizing to novel inputs, specifically focusing on minor perturbations in well-established benchmarks (e.g., slight changes in question format or distractor length). Despite high benchmark scores, LLMs exhibit significant accuracy drops and unexpected biases (e.g., preference for longer distractors) when faced with these minor but content-preserving modifications. For example, Qwen 2.5 1.5B's MMLU score rises from 60 to 89 and drops from 89 to 36 when option lengths are changed without altering the question. Even GPT-4 experiences a 25-point accuracy loss when question types are changed, with a 6-point drop across all three modification categories. These analyses suggest that LLMs rely heavily on superficial cues rather than forming robust, abstract representations that generalize across formats, lexical variations, and irrelevant content shifts. This work aligns with the ACL 2025 theme track on the Generalization of NLP models, proposing a "Generalization Stress Test" to assess performance shifts under controlled perturbations. The study calls for reevaluating benchmarks and developing more reliable evaluation methodologies to capture LLM generalization abilities better.
When to Trust Aggregated Gradients: Addressing Negative Client Sampling in Federated Learning
Jan 25, 2023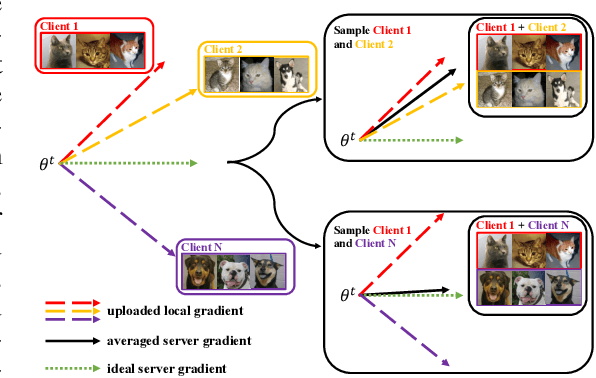
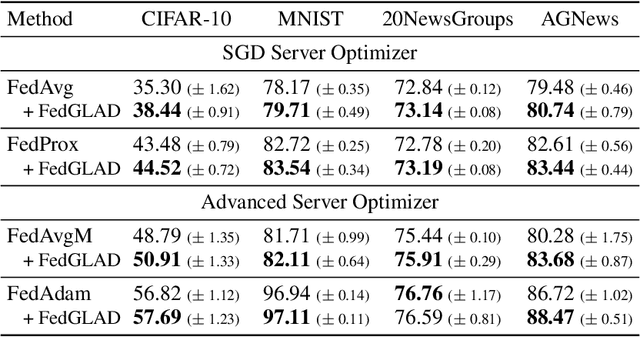
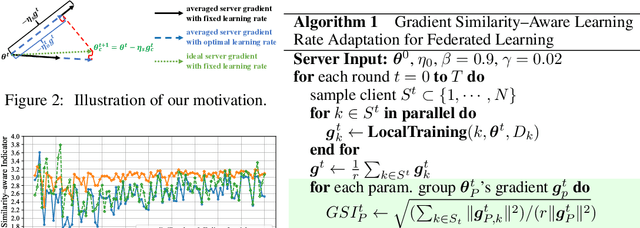
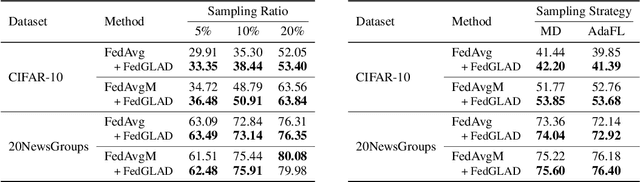
Federated Learning has become a widely-used framework which allows learning a global model on decentralized local datasets under the condition of protecting local data privacy. However, federated learning faces severe optimization difficulty when training samples are not independently and identically distributed (non-i.i.d.). In this paper, we point out that the client sampling practice plays a decisive role in the aforementioned optimization difficulty. We find that the negative client sampling will cause the merged data distribution of currently sampled clients heavily inconsistent with that of all available clients, and further make the aggregated gradient unreliable. To address this issue, we propose a novel learning rate adaptation mechanism to adaptively adjust the server learning rate for the aggregated gradient in each round, according to the consistency between the merged data distribution of currently sampled clients and that of all available clients. Specifically, we make theoretical deductions to find a meaningful and robust indicator that is positively related to the optimal server learning rate and can effectively reflect the merged data distribution of sampled clients, and we utilize it for the server learning rate adaptation. Extensive experiments on multiple image and text classification tasks validate the great effectiveness of our method.
