 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGBX-R1: Visual Modality Chain-of-Thought Guided Reinforcement Learning for Multimodal Grounding
Jan 31, 2026Multimodal Large Language Models (MLLM) are primarily pre-trained on the RGB modality, thereby limiting their performance on other modalities, such as infrared, depth, and event data, which are crucial for complex scenarios. To address this, we propose RGBX-R1, a framework to enhance MLLM's perception and reasoning capacities across various X visual modalities. Specifically, we employ an Understand-Associate-Validate (UAV) prompting strategy to construct the Visual Modality Chain-of-Thought (VM-CoT), which aims to expand the MLLMs' RGB understanding capability into X modalities. To progressively enhance reasoning capabilities, we introduce a two-stage training paradigm: Cold-Start Supervised Fine-Tuning (CS-SFT) and Spatio-Temporal Reinforcement Fine-Tuning (ST-RFT). CS-SFT supervises the reasoning process with the guidance of VM-CoT, equipping the MLLM with fundamental modality cognition. Building upon GRPO, ST-RFT employs a Modality-understanding Spatio-Temporal (MuST) reward to reinforce modality reasoning. Notably, we construct the first RGBX-Grounding benchmark, and extensive experiments verify our superiority in multimodal understanding and spatial perception, outperforming baselines by 22.71% on three RGBX grounding tasks.
Reversible Efficient Diffusion for Image Fusion
Jan 28, 2026Multi-modal image fusion aims to consolidate complementary information from diverse source images into a unified representation. The fused image is expected to preserve fine details and maintain high visual fidelity. While diffusion models have demonstrated impressive generative capabilities in image generation, they often suffer from detail loss when applied to image fusion tasks. This issue arises from the accumulation of noise errors inherent in the Markov process, leading to inconsistency and degradation in the fused results. However, incorporating explicit supervision into end-to-end training of diffusion-based image fusion introduces challenges related to computational efficiency. To address these limitations, we propose the Reversible Efficient Diffusion (RED) model - an explicitly supervised training framework that inherits the powerful generative capability of diffusion models while avoiding the distribution estimation.
Bi-directional Self-Registration for Misaligned Infrared-Visible Image Fusion
May 11, 2025Acquiring accurately aligned multi-modal image pairs is fundamental for achieving high-quality multi-modal image fusion. To address the lack of ground truth in current multi-modal image registration and fusion methods, we propose a novel self-supervised \textbf{B}i-directional \textbf{S}elf-\textbf{R}egistration framework (\textbf{B-SR}). Specifically, B-SR utilizes a proxy data generator (PDG) and an inverse proxy data generator (IPDG) to achieve self-supervised global-local registration. Visible-infrared image pairs with spatially misaligned differences are aligned to obtain global differences through the registration module. The same image pairs are processed by PDG, such as cropping, flipping, stitching, etc., and then aligned to obtain local differences. IPDG converts the obtained local differences into pseudo-global differences, which are used to perform global-local difference consistency with the global differences. Furthermore, aiming at eliminating the effect of modal gaps on the registration module, we design a neighborhood dynamic alignment loss to achieve cross-modal image edge alignment. Extensive experiments on misaligned multi-modal images demonstrate the effectiveness of the proposed method in multi-modal image alignment and fusion against the competing methods. Our code will be publicly available.
Dig2DIG: Dig into Diffusion Information Gains for Image Fusion
Mar 24, 2025Image fusion integrates complementary information from multi-source images to generate more informative results. Recently, the diffusion model, which demonstrates unprecedented generative potential, has been explored in image fusion. However, these approaches typically incorporate predefined multimodal guidance into diffusion, failing to capture the dynamically changing significance of each modality, while lacking theoretical guarantees. To address this issue, we reveal a significant spatio-temporal imbalance in image denoising; specifically, the diffusion model produces dynamic information gains in different image regions with denoising steps. Based on this observation, we Dig into the Diffusion Information Gains (Dig2DIG) and theoretically derive a diffusion-based dynamic image fusion framework that provably reduces the upper bound of the generalization error. Accordingly, we introduce diffusion information gains (DIG) to quantify the information contribution of each modality at different denoising steps, thereby providing dynamic guidance during the fusion process. Extensive experiments on multiple fusion scenarios confirm that our method outperforms existing diffusion-based approaches in terms of both fusion quality and inference efficiency.
