 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIPer: Hierarchically Improving Spatial Representation of CLIP for Open-Vocabulary Semantic Segmentation
Nov 21, 2024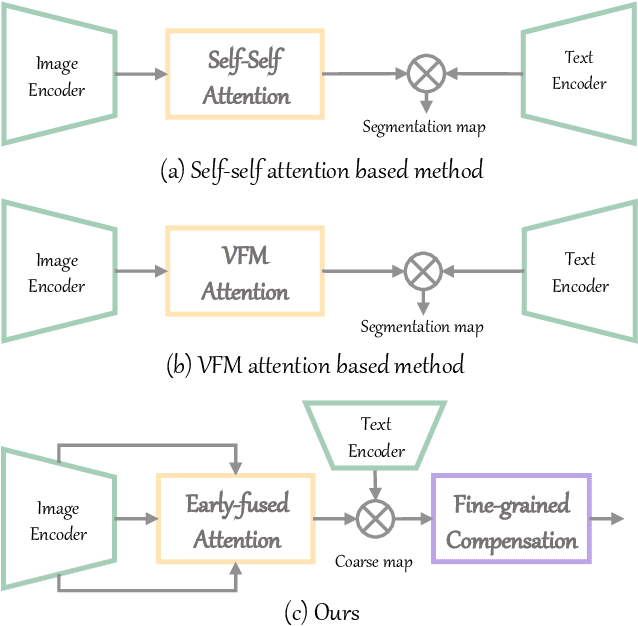
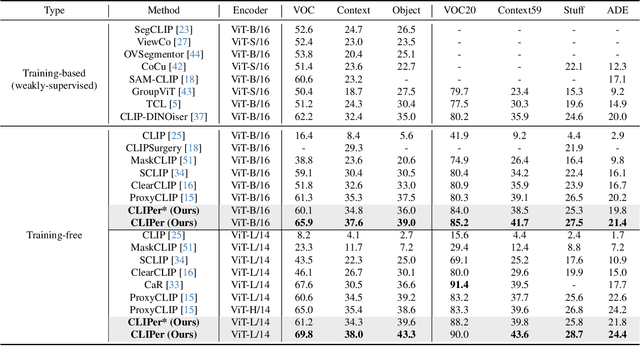


Contrastive Language-Image Pre-training (CLIP) exhibits strong zero-shot classification ability on various image-level tasks, leading to the research to adapt CLIP for pixel-level open-vocabulary semantic segmentation without additional training. The key is to improve spatial representation of image-level CLIP, such as replacing self-attention map at last layer with self-self attention map or vision foundation model based attention map. In this paper, we present a novel hierarchical framework, named CLIPer, that hierarchically improves spatial representation of CLIP. The proposed CLIPer includes an early-layer fusion module and a fine-grained compensation module. We observe that, the embeddings and attention maps at early layers can preserve spatial structural information. Inspired by this, we design the early-layer fusion module to generate segmentation map with better spatial coherence. Afterwards, we employ a fine-grained compensation module to compensate the local details using the self-attention maps of diffusion model. We conduct the experiments on seven segmentation datasets. Our proposed CLIPer achieves the state-of-the-art performance on these datasets. For instance, using ViT-L, CLIPer has the mIoU of 69.8% and 43.3% on VOC and COCO Object, outperforming ProxyCLIP by 9.2% and 4.1% respectively.
Few-Shot Object Detection with Sparse Context Transformers
Feb 14, 2024



Few-shot detection is a major task in pattern recognition which seeks to localize objects using models trained with few labeled data. One of the mainstream few-shot methods is transfer learning which consists in pretraining a detection model in a source domain prior to its fine-tuning in a target domain. However, it is challenging for fine-tuned models to effectively identify new classes in the target domain, particularly when the underlying labeled training data are scarce. In this paper, we devise a novel sparse context transformer (SCT) that effectively leverages object knowledge in the source domain, and automatically learns a sparse context from only few training images in the target domain. As a result, it combines different relevant clues in order to enhance the discrimination power of the learned detectors and reduce class confusion. We evaluate the proposed method on two challenging few-shot object detection benchmarks, and empirical results show that the proposed method obtains competitive performance compared to the related state-of-the-art.
