 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking with Reasoning Skills: Fewer Tokens, More Accuracy
Apr 23, 2026Reasoning LLMs often spend substantial tokens on long intermediate reasoning traces (e.g., chain-of-thought) when solving new problems. We propose to summarize and store reusable reasoning skills distilled from extensive deliberation and trial-and-error exploration, and to retrieve these skills at inference time to guide future reasoning. Unlike the prevailing \emph{reasoning from scratch} paradigm, our approach first recalls relevant skills for each query, helping the model avoid redundant detours and focus on effective solution paths. We evaluate our method on coding and mathematical reasoning tasks, and find that it significantly reduces reasoning tokens while improving overall performance. The resulting lower per-request cost indicates strong practical and economic potential for real-world deployment.
Beyond Parameter Arithmetic: Sparse Complementary Fusion for Distribution-Aware Model Merging
Feb 12, 2026Model merging has emerged as a promising paradigm for composing the capabilities of large language models by directly operating in weight space, enabling the integration of specialized models without costly retraining. However, existing merging methods largely rely on parameter-space heuristics, which often introduce severe interference, leading to degraded generalization and unstable generation behaviors such as repetition and incoherent outputs. In this work, we propose Sparse Complementary Fusion with reverse KL (SCF-RKL), a novel model merging framework that explicitly controls functional interference through sparse, distribution-aware updates. Instead of assuming linear additivity in parameter space, SCF-RKL measures the functional divergence between models using reverse Kullback-Leibler divergence and selectively incorporates complementary parameters. This mode-seeking, sparsity-inducing design effectively preserves stable representations while integrating new capabilities. We evaluate SCF-RKL across a wide range of model scales and architectures, covering both reasoning-focused and instruction-tuned models. Extensive experiments on 24 benchmarks spanning advanced reasoning, general reasoning and knowledge, instruction following, and safety demonstrate, vision classification that SCF-RKL consistently outperforms existing model merging methods while maintaining strong generalization and generation stability.
Beyond Static Alignment: Hierarchical Policy Control for LLM Safety via Risk-Aware Chain-of-Thought
Feb 06, 2026Large Language Models (LLMs) face a fundamental safety-helpfulness trade-off due to static, one-size-fits-all safety policies that lack runtime controllabilityxf, making it difficult to tailor responses to diverse application needs. %As a result, models may over-refuse benign requests or under-constrain harmful ones. We present \textbf{PACT} (Prompt-configured Action via Chain-of-Thought), a framework for dynamic safety control through explicit, risk-aware reasoning. PACT operates under a hierarchical policy architecture: a non-overridable global safety policy establishes immutable boundaries for critical risks (e.g., child safety, violent extremism), while user-defined policies can introduce domain-specific (non-global) risk categories and specify label-to-action behaviors to improve utility in real-world deployment settings. The framework decomposes safety decisions into structured Classify$\rightarrow$Act paths that route queries to the appropriate action (comply, guide, or reject) and render the decision-making process transparent. Extensive experiments demonstrate that PACT achieves near state-of-the-art safety performance under global policy evaluation while attaining the best controllability under user-specific policy evaluation, effectively mitigating the safety-helpfulness trade-off. We will release the PACT model suite, training data, and evaluation protocols to facilitate reproducible research in controllable safety alignment.
FABLE: Forest-Based Adaptive Bi-Path LLM-Enhanced Retrieval for Multi-Document Reasoning
Jan 26, 2026The rapid expansion of long-context Large Language Models (LLMs) has reignited debate on whether Retrieval-Augmented Generation (RAG) remains necessary. However, empirical evidence reveals persistent limitations of long-context inference, including the lost-in-the-middle phenomenon, high computational cost, and poor scalability for multi-document reasoning. Conversely, traditional RAG systems, while efficient, are constrained by flat chunk-level retrieval that introduces semantic noise and fails to support structured cross-document synthesis. We present \textbf{FABLE}, a \textbf{F}orest-based \textbf{A}daptive \textbf{B}i-path \textbf{L}LM-\textbf{E}nhanced retrieval framework that integrates LLMs into both knowledge organization and retrieval. FABLE constructs LLM-enhanced hierarchical forest indexes with multi-granularity semantic structures, then employs a bi-path strategy combining LLM-guided hierarchical traversal with structure-aware propagation for fine-grained evidence acquisition, with explicit budget control for adaptive efficiency trade-offs. Extensive experiments demonstrate that FABLE consistently outperforms SOTA RAG methods and achieves comparable accuracy to full-context LLM inference with up to 94\% token reduction, showing that long-context LLMs amplify rather than fully replace the need for structured retrieval.