Dream-IF: Dynamic Relative EnhAnceMent for Image Fusion
Mar 13, 2025Image fusion aims to integrate comprehensive information from images acquired through multiple sources. However, images captured by diverse sensors often encounter various degradations that can negatively affect fusion quality. Traditional fusion methods generally treat image enhancement and fusion as separate processes, overlooking the inherent correlation between them; notably, the dominant regions in one modality of a fused image often indicate areas where the other modality might benefit from enhancement. Inspired by this observation, we introduce the concept of dominant regions for image enhancement and present a Dynamic Relative EnhAnceMent framework for Image Fusion (Dream-IF). This framework quantifies the relative dominance of each modality across different layers and leverages this information to facilitate reciprocal cross-modal enhancement. By integrating the relative dominance derived from image fusion, our approach supports not only image restoration but also a broader range of image enhancement applications. Furthermore, we employ prompt-based encoding to capture degradation-specific details, which dynamically steer the restoration process and promote coordinated enhancement in both multi-modal image fusion and image enhancement scenarios. Extensive experimental results demonstrate that Dream-IF consistently outperforms its counterparts.
Rethinking Bottlenecks in Safety Fine-Tuning of Vision Language Models
Jan 30, 2025Large Vision-Language Models (VLMs) have achieved remarkable performance across a wide range of tasks. However, their deployment in safety-critical domains poses significant challenges. Existing safety fine-tuning methods, which focus on textual or multimodal content, fall short in addressing challenging cases or disrupt the balance between helpfulness and harmlessness. Our evaluation highlights a safety reasoning gap: these methods lack safety visual reasoning ability, leading to such bottlenecks. To address this limitation and enhance both visual perception and reasoning in safety-critical contexts, we propose a novel dataset that integrates multi-image inputs with safety Chain-of-Thought (CoT) labels as fine-grained reasoning logic to improve model performance. Specifically, we introduce the Multi-Image Safety (MIS) dataset, an instruction-following dataset tailored for multi-image safety scenarios, consisting of training and test splits. Our experiments demonstrate that fine-tuning InternVL2.5-8B with MIS significantly outperforms both powerful open-source models and API-based models in challenging multi-image tasks requiring safety-related visual reasoning. This approach not only delivers exceptional safety performance but also preserves general capabilities without any trade-offs. Specifically, fine-tuning with MIS increases average accuracy by 0.83% across five general benchmarks and reduces the Attack Success Rate (ASR) on multiple safety benchmarks by a large margin. Data and Models are released under: \href{https://dripnowhy.github.io/MIS/}{\texttt{https://dripnowhy.github.io/MIS/}}
Asymmetric Reinforcing against Multi-modal Representation Bias
Jan 02, 2025



The strength of multimodal learning lies in its ability to integrate information from various sources, providing rich and comprehensive insights. However, in real-world scenarios, multi-modal systems often face the challenge of dynamic modality contributions, the dominance of different modalities may change with the environments, leading to suboptimal performance in multimodal learning. Current methods mainly enhance weak modalities to balance multimodal representation bias, which inevitably optimizes from a partialmodality perspective, easily leading to performance descending for dominant modalities. To address this problem, we propose an Asymmetric Reinforcing method against Multimodal representation bias (ARM). Our ARM dynamically reinforces the weak modalities while maintaining the ability to represent dominant modalities through conditional mutual information. Moreover, we provide an in-depth analysis that optimizing certain modalities could cause information loss and prevent leveraging the full advantages of multimodal data. By exploring the dominance and narrowing the contribution gaps between modalities, we have significantly improved the performance of multimodal learning, making notable progress in mitigating imbalanced multimodal learning.
