 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCREval: An Automated Interpretable Evaluation for Creative Image Manipulation under Complex Instructions
Mar 27, 2026Instruction-based multimodal image manipulation has recently made rapid progress. However, existing evaluation methods lack a systematic and human-aligned framework for assessing model performance on complex and creative editing tasks. To address this gap, we propose CREval, a fully automated question-answer (QA)-based evaluation pipeline that overcomes the incompleteness and poor interpretability of opaque Multimodal Large Language Models (MLLMs) scoring. Simultaneously, we introduce CREval-Bench, a comprehensive benchmark specifically designed for creative image manipulation under complex instructions. CREval-Bench covers three categories and nine creative dimensions, comprising over 800 editing samples and 13K evaluation queries. Leveraging this pipeline and benchmark, we systematically evaluate a diverse set of state-of-the-art open and closed-source models. The results reveal that while closed-source models generally outperform open-source ones on complex and creative tasks, all models still struggle to complete such edits effectively. In addition, user studies demonstrate strong consistency between CREval's automated metrics and human judgments. Therefore, CREval provides a reliable foundation for evaluating image editing models on complex and creative image manipulation tasks, and highlights key challenges and opportunities for future research.
MiM-DiT: MoE in MoE with Diffusion Transformers for All-in-One Image Restoration
Mar 03, 2026All-in-one image restoration is challenging because different degradation types, such as haze, blur, noise, and low-light, impose diverse requirements on restoration strategies, making it difficult for a single model to handle them effectively. In this paper, we propose a unified image restoration framework that integrates a dual-level Mixture-of-Experts (MoE) architecture with a pretrained diffusion model. The framework operates at two levels: the Inter-MoE layer adaptively combines expert groups to handle major degradation types, while the Intra-MoE layer further selects specialized sub-experts to address fine-grained variations within each type. This design enables the model to achieve coarse-grained adaptation across diverse degradation categories while performing fine-grained modulation for specific intra-class variations, ensuring both high specialization in handling complex, real-world corruptions. Extensive experiments demonstrate that the proposed method performs favorably against the state-of-the-art approaches on multiple image restoration task.
SelfHVD: Self-Supervised Handheld Video Deblurring for Mobile Phones
Aug 12, 2025Shooting video with a handheld mobile phone, the most common photographic device, often results in blurry frames due to shaking hands and other instability factors. Although previous video deblurring methods have achieved impressive progress, they still struggle to perform satisfactorily on real-world handheld video due to the blur domain gap between training and testing data. To address the issue, we propose a self-supervised method for handheld video deblurring, which is driven by sharp clues in the video. First, to train the deblurring model, we extract the sharp clues from the video and take them as misalignment labels of neighboring blurry frames. Second, to improve the model's ability, we propose a novel Self-Enhanced Video Deblurring (SEVD) method to create higher-quality paired video data. Third, we propose a Self-Constrained Spatial Consistency Maintenance (SCSCM) method to regularize the model, preventing position shifts between the output and input frames. Moreover, we construct a synthetic and a real-world handheld video dataset for handheld video deblurring. Extensive experiments on these two and other common real-world datasets demonstrate that our method significantly outperforms existing self-supervised ones. The code and datasets are publicly available at https://github.com/cshonglei/SelfHVD.
Image Demoiréing Using Dual Camera Fusion on Mobile Phones
Jun 10, 2025When shooting electronic screens, moir\'e patterns usually appear in captured images, which seriously affects the image quality. Existing image demoir\'eing methods face great challenges in removing large and heavy moir\'e. To address the issue, we propose to utilize Dual Camera fusion for Image Demoir\'eing (DCID), \ie, using the ultra-wide-angle (UW) image to assist the moir\'e removal of wide-angle (W) image. This is inspired by two motivations: (1) the two lenses are commonly equipped with modern smartphones, (2) the UW image generally can provide normal colors and textures when moir\'e exists in the W image mainly due to their different focal lengths. In particular, we propose an efficient DCID method, where a lightweight UW image encoder is integrated into an existing demoir\'eing network and a fast two-stage image alignment manner is present. Moreover, we construct a large-scale real-world dataset with diverse mobile phones and monitors, containing about 9,000 samples. Experiments on the dataset show our method performs better than state-of-the-art methods. Code and dataset are available at https://github.com/Mrduckk/DCID.
