 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Style Experts for Diverse Image Stylization
Mar 17, 2026Diffusion-based stylization has advanced significantly, yet existing methods are limited to color-driven transformations, neglecting complex semantics and material details.We introduce StyleExpert, a semantic-aware framework based on the Mixture of Experts (MoE). Our framework employs a unified style encoder, trained on our large-scale dataset of content-style-stylized triplets, to embed diverse styles into a consistent latent space. This embedding is then used to condition a similarity-aware gating mechanism, which dynamically routes styles to specialized experts within the MoE architecture. Leveraging this MoE architecture, our method adeptly handles diverse styles spanning multiple semantic levels, from shallow textures to deep semantics. Extensive experiments show that StyleExpert outperforms existing approaches in preserving semantics and material details, while generalizing to unseen styles. Our code and collected images are available at the project page: https://hh-lg.github.io/StyleExpert-Page/.
RGBX-R1: Visual Modality Chain-of-Thought Guided Reinforcement Learning for Multimodal Grounding
Jan 31, 2026Multimodal Large Language Models (MLLM) are primarily pre-trained on the RGB modality, thereby limiting their performance on other modalities, such as infrared, depth, and event data, which are crucial for complex scenarios. To address this, we propose RGBX-R1, a framework to enhance MLLM's perception and reasoning capacities across various X visual modalities. Specifically, we employ an Understand-Associate-Validate (UAV) prompting strategy to construct the Visual Modality Chain-of-Thought (VM-CoT), which aims to expand the MLLMs' RGB understanding capability into X modalities. To progressively enhance reasoning capabilities, we introduce a two-stage training paradigm: Cold-Start Supervised Fine-Tuning (CS-SFT) and Spatio-Temporal Reinforcement Fine-Tuning (ST-RFT). CS-SFT supervises the reasoning process with the guidance of VM-CoT, equipping the MLLM with fundamental modality cognition. Building upon GRPO, ST-RFT employs a Modality-understanding Spatio-Temporal (MuST) reward to reinforce modality reasoning. Notably, we construct the first RGBX-Grounding benchmark, and extensive experiments verify our superiority in multimodal understanding and spatial perception, outperforming baselines by 22.71% on three RGBX grounding tasks.
Fine-Grained Generalization via Structuralizing Concept and Feature Space into Commonality, Specificity and Confounding
Jan 06, 2026Fine-Grained Domain Generalization (FGDG) presents greater challenges than conventional domain generalization due to the subtle inter-class differences and relatively pronounced intra-class variations inherent in fine-grained recognition tasks. Under domain shifts, the model becomes overly sensitive to fine-grained cues, leading to the suppression of critical features and a significant drop in performance. Cognitive studies suggest that humans classify objects by leveraging both common and specific attributes, enabling accurate differentiation between fine-grained categories. However, current deep learning models have yet to incorporate this mechanism effectively. Inspired by this mechanism, we propose Concept-Feature Structuralized Generalization (CFSG). This model explicitly disentangles both the concept and feature spaces into three structured components: common, specific, and confounding segments. To mitigate the adverse effects of varying degrees of distribution shift, we introduce an adaptive mechanism that dynamically adjusts the proportions of common, specific, and confounding components. In the final prediction, explicit weights are assigned to each pair of components. Extensive experiments on three single-source benchmark datasets demonstrate that CFSG achieves an average performance improvement of 9.87% over baseline models and outperforms existing state-of-the-art methods by an average of 3.08%. Additionally, explainability analysis validates that CFSG effectively integrates multi-granularity structured knowledge and confirms that feature structuralization facilitates the emergence of concept structuralization.