From Mimicking to Integrating: Knowledge Integration for Pre-Trained Language Models
Oct 11, 2022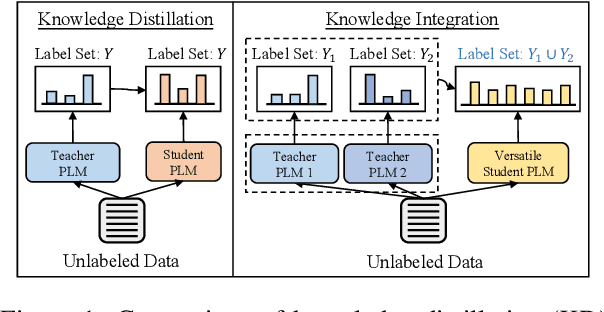
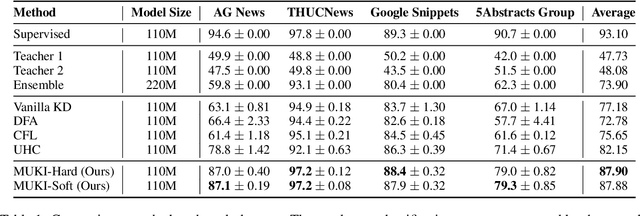
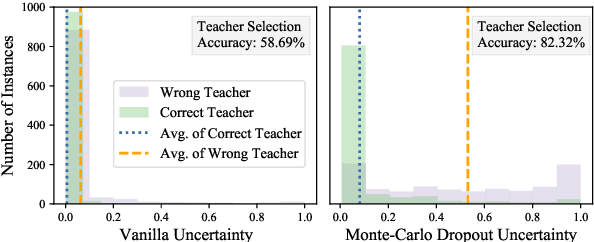
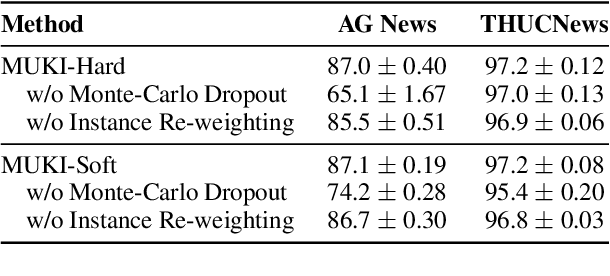
Investigating better ways to reuse the released pre-trained language models (PLMs) can significantly reduce the computational cost and the potential environmental side-effects. This paper explores a novel PLM reuse paradigm, Knowledge Integration (KI). Without human annotations available, KI aims to merge the knowledge from different teacher-PLMs, each of which specializes in a different classification problem, into a versatile student model. To achieve this, we first derive the correlation between virtual golden supervision and teacher predictions. We then design a Model Uncertainty--aware Knowledge Integration (MUKI) framework to recover the golden supervision for the student. Specifically, MUKI adopts Monte-Carlo Dropout to estimate model uncertainty for the supervision integration. An instance-wise re-weighting mechanism based on the margin of uncertainty scores is further incorporated, to deal with the potential conflicting supervision from teachers. Experimental results demonstrate that MUKI achieves substantial improvements over baselines on benchmark datasets. Further analysis shows that MUKI can generalize well for merging teacher models with heterogeneous architectures, and even teachers major in cross-lingual datasets.