Pseudo-Label Guided Real-World Image De-weathering: A Learning Framework with Imperfect Supervision
Apr 14, 2025
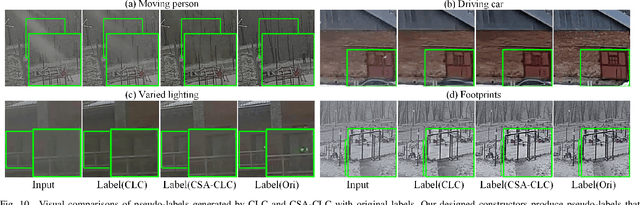

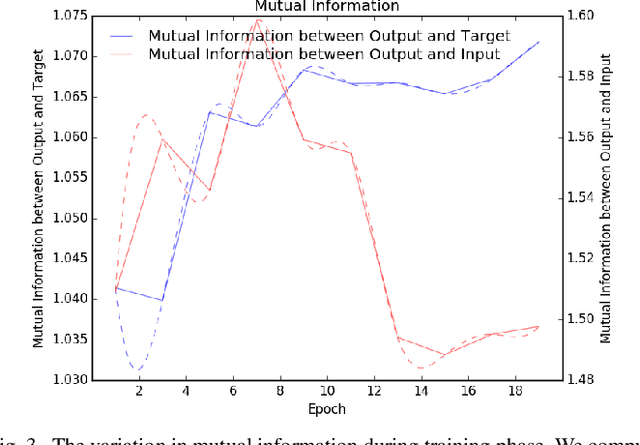
Real-world image de-weathering aims at removingvarious undesirable weather-related artifacts, e.g., rain, snow,and fog. To this end, acquiring ideal training pairs is crucial.Existing real-world datasets are typically constructed paired databy extracting clean and degraded images from live streamsof landscape scene on the Internet. Despite the use of strictfiltering mechanisms during collection, training pairs inevitablyencounter inconsistency in terms of lighting, object position, scenedetails, etc, making de-weathering models possibly suffer fromdeformation artifacts under non-ideal supervision. In this work,we propose a unified solution for real-world image de-weatheringwith non-ideal supervision, i.e., a pseudo-label guided learningframework, to address various inconsistencies within the realworld paired dataset. Generally, it consists of a de-weatheringmodel (De-W) and a Consistent Label Constructor (CLC), bywhich restoration result can be adaptively supervised by originalground-truth image to recover sharp textures while maintainingconsistency with the degraded inputs in non-weather contentthrough the supervision of pseudo-labels. Particularly, a Crossframe Similarity Aggregation (CSA) module is deployed withinCLC to enhance the quality of pseudo-labels by exploring thepotential complementary information of multi-frames throughgraph model. Moreover, we introduce an Information AllocationStrategy (IAS) to integrate the original ground-truth imagesand pseudo-labels, thereby facilitating the joint supervision forthe training of de-weathering model. Extensive experimentsdemonstrate that our method exhibits significant advantageswhen trained on imperfectly aligned de-weathering datasets incomparison with other approaches.
DeblurDiff: Real-World Image Deblurring with Generative Diffusion Models
Feb 06, 2025



Diffusion models have achieved significant progress in image generation. The pre-trained Stable Diffusion (SD) models are helpful for image deblurring by providing clear image priors. However, directly using a blurry image or pre-deblurred one as a conditional control for SD will either hinder accurate structure extraction or make the results overly dependent on the deblurring network. In this work, we propose a Latent Kernel Prediction Network (LKPN) to achieve robust real-world image deblurring. Specifically, we co-train the LKPN in latent space with conditional diffusion. The LKPN learns a spatially variant kernel to guide the restoration of sharp images in the latent space. By applying element-wise adaptive convolution (EAC), the learned kernel is utilized to adaptively process the input feature, effectively preserving the structural information of the input. This process thereby more effectively guides the generative process of Stable Diffusion (SD), enhancing both the deblurring efficacy and the quality of detail reconstruction. Moreover, the results at each diffusion step are utilized to iteratively estimate the kernels in LKPN to better restore the sharp latent by EAC. This iterative refinement enhances the accuracy and robustness of the deblurring process. Extensive experimental results demonstrate that the proposed method outperforms state-of-the-art image deblurring methods on both benchmark and real-world images.