RoomEditor++: A Parameter-Sharing Diffusion Architecture for High-Fidelity Furniture Synthesis
Dec 19, 2025Virtual furniture synthesis, which seamlessly integrates reference objects into indoor scenes while maintaining geometric coherence and visual realism, holds substantial promise for home design and e-commerce applications. However, this field remains underexplored due to the scarcity of reproducible benchmarks and the limitations of existing image composition methods in achieving high-fidelity furniture synthesis while preserving background integrity. To overcome these challenges, we first present RoomBench++, a comprehensive and publicly available benchmark dataset tailored for this task. It consists of 112,851 training pairs and 1,832 testing pairs drawn from both real-world indoor videos and realistic home design renderings, thereby supporting robust training and evaluation under practical conditions. Then, we propose RoomEditor++, a versatile diffusion-based architecture featuring a parameter-sharing dual diffusion backbone, which is compatible with both U-Net and DiT architectures. This design unifies the feature extraction and inpainting processes for reference and background images. Our in-depth analysis reveals that the parameter-sharing mechanism enforces aligned feature representations, facilitating precise geometric transformations, texture preservation, and seamless integration. Extensive experiments validate that RoomEditor++ is superior over state-of-the-art approaches in terms of quantitative metrics, qualitative assessments, and human preference studies, while highlighting its strong generalization to unseen indoor scenes and general scenes without task-specific fine-tuning. The dataset and source code are available at \url{https://github.com/stonecutter-21/roomeditor}.
Constrained Prompt Enhancement for Improving Zero-Shot Generalization of Vision-Language Models
Aug 24, 2025Vision-language models (VLMs) pre-trained on web-scale data exhibit promising zero-shot generalization but often suffer from semantic misalignment due to domain gaps between pre-training and downstream tasks. Existing approaches primarily focus on text prompting with class-specific descriptions and visual-text adaptation via aligning cropped image regions with textual descriptions. However, they still face the issues of incomplete textual prompts and noisy visual prompts. In this paper, we propose a novel constrained prompt enhancement (CPE) method to improve visual-textual alignment by constructing comprehensive textual prompts and compact visual prompts from the semantic perspective. Specifically, our approach consists of two key components: Topology-Guided Synonymous Semantic Generation (TGSSG) and Category-Agnostic Discriminative Region Selection (CADRS). Textually, to address the issue of incomplete semantic expression in textual prompts, our TGSSG first generates synonymous semantic set for each category via large language models, and constructs comprehensive textual prompts based on semantic ambiguity entropy and persistent homology analysis. Visually, to mitigate the irrelevant visual noise introduced by random cropping, our CADRS identifies discriminative regions with activation maps outputted by a pre-trained vision model, effectively filtering out noisy regions and generating compact visual prompts. Given the comprehensive set of textual prompts and compact set of visual prompts, we introduce two set-to-set matching strategies based on test-time adaptation (TTA) and optimal transport (OT) to achieve effective visual-textual alignment, and so improve zero-shot generalization of VLMs.
DALIP: Distribution Alignment-based Language-Image Pre-Training for Domain-Specific Data
Apr 02, 2025Recently, Contrastive Language-Image Pre-training (CLIP) has shown promising performance in domain-specific data (e.g., biology), and has attracted increasing research attention. Existing works generally focus on collecting extensive domain-specific data and directly tuning the original CLIP models. Intuitively, such a paradigm takes no full consideration of the characteristics lying in domain-specific data (e.g., fine-grained nature of biological data) and so limits model capability, while mostly losing the original ability of CLIP in the general domain. In this paper, we propose a Distribution Alignment-based Language-Image Pre-Training (DALIP) method for biological data. Specifically, DALIP optimizes CLIP models by matching the similarity between feature distribution of image-text pairs instead of the original [cls] token, which can capture rich yet effective information inherent in image-text pairs as powerful representations, and so better cope with fine-grained nature of biological data. Particularly, our DALIP efficiently approximates feature distribution via its first- and second-order statistics, while presenting a Multi-head Brownian Distance Covariance (MBDC) module to acquire second-order statistics of token features efficiently. Furthermore, we collect a new dataset for plant domain (e.g., specific data in biological domain) comprising 10M plant data with 3M general-domain data (namely PlantMix-13M) according to data mixing laws. Extensive experiments show that DALIP clearly outperforms existing CLIP counterparts in biological domain, while well generalizing to remote sensing and medical imaging domains. Besides, our PlantMix-13M dataset further boosts performance of DALIP in plant domain, while preserving model ability in general domain.