TriPlay-RL: Tri-Role Self-Play Reinforcement Learning for LLM Safety Alignment
Jan 26, 2026In recent years, safety risks associated with large language models have become increasingly prominent, highlighting the urgent need to mitigate the generation of toxic and harmful content. The mainstream paradigm for LLM safety alignment typically adopts a collaborative framework involving three roles: an attacker for adversarial prompt generation, a defender for safety defense, and an evaluator for response assessment. In this paper, we propose a closed-loop reinforcement learning framework called TriPlay-RL that enables iterative and co-improving collaboration among three roles with near-zero manual annotation. Experimental results show that the attacker preserves high output diversity while achieving a 20%-50% improvement in adversarial effectiveness; the defender attains 10%-30% gains in safety performance without degrading general reasoning capability; and the evaluator continuously refines its fine-grained judgment ability through iterations, accurately distinguishing unsafe responses, simple refusals, and useful guidance. Overall, our framework establishes an efficient and scalable paradigm for LLM safety alignment, enabling continuous co-evolution within a unified learning loop.
TextlessRAG: End-to-End Visual Document RAG by Speech Without Text
Sep 10, 2025Document images encapsulate a wealth of knowledge, while the portability of spoken queries enables broader and flexible application scenarios. Yet, no prior work has explored knowledge base question answering over visual document images with queries provided directly in speech. We propose TextlessRAG, the first end-to-end framework for speech-based question answering over large-scale document images. Unlike prior methods, TextlessRAG eliminates ASR, TTS and OCR, directly interpreting speech, retrieving relevant visual knowledge, and generating answers in a fully textless pipeline. To further boost performance, we integrate a layout-aware reranking mechanism to refine retrieval. Experiments demonstrate substantial improvements in both efficiency and accuracy. To advance research in this direction, we also release the first bilingual speech--document RAG dataset, featuring Chinese and English voice queries paired with multimodal document content. Both the dataset and our pipeline will be made available at repository:https://github.com/xiepeijinhit-hue/textlessrag
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
Aug 26, 2025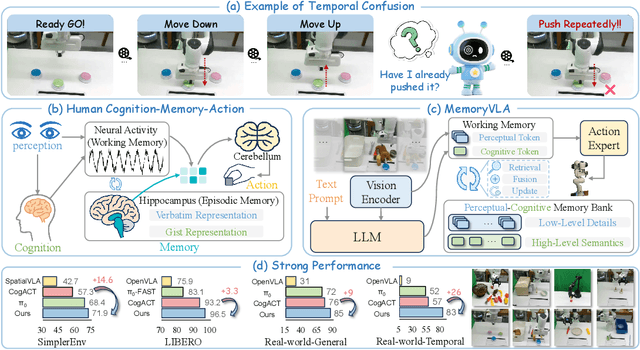
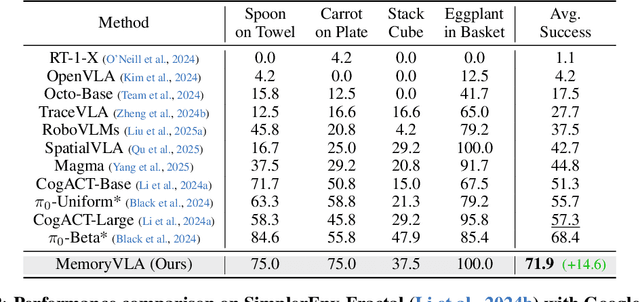
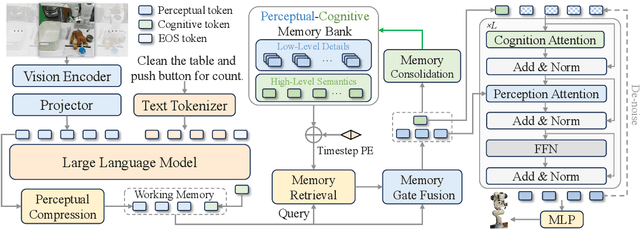
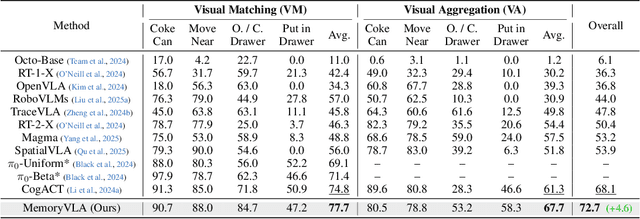
Temporal context is essential for robotic manipulation because such tasks are inherently non-Markovian, yet mainstream VLA models typically overlook it and struggle with long-horizon, temporally dependent tasks. Cognitive science suggests that humans rely on working memory to buffer short-lived representations for immediate control, while the hippocampal system preserves verbatim episodic details and semantic gist of past experience for long-term memory. Inspired by these mechanisms, we propose MemoryVLA, a Cognition-Memory-Action framework for long-horizon robotic manipulation. A pretrained VLM encodes the observation into perceptual and cognitive tokens that form working memory, while a Perceptual-Cognitive Memory Bank stores low-level details and high-level semantics consolidated from it. Working memory retrieves decision-relevant entries from the bank, adaptively fuses them with current tokens, and updates the bank by merging redundancies. Using these tokens, a memory-conditioned diffusion action expert yields temporally aware action sequences. We evaluate MemoryVLA on 150+ simulation and real-world tasks across three robots. On SimplerEnv-Bridge, Fractal, and LIBERO-5 suites, it achieves 71.9%, 72.7%, and 96.5% success rates, respectively, all outperforming state-of-the-art baselines CogACT and pi-0, with a notable +14.6 gain on Bridge. On 12 real-world tasks spanning general skills and long-horizon temporal dependencies, MemoryVLA achieves 84.0% success rate, with long-horizon tasks showing a +26 improvement over state-of-the-art baseline. Project Page: https://shihao1895.github.io/MemoryVLA