Generative Inbetweening through Frame-wise Conditions-Driven Video Generation
Dec 16, 2024



Generative inbetweening aims to generate intermediate frame sequences by utilizing two key frames as input. Although remarkable progress has been made in video generation models, generative inbetweening still faces challenges in maintaining temporal stability due to the ambiguous interpolation path between two key frames. This issue becomes particularly severe when there is a large motion gap between input frames. In this paper, we propose a straightforward yet highly effective Frame-wise Conditions-driven Video Generation (FCVG) method that significantly enhances the temporal stability of interpolated video frames. Specifically, our FCVG provides an explicit condition for each frame, making it much easier to identify the interpolation path between two input frames and thus ensuring temporally stable production of visually plausible video frames. To achieve this, we suggest extracting matched lines from two input frames that can then be easily interpolated frame by frame, serving as frame-wise conditions seamlessly integrated into existing video generation models. In extensive evaluations covering diverse scenarios such as natural landscapes, complex human poses, camera movements and animations, existing methods often exhibit incoherent transitions across frames. In contrast, our FCVG demonstrates the capability to generate temporally stable videos using both linear and non-linear interpolation curves. Our project page and code are available at \url{https://fcvg-inbetween.github.io/}.
Seeing Beyond Views: Multi-View Driving Scene Video Generation with Holistic Attention
Dec 04, 2024
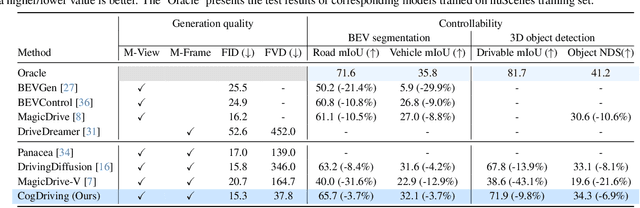


Generating multi-view videos for autonomous driving training has recently gained much attention, with the challenge of addressing both cross-view and cross-frame consistency. Existing methods typically apply decoupled attention mechanisms for spatial, temporal, and view dimensions. However, these approaches often struggle to maintain consistency across dimensions, particularly when handling fast-moving objects that appear at different times and viewpoints. In this paper, we present CogDriving, a novel network designed for synthesizing high-quality multi-view driving videos. CogDriving leverages a Diffusion Transformer architecture with holistic-4D attention modules, enabling simultaneous associations across the spatial, temporal, and viewpoint dimensions. We also propose a lightweight controller tailored for CogDriving, i.e., Micro-Controller, which uses only 1.1% of the parameters of the standard ControlNet, enabling precise control over Bird's-Eye-View layouts. To enhance the generation of object instances crucial for autonomous driving, we propose a re-weighted learning objective, dynamically adjusting the learning weights for object instances during training. CogDriving demonstrates strong performance on the nuScenes validation set, achieving an FVD score of 37.8, highlighting its ability to generate realistic driving videos. The project can be found at https://luhannan.github.io/CogDrivingPage/.