$S^3$: Synonymous Semantic Space for Improving Zero-Shot Generalization of Vision-Language Models
Dec 06, 2024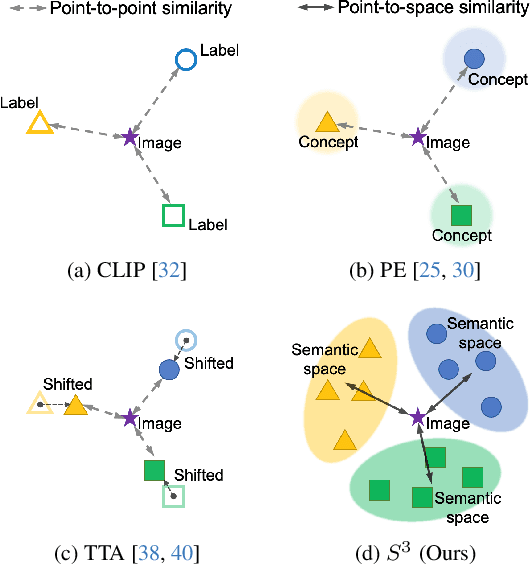
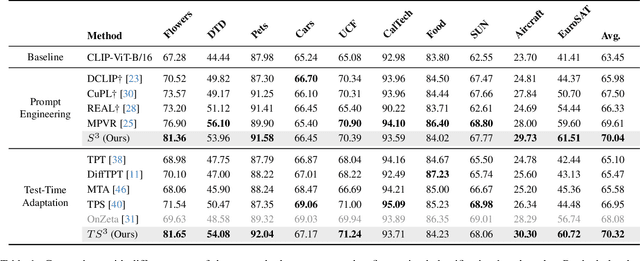
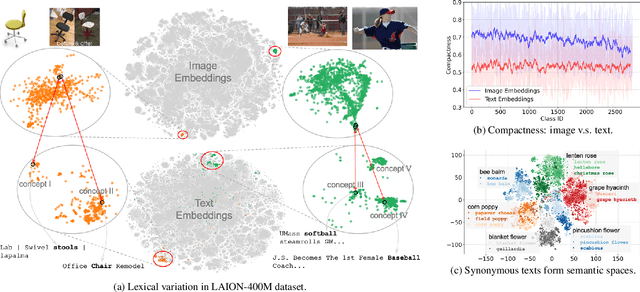
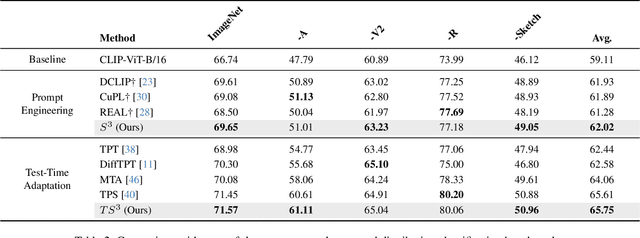
Recently, many studies have been conducted to enhance the zero-shot generalization ability of vision-language models (e.g., CLIP) by addressing the semantic misalignment between image and text embeddings in downstream tasks. Although many efforts have been made, existing methods barely consider the fact that a class of images can be described by notably different textual concepts due to well-known lexical variation in natural language processing, which heavily affects the zero-shot generalization of CLIP. Therefore, this paper proposes a \textbf{S}ynonymous \textbf{S}emantic \textbf{S}pace ($S^3$) for each image class, rather than relying on a single textual concept, achieving more stable semantic alignment and improving the zero-shot generalization of CLIP. Specifically, our $S^3$ method first generates several synonymous concepts based on the label of each class by using large language models, and constructs a continuous yet compact synonymous semantic space based on the Vietoris-Rips complex of the generated synonymous concepts. Furthermore, we explore the effect of several point-to-space metrics on our $S^3$, while presenting a point-to-local-center metric to compute similarity between image embeddings and the synonymous semantic space of each class, accomplishing effective zero-shot predictions. Extensive experiments are conducted across 17 benchmarks, including fine-grained zero-shot classification, natural distribution zero-shot classification, and open-vocabulary segmentation, and the results show that our $S^3$ outperforms state-of-the-art methods.