CoE: Chain-of-Explanation via Automatic Visual Concept Circuit Description and Polysemanticity Quantification
Mar 19, 2025Explainability is a critical factor influencing the wide deployment of deep vision models (DVMs). Concept-based post-hoc explanation methods can provide both global and local insights into model decisions. However, current methods in this field face challenges in that they are inflexible to automatically construct accurate and sufficient linguistic explanations for global concepts and local circuits. Particularly, the intrinsic polysemanticity in semantic Visual Concepts (VCs) impedes the interpretability of concepts and DVMs, which is underestimated severely. In this paper, we propose a Chain-of-Explanation (CoE) approach to address these issues. Specifically, CoE automates the decoding and description of VCs to construct global concept explanation datasets. Further, to alleviate the effect of polysemanticity on model explainability, we design a concept polysemanticity disentanglement and filtering mechanism to distinguish the most contextually relevant concept atoms. Besides, a Concept Polysemanticity Entropy (CPE), as a measure of model interpretability, is formulated to quantify the degree of concept uncertainty. The modeling of deterministic concepts is upgraded to uncertain concept atom distributions. Finally, CoE automatically enables linguistic local explanations of the decision-making process of DVMs by tracing the concept circuit. GPT-4o and human-based experiments demonstrate the effectiveness of CPE and the superiority of CoE, achieving an average absolute improvement of 36% in terms of explainability scores.
Unprejudiced Training Auxiliary Tasks Makes Primary Better: A Multi-Task Learning Perspective
Dec 27, 2024Human beings can leverage knowledge from relative tasks to improve learning on a primary task. Similarly, multi-task learning methods suggest using auxiliary tasks to enhance a neural network's performance on a specific primary task. However, previous methods often select auxiliary tasks carefully but treat them as secondary during training. The weights assigned to auxiliary losses are typically smaller than the primary loss weight, leading to insufficient training on auxiliary tasks and ultimately failing to support the main task effectively. To address this issue, we propose an uncertainty-based impartial learning method that ensures balanced training across all tasks. Additionally, we consider both gradients and uncertainty information during backpropagation to further improve performance on the primary task. Extensive experiments show that our method achieves performance comparable to or better than state-of-the-art approaches. Moreover, our weighting strategy is effective and robust in enhancing the performance of the primary task regardless the noise auxiliary tasks' pseudo labels.
Generative Inbetweening through Frame-wise Conditions-Driven Video Generation
Dec 16, 2024



Generative inbetweening aims to generate intermediate frame sequences by utilizing two key frames as input. Although remarkable progress has been made in video generation models, generative inbetweening still faces challenges in maintaining temporal stability due to the ambiguous interpolation path between two key frames. This issue becomes particularly severe when there is a large motion gap between input frames. In this paper, we propose a straightforward yet highly effective Frame-wise Conditions-driven Video Generation (FCVG) method that significantly enhances the temporal stability of interpolated video frames. Specifically, our FCVG provides an explicit condition for each frame, making it much easier to identify the interpolation path between two input frames and thus ensuring temporally stable production of visually plausible video frames. To achieve this, we suggest extracting matched lines from two input frames that can then be easily interpolated frame by frame, serving as frame-wise conditions seamlessly integrated into existing video generation models. In extensive evaluations covering diverse scenarios such as natural landscapes, complex human poses, camera movements and animations, existing methods often exhibit incoherent transitions across frames. In contrast, our FCVG demonstrates the capability to generate temporally stable videos using both linear and non-linear interpolation curves. Our project page and code are available at \url{https://fcvg-inbetween.github.io/}.