Reblurring-Guided Single Image Defocus Deblurring: A Learning Framework with Misaligned Training Pairs
Sep 26, 2024
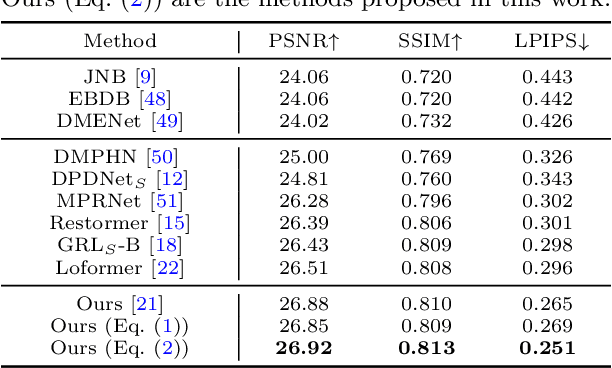
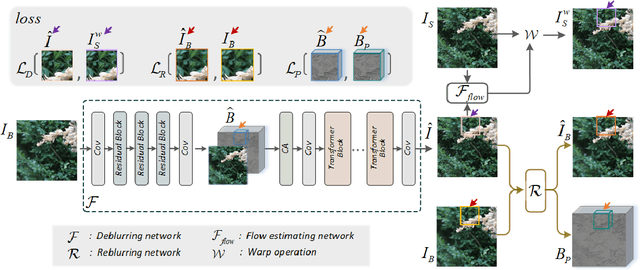
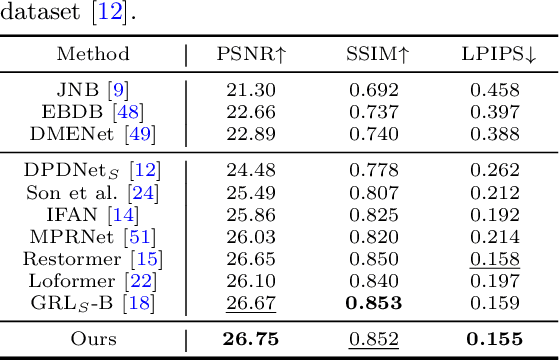
For single image defocus deblurring, acquiring well-aligned training pairs (or training triplets), i.e., a defocus blurry image, an all-in-focus sharp image (and a defocus blur map), is an intricate task for the development of deblurring models. Existing image defocus deblurring methods typically rely on training data collected by specialized imaging equipment, presupposing that these pairs or triplets are perfectly aligned. However, in practical scenarios involving the collection of real-world data, direct acquisition of training triplets is infeasible, and training pairs inevitably encounter spatial misalignment issues. In this work, we introduce a reblurring-guided learning framework for single image defocus deblurring, enabling the learning of a deblurring network even with misaligned training pairs. Specifically, we first propose a baseline defocus deblurring network that utilizes spatially varying defocus blur map as degradation prior to enhance the deblurring performance. Then, to effectively learn the baseline defocus deblurring network with misaligned training pairs, our reblurring module ensures spatial consistency between the deblurred image, the reblurred image and the input blurry image by reconstructing spatially variant isotropic blur kernels. Moreover, the spatially variant blur derived from the reblurring module can serve as pseudo supervision for defocus blur map during training, interestingly transforming training pairs into training triplets. Additionally, we have collected a new dataset specifically for single image defocus deblurring (SDD) with typical misalignments, which not only substantiates our proposed method but also serves as a benchmark for future research.
MC$^2$: Multi-concept Guidance for Customized Multi-concept Generation
Apr 12, 2024Customized text-to-image generation aims to synthesize instantiations of user-specified concepts and has achieved unprecedented progress in handling individual concept. However, when extending to multiple customized concepts, existing methods exhibit limitations in terms of flexibility and fidelity, only accommodating the combination of limited types of models and potentially resulting in a mix of characteristics from different concepts. In this paper, we introduce the Multi-concept guidance for Multi-concept customization, termed MC$^2$, for improved flexibility and fidelity. MC$^2$ decouples the requirements for model architecture via inference time optimization, allowing the integration of various heterogeneous single-concept customized models. It adaptively refines the attention weights between visual and textual tokens, directing image regions to focus on their associated words while diminishing the impact of irrelevant ones. Extensive experiments demonstrate that MC$^2$ even surpasses previous methods that require additional training in terms of consistency with input prompt and reference images. Moreover, MC$^2$ can be extended to elevate the compositional capabilities of text-to-image generation, yielding appealing results. Code will be publicly available at https://github.com/JIANGJiaXiu/MC-2.