Joint Attention-Guided Feature Fusion Network for Saliency Detection of Surface Defects
Feb 05, 2024Surface defect inspection plays an important role in the process of industrial manufacture and production. Though Convolutional Neural Network (CNN) based defect inspection methods have made huge leaps, they still confront a lot of challenges such as defect scale variation, complex background, low contrast, and so on. To address these issues, we propose a joint attention-guided feature fusion network (JAFFNet) for saliency detection of surface defects based on the encoder-decoder network. JAFFNet mainly incorporates a joint attention-guided feature fusion (JAFF) module into decoding stages to adaptively fuse low-level and high-level features. The JAFF module learns to emphasize defect features and suppress background noise during feature fusion, which is beneficial for detecting low-contrast defects. In addition, JAFFNet introduces a dense receptive field (DRF) module following the encoder to capture features with rich context information, which helps detect defects of different scales. The JAFF module mainly utilizes a learned joint channel-spatial attention map provided by high-level semantic features to guide feature fusion. The attention map makes the model pay more attention to defect features. The DRF module utilizes a sequence of multi-receptive-field (MRF) units with each taking as inputs all the preceding MRF feature maps and the original input. The obtained DRF features capture rich context information with a large range of receptive fields. Extensive experiments conducted on SD-saliency-900, Magnetic tile, and DAGM 2007 indicate that our method achieves promising performance in comparison with other state-of-the-art methods. Meanwhile, our method reaches a real-time defect detection speed of 66 FPS.
ID-like Prompt Learning for Few-Shot Out-of-Distribution Detection
Nov 28, 2023Out-of-distribution (OOD) detection methods often exploit auxiliary outliers to train model identifying OOD samples, especially discovering challenging outliers from auxiliary outliers dataset to improve OOD detection. However, they may still face limitations in effectively distinguishing between the most challenging OOD samples that are much like in-distribution (ID) data, i.e., ID-like samples. To this end, we propose a novel OOD detection framework that discovers ID-like outliers using CLIP from the vicinity space of the ID samples, thus helping to identify these most challenging OOD samples. Then a prompt learning framework is proposed that utilizes the identified ID-like outliers to further leverage the capabilities of CLIP for OOD detection. Benefiting from the powerful CLIP, we only need a small number of ID samples to learn the prompts of the model without exposing other auxiliary outlier datasets. By focusing on the most challenging ID-like OOD samples and elegantly exploiting the capabilities of CLIP, our method achieves superior few-shot learning performance on various real-world image datasets (e.g., in 4-shot OOD detection on the ImageNet-1k dataset, our method reduces the average FPR95 by 12.16% and improves the average AUROC by 2.76%, compared to state-of-the-art methods).
Decision Fusion Network with Perception Fine-tuning for Defect Classification
Sep 22, 2023
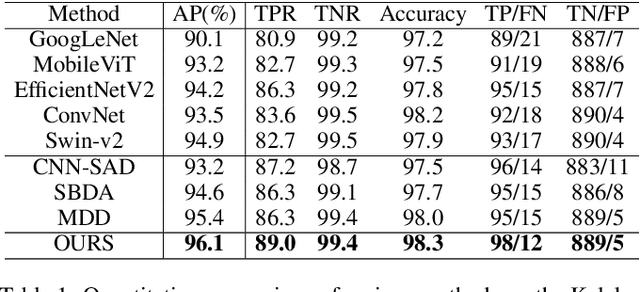
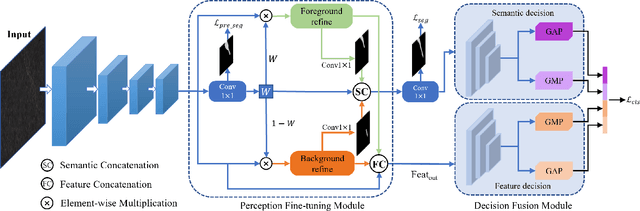
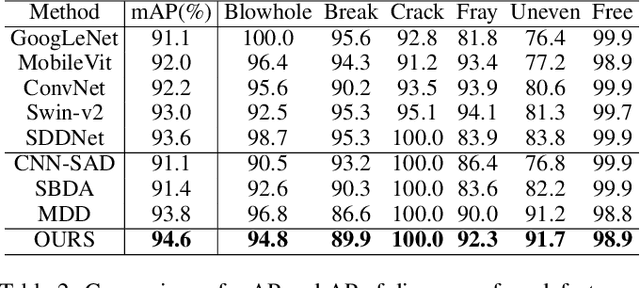
Surface defect inspection is an important task in industrial inspection. Deep learning-based methods have demonstrated promising performance in this domain. Nevertheless, these methods still suffer from misjudgment when encountering challenges such as low-contrast defects and complex backgrounds. To overcome these issues, we present a decision fusion network (DFNet) that incorporates the semantic decision with the feature decision to strengthen the decision ability of the network. In particular, we introduce a decision fusion module (DFM) that extracts a semantic vector from the semantic decision branch and a feature vector for the feature decision branch and fuses them to make the final classification decision. In addition, we propose a perception fine-tuning module (PFM) that fine-tunes the foreground and background during the segmentation stage. PFM generates the semantic and feature outputs that are sent to the classification decision stage. Furthermore, we present an inner-outer separation weight matrix to address the impact of label edge uncertainty during segmentation supervision. Our experimental results on the publicly available datasets including KolektorSDD2 (96.1% AP) and Magnetic-tile-defect-datasets (94.6% mAP) demonstrate the effectiveness of the proposed method.