Rethinking the Openness of CLIP
Jun 04, 2022Contrastive Language-Image Pre-training (CLIP) has demonstrated great potential in realizing open-vocabulary image classification in a matching style, because of its holistic use of natural language supervision that covers unconstrained real-world visual concepts. However, it is, in turn, also difficult to evaluate and analyze the openness of CLIP-like models, since they are in theory open to any vocabulary but the actual accuracy varies. To address the insufficiency of conventional studies on openness, we resort to an incremental view and define the extensibility, which essentially approximates the model's ability to deal with new visual concepts, by evaluating openness through vocabulary expansions. Our evaluation based on extensibility shows that CLIP-like models are hardly truly open and their performances degrade as the vocabulary expands to different degrees. Further analysis reveals that the over-estimation of openness is not because CLIP-like models fail to capture the general similarity of image and text features of novel visual concepts, but because of the confusion among competing text features, that is, they are not stable with respect to the vocabulary. In light of this, we propose to improve the openness of CLIP from the perspective of feature space by enforcing the distinguishability of text features. Our method retrieves relevant texts from the pre-training corpus to enhance prompts for inference, which boosts the extensibility and stability of CLIP even without fine-tuning.
Model Uncertainty-Aware Knowledge Amalgamation for Pre-Trained Language Models
Dec 14, 2021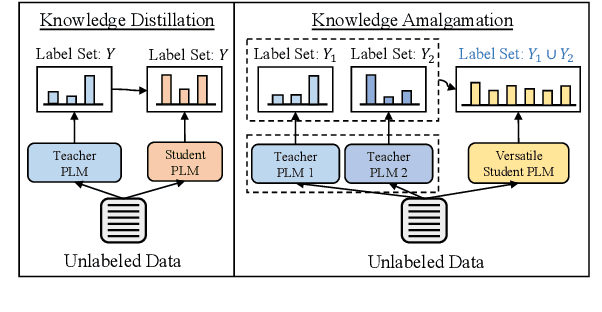
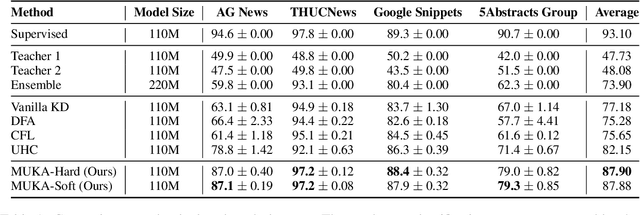
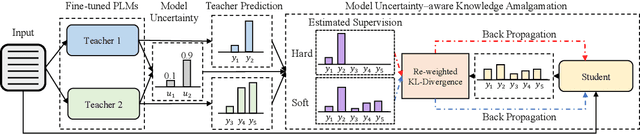
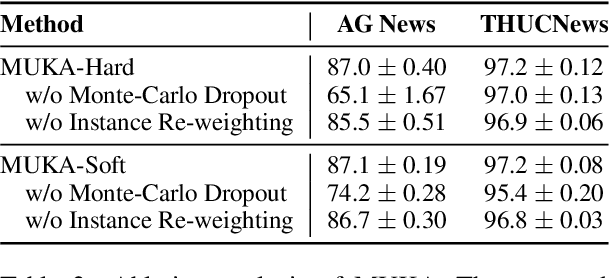
As many fine-tuned pre-trained language models~(PLMs) with promising performance are generously released, investigating better ways to reuse these models is vital as it can greatly reduce the retraining computational cost and the potential environmental side-effects. In this paper, we explore a novel model reuse paradigm, Knowledge Amalgamation~(KA) for PLMs. Without human annotations available, KA aims to merge the knowledge from different teacher-PLMs, each of which specializes in a different classification problem, into a versatile student model. The achieve this, we design a Model Uncertainty--aware Knowledge Amalgamation~(MUKA) framework, which identifies the potential adequate teacher using Monte-Carlo Dropout for approximating the golden supervision to guide the student. Experimental results demonstrate that MUKA achieves substantial improvements over baselines on benchmark datasets. Further analysis shows that MUKA can generalize well under several complicate settings with multiple teacher models, heterogeneous teachers, and even cross-dataset teachers.