$S^3$: Synonymous Semantic Space for Improving Zero-Shot Generalization of Vision-Language Models
Dec 06, 2024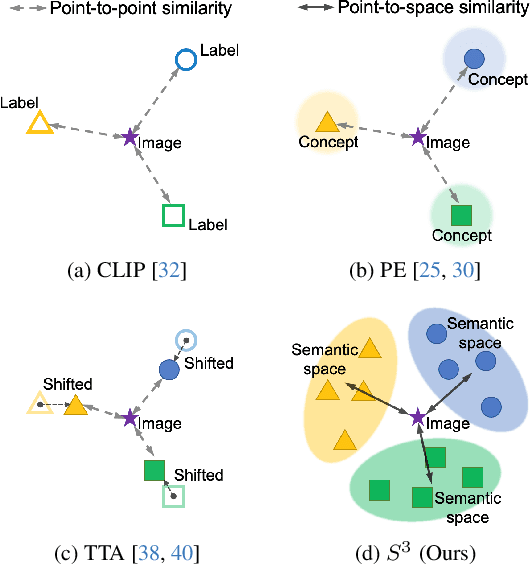
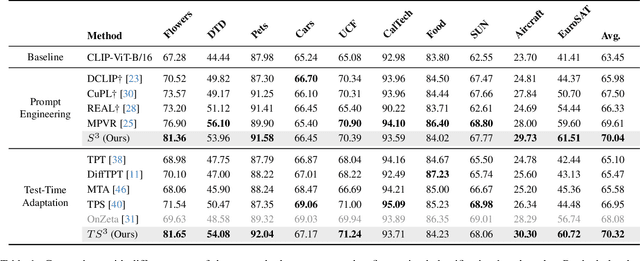
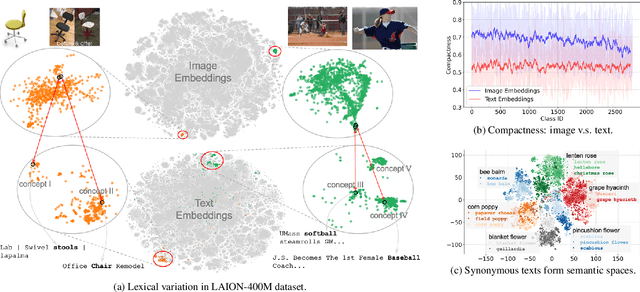
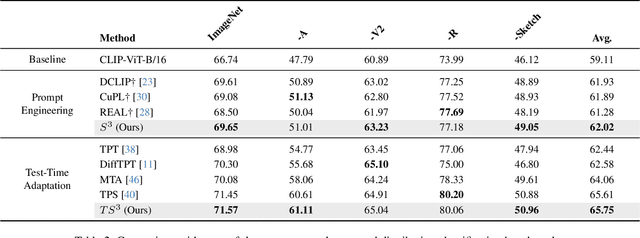
Recently, many studies have been conducted to enhance the zero-shot generalization ability of vision-language models (e.g., CLIP) by addressing the semantic misalignment between image and text embeddings in downstream tasks. Although many efforts have been made, existing methods barely consider the fact that a class of images can be described by notably different textual concepts due to well-known lexical variation in natural language processing, which heavily affects the zero-shot generalization of CLIP. Therefore, this paper proposes a \textbf{S}ynonymous \textbf{S}emantic \textbf{S}pace ($S^3$) for each image class, rather than relying on a single textual concept, achieving more stable semantic alignment and improving the zero-shot generalization of CLIP. Specifically, our $S^3$ method first generates several synonymous concepts based on the label of each class by using large language models, and constructs a continuous yet compact synonymous semantic space based on the Vietoris-Rips complex of the generated synonymous concepts. Furthermore, we explore the effect of several point-to-space metrics on our $S^3$, while presenting a point-to-local-center metric to compute similarity between image embeddings and the synonymous semantic space of each class, accomplishing effective zero-shot predictions. Extensive experiments are conducted across 17 benchmarks, including fine-grained zero-shot classification, natural distribution zero-shot classification, and open-vocabulary segmentation, and the results show that our $S^3$ outperforms state-of-the-art methods.