Global Context Aggregation Network for Lightweight Saliency Detection of Surface Defects
Sep 22, 2023



Surface defect inspection is a very challenging task in which surface defects usually show weak appearances or exist under complex backgrounds. Most high-accuracy defect detection methods require expensive computation and storage overhead, making them less practical in some resource-constrained defect detection applications. Although some lightweight methods have achieved real-time inference speed with fewer parameters, they show poor detection accuracy in complex defect scenarios. To this end, we develop a Global Context Aggregation Network (GCANet) for lightweight saliency detection of surface defects on the encoder-decoder structure. First, we introduce a novel transformer encoder on the top layer of the lightweight backbone, which captures global context information through a novel Depth-wise Self-Attention (DSA) module. The proposed DSA performs element-wise similarity in channel dimension while maintaining linear complexity. In addition, we introduce a novel Channel Reference Attention (CRA) module before each decoder block to strengthen the representation of multi-level features in the bottom-up path. The proposed CRA exploits the channel correlation between features at different layers to adaptively enhance feature representation. The experimental results on three public defect datasets demonstrate that the proposed network achieves a better trade-off between accuracy and running efficiency compared with other 17 state-of-the-art methods. Specifically, GCANet achieves competitive accuracy (91.79% $F_{\beta}^{w}$, 93.55% $S_\alpha$, and 97.35% $E_\phi$) on SD-saliency-900 while running 272fps on a single gpu.
CINFormer: Transformer network with multi-stage CNN feature injection for surface defect segmentation
Sep 22, 2023



Surface defect inspection is of great importance for industrial manufacture and production. Though defect inspection methods based on deep learning have made significant progress, there are still some challenges for these methods, such as indistinguishable weak defects and defect-like interference in the background. To address these issues, we propose a transformer network with multi-stage CNN (Convolutional Neural Network) feature injection for surface defect segmentation, which is a UNet-like structure named CINFormer. CINFormer presents a simple yet effective feature integration mechanism that injects the multi-level CNN features of the input image into different stages of the transformer network in the encoder. This can maintain the merit of CNN capturing detailed features and that of transformer depressing noises in the background, which facilitates accurate defect detection. In addition, CINFormer presents a Top-K self-attention module to focus on tokens with more important information about the defects, so as to further reduce the impact of the redundant background. Extensive experiments conducted on the surface defect datasets DAGM 2007, Magnetic tile, and NEU show that the proposed CINFormer achieves state-of-the-art performance in defect detection.