GeoVLA: Empowering 3D Representations in Vision-Language-Action Models
Aug 12, 2025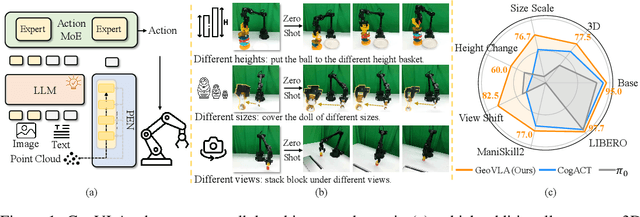
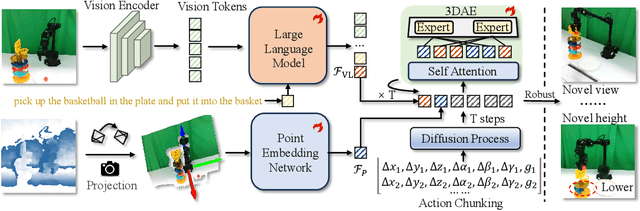
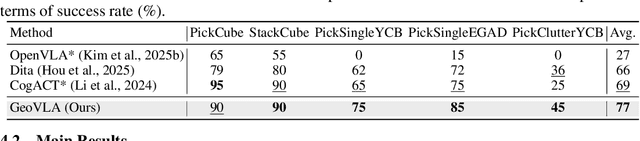
Vision-Language-Action (VLA) models have emerged as a promising approach for enabling robots to follow language instructions and predict corresponding actions.However, current VLA models mainly rely on 2D visual inputs, neglecting the rich geometric information in the 3D physical world, which limits their spatial awareness and adaptability. In this paper, we present GeoVLA, a novel VLA framework that effectively integrates 3D information to advance robotic manipulation. It uses a vision-language model (VLM) to process images and language instructions,extracting fused vision-language embeddings. In parallel, it converts depth maps into point clouds and employs a customized point encoder, called Point Embedding Network, to generate 3D geometric embeddings independently. These produced embeddings are then concatenated and processed by our proposed spatial-aware action expert, called 3D-enhanced Action Expert, which combines information from different sensor modalities to produce precise action sequences. Through extensive experiments in both simulation and real-world environments, GeoVLA demonstrates superior performance and robustness. It achieves state-of-the-art results in the LIBERO and ManiSkill2 simulation benchmarks and shows remarkable robustness in real-world tasks requiring height adaptability, scale awareness and viewpoint invariance.
Evaluation is All You Need: Strategic Overclaiming of LLM Reasoning Capabilities Through Evaluation Design
Jun 05, 2025Reasoning models represented by the Deepseek-R1-Distill series have been widely adopted by the open-source community due to their strong performance in mathematics, science, programming, and other domains. However, our study reveals that their benchmark evaluation results are subject to significant fluctuations caused by various factors. Subtle differences in evaluation conditions can lead to substantial variations in results. Similar phenomena are observed in other open-source inference models fine-tuned based on the Deepseek-R1-Distill series, as well as in the QwQ-32B model, making their claimed performance improvements difficult to reproduce reliably. Therefore, we advocate for the establishment of a more rigorous paradigm for model performance evaluation and present our empirical assessments of the Deepseek-R1-Distill series models.
CaMDN: Enhancing Cache Efficiency for Multi-tenant DNNs on Integrated NPUs
May 10, 2025With the rapid development of DNN applications, multi-tenant execution, where multiple DNNs are co-located on a single SoC, is becoming a prevailing trend. Although many methods are proposed in prior works to improve multi-tenant performance, the impact of shared cache is not well studied. This paper proposes CaMDN, an architecture-scheduling co-design to enhance cache efficiency for multi-tenant DNNs on integrated NPUs. Specifically, a lightweight architecture is proposed to support model-exclusive, NPU-controlled regions inside shared cache to eliminate unexpected cache contention. Moreover, a cache scheduling method is proposed to improve shared cache utilization. In particular, it includes a cache-aware mapping method for adaptability to the varying available cache capacity and a dynamic allocation algorithm to adjust the usage among co-located DNNs at runtime. Compared to prior works, CaMDN reduces the memory access by 33.4% on average and achieves a model speedup of up to 2.56$\times$ (1.88$\times$ on average).