Efficient Masked AutoEncoder for Video Object Counting and A Large-Scale Benchmark
Nov 20, 2024



The dynamic imbalance of the fore-background is a major challenge in video object counting, which is usually caused by the sparsity of foreground objects. This often leads to severe under- and over-prediction problems and has been less studied in existing works. To tackle this issue in video object counting, we propose a density-embedded Efficient Masked Autoencoder Counting (E-MAC) framework in this paper. To effectively capture the dynamic variations across frames, we utilize an optical flow-based temporal collaborative fusion that aligns features to derive multi-frame density residuals. The counting accuracy of the current frame is boosted by harnessing the information from adjacent frames. More importantly, to empower the representation ability of dynamic foreground objects for intra-frame, we first take the density map as an auxiliary modality to perform $\mathtt{D}$ensity-$\mathtt{E}$mbedded $\mathtt{M}$asked m$\mathtt{O}$deling ($\mathtt{DEMO}$) for multimodal self-representation learning to regress density map. However, as $\mathtt{DEMO}$ contributes effective cross-modal regression guidance, it also brings in redundant background information and hard to focus on foreground regions. To handle this dilemma, we further propose an efficient spatial adaptive masking derived from density maps to boost efficiency. In addition, considering most existing datasets are limited to human-centric scenarios, we first propose a large video bird counting dataset $\textit{DroneBird}$, in natural scenarios for migratory bird protection. Extensive experiments on three crowd datasets and our $\textit{DroneBird}$ validate our superiority against the counterparts.
Dynamic Brightness Adaptation for Robust Multi-modal Image Fusion
Nov 07, 2024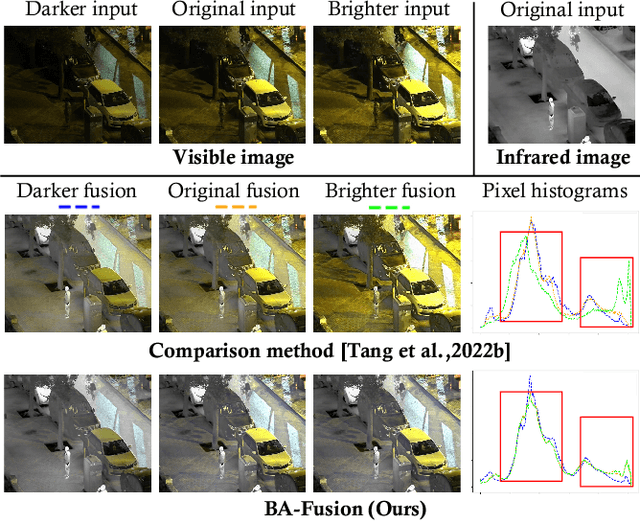
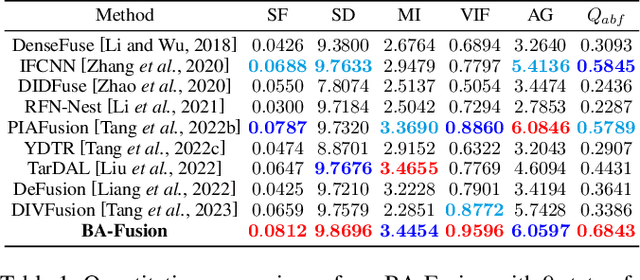

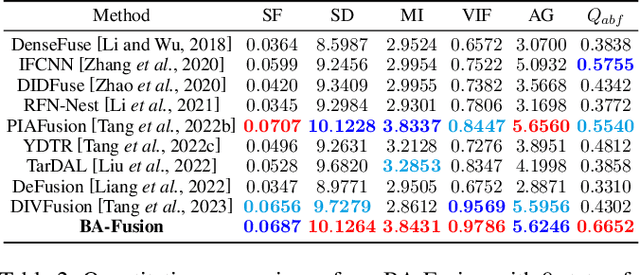
Infrared and visible image fusion aim to integrate modality strengths for visually enhanced, informative images. Visible imaging in real-world scenarios is susceptible to dynamic environmental brightness fluctuations, leading to texture degradation. Existing fusion methods lack robustness against such brightness perturbations, significantly compromising the visual fidelity of the fused imagery. To address this challenge, we propose the Brightness Adaptive multimodal dynamic fusion framework (BA-Fusion), which achieves robust image fusion despite dynamic brightness fluctuations. Specifically, we introduce a Brightness Adaptive Gate (BAG) module, which is designed to dynamically select features from brightness-related channels for normalization, while preserving brightness-independent structural information within the source images. Furthermore, we propose a brightness consistency loss function to optimize the BAG module. The entire framework is tuned via alternating training strategies. Extensive experiments validate that our method surpasses state-of-the-art methods in preserving multi-modal image information and visual fidelity, while exhibiting remarkable robustness across varying brightness levels. Our code is available: https://github.com/SunYM2020/BA-Fusion.
* Accepted by IJCAI 2024