Focal and Global Spatial-Temporal Transformer for Skeleton-based Action Recognition
Oct 06, 2022
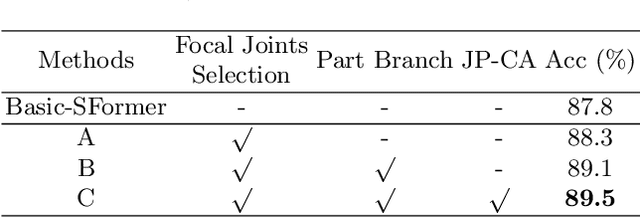
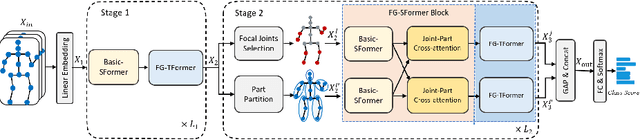

Despite great progress achieved by transformer in various vision tasks, it is still underexplored for skeleton-based action recognition with only a few attempts. Besides, these methods directly calculate the pair-wise global self-attention equally for all the joints in both the spatial and temporal dimensions, undervaluing the effect of discriminative local joints and the short-range temporal dynamics. In this work, we propose a novel Focal and Global Spatial-Temporal Transformer network (FG-STFormer), that is equipped with two key components: (1) FG-SFormer: focal joints and global parts coupling spatial transformer. It forces the network to focus on modelling correlations for both the learned discriminative spatial joints and human body parts respectively. The selective focal joints eliminate the negative effect of non-informative ones during accumulating the correlations. Meanwhile, the interactions between the focal joints and body parts are incorporated to enhance the spatial dependencies via mutual cross-attention. (2) FG-TFormer: focal and global temporal transformer. Dilated temporal convolution is integrated into the global self-attention mechanism to explicitly capture the local temporal motion patterns of joints or body parts, which is found to be vital important to make temporal transformer work. Extensive experimental results on three benchmarks, namely NTU-60, NTU-120 and NW-UCLA, show our FG-STFormer surpasses all existing transformer-based methods, and compares favourably with state-of-the art GCN-based methods.
Multi-scale Feature Aggregation for Crowd Counting
Aug 11, 2022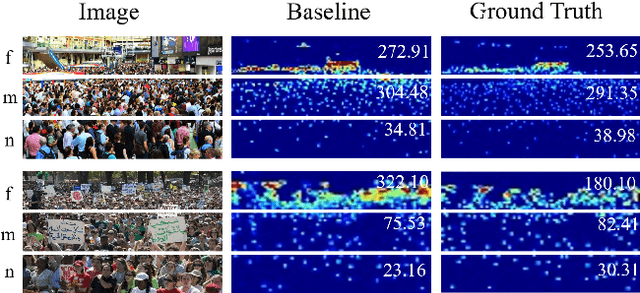
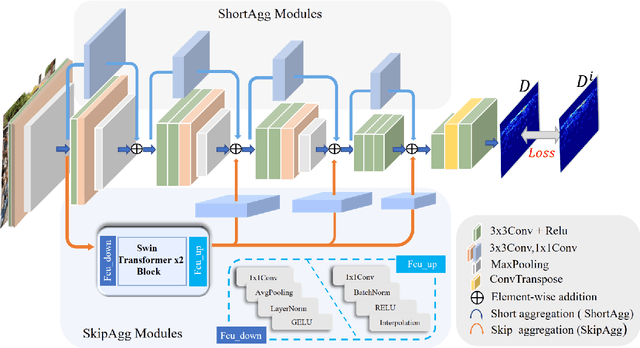

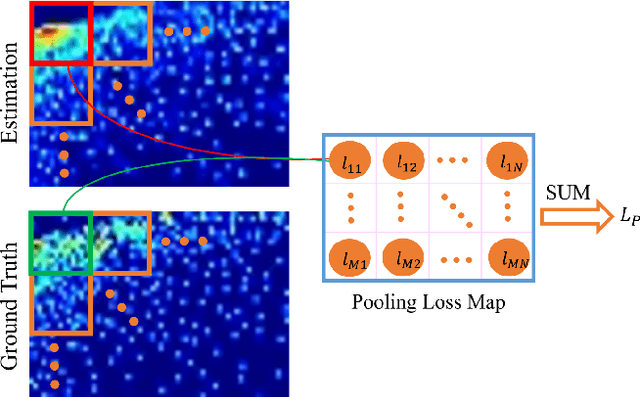
Convolutional Neural Network (CNN) based crowd counting methods have achieved promising results in the past few years. However, the scale variation problem is still a huge challenge for accurate count estimation. In this paper, we propose a multi-scale feature aggregation network (MSFANet) that can alleviate this problem to some extent. Specifically, our approach consists of two feature aggregation modules: the short aggregation (ShortAgg) and the skip aggregation (SkipAgg). The ShortAgg module aggregates the features of the adjacent convolution blocks. Its purpose is to make features with different receptive fields fused gradually from the bottom to the top of the network. The SkipAgg module directly propagates features with small receptive fields to features with much larger receptive fields. Its purpose is to promote the fusion of features with small and large receptive fields. Especially, the SkipAgg module introduces the local self-attention features from the Swin Transformer blocks to incorporate rich spatial information. Furthermore, we present a local-and-global based counting loss by considering the non-uniform crowd distribution. Extensive experiments on four challenging datasets (ShanghaiTech dataset, UCF_CC_50 dataset, UCF-QNRF Dataset, WorldExpo'10 dataset) demonstrate the proposed easy-to-implement MSFANet can achieve promising results when compared with the previous state-of-the-art approaches.
