 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyR1-32B-Preview: Boosting Accuracy with Branch-Merge Distillation
Mar 06, 2025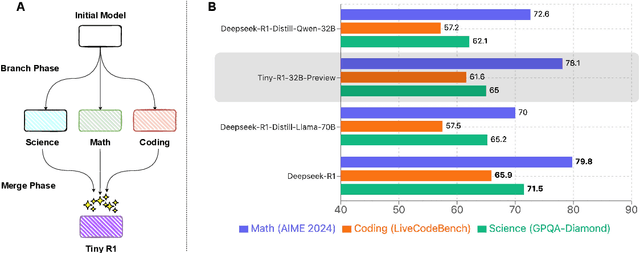
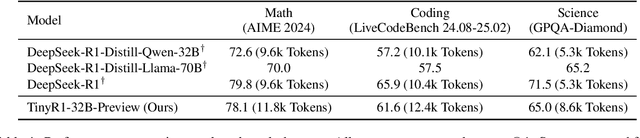
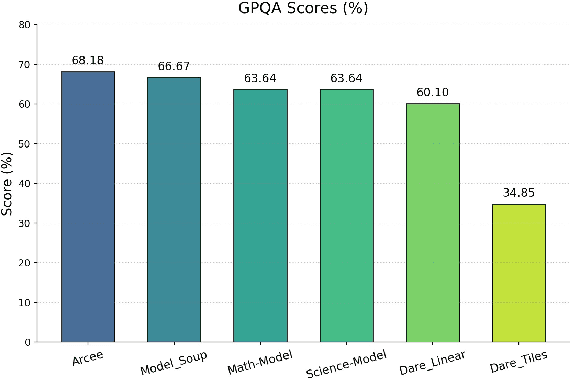
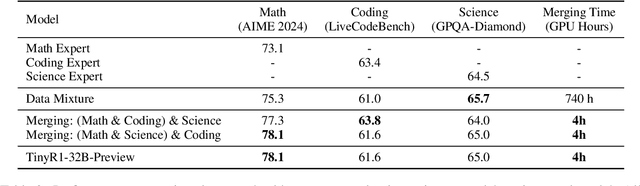
The challenge of reducing the size of Large Language Models (LLMs) while maintaining their performance has gained significant attention. However, existing methods, such as model distillation and transfer learning, often fail to achieve high accuracy. To address this limitation, we introduce the Branch-Merge distillation approach, which enhances model compression through two phases: (1) the Branch Phase, where knowledge from a large teacher model is \textit{selectively distilled} into specialized student models via domain-specific supervised fine-tuning (SFT); And (2) the Merge Phase, where these student models are merged to enable cross-domain knowledge transfer and improve generalization. We validate our distillation approach using DeepSeek-R1 as the teacher and DeepSeek-R1-Distill-Qwen-32B as the student. The resulting merged model, TinyR1-32B-Preview, outperforms its counterpart DeepSeek-R1-Distill-Qwen-32B across multiple benchmarks, including Mathematics (+5.5 points), Coding (+4.4 points) and Science (+2.9 points), while achieving near-equal performance to DeepSeek-R1 on AIME 2024. The Branch-Merge distillation approach provides a scalable solution for creating smaller, high-performing LLMs with reduced computational cost and time.
Chain-of-Thought Matters: Improving Long-Context Language Models with Reasoning Path Supervision
Feb 28, 2025



Recent advances in Large Language Models (LLMs) have highlighted the challenge of handling long-context tasks, where models need to reason over extensive input contexts to aggregate target information. While Chain-of-Thought (CoT) prompting has shown promise for multi-step reasoning, its effectiveness for long-context scenarios remains underexplored. Through systematic investigation across diverse tasks, we demonstrate that CoT's benefits generalize across most long-context scenarios and amplify with increasing context length. Motivated by this critical observation, we propose LongRePS, a process-supervised framework that teaches models to generate high-quality reasoning paths for enhanced long-context performance. Our framework incorporates a self-sampling mechanism to bootstrap reasoning paths and a novel quality assessment protocol specifically designed for long-context scenarios. Experimental results on various long-context benchmarks demonstrate the effectiveness of our approach, achieving significant improvements over outcome supervision baselines on both in-domain tasks (+13.6/+3.8 points for LLaMA/Qwen on MuSiQue) and cross-domain generalization (+9.3/+8.1 points on average across diverse QA tasks). Our code, data and trained models are made public to facilitate future research.
LongAttn: Selecting Long-context Training Data via Token-level Attention
Feb 24, 2025



With the development of large language models (LLMs), there has been an increasing need for significant advancements in handling long contexts. To enhance long-context capabilities, constructing high-quality training data with long-range dependencies is crucial. Existing methods to select long-context data often rely on sentence-level analysis, which can be greatly optimized in both performance and efficiency. In this paper, we propose a novel token-level framework, LongAttn, which leverages the self-attention mechanism of LLMs to measure the long-range dependencies for the data. By calculating token-level dependency strength and distribution uniformity of token scores, LongAttn effectively quantifies long-range dependencies, enabling more accurate and efficient data selection. We filter LongABC-32K from open-source long-context datasets (ArXiv, Book, and Code). Through our comprehensive experiments, LongAttn has demonstrated its excellent effectiveness, scalability, and efficiency. To facilitate future research in long-context data, we released our code and the high-quality long-context training data LongABC-32K.