User-Guided Personalized Image Aesthetic Assessment based on Deep Reinforcement Learning
Jun 14, 2021

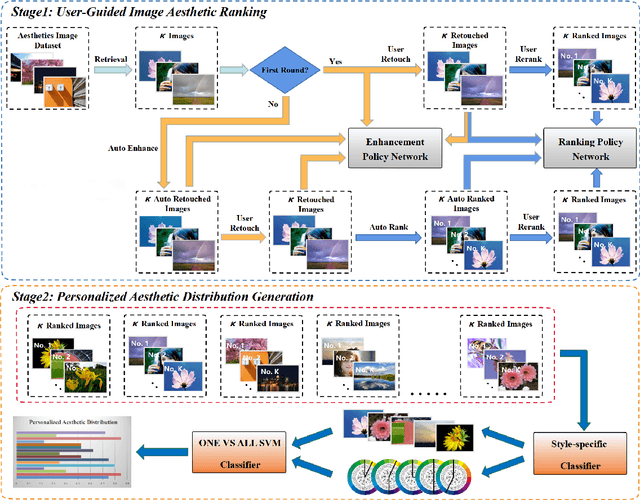
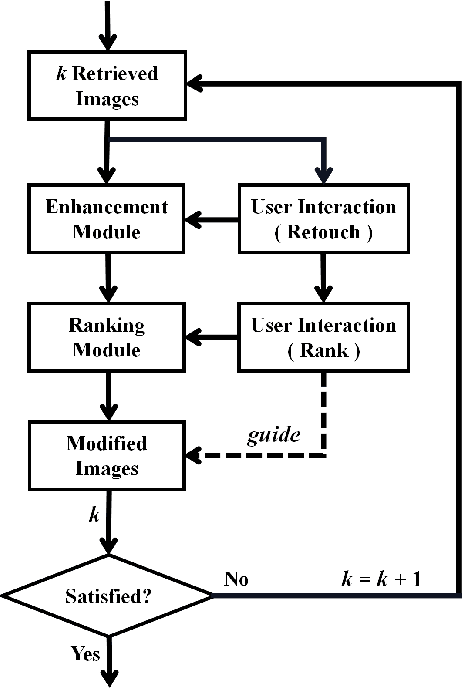
Personalized image aesthetic assessment (PIAA) has recently become a hot topic due to its usefulness in a wide variety of applications such as photography, film and television, e-commerce, fashion design and so on. This task is more seriously affected by subjective factors and samples provided by users. In order to acquire precise personalized aesthetic distribution by small amount of samples, we propose a novel user-guided personalized image aesthetic assessment framework. This framework leverages user interactions to retouch and rank images for aesthetic assessment based on deep reinforcement learning (DRL), and generates personalized aesthetic distribution that is more in line with the aesthetic preferences of different users. It mainly consists of two stages. In the first stage, personalized aesthetic ranking is generated by interactive image enhancement and manual ranking, meanwhile two policy networks will be trained. The images will be pushed to the user for manual retouching and simultaneously to the enhancement policy network. The enhancement network utilizes the manual retouching results as the optimization goals of DRL. After that, the ranking process performs the similar operations like the retouching mentioned before. These two networks will be trained iteratively and alternatively to help to complete the final personalized aesthetic assessment automatically. In the second stage, these modified images are labeled with aesthetic attributes by one style-specific classifier, and then the personalized aesthetic distribution is generated based on the multiple aesthetic attributes of these images, which conforms to the aesthetic preference of users better.