 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamLite: A Lightweight On-Device Unified Model for Image Generation and Editing
Mar 30, 2026Diffusion models have made significant progress in both text-to-image (T2I) generation and text-guided image editing. However, these models are typically built with billions of parameters, leading to high latency and increased deployment challenges. While on-device diffusion models improve efficiency, they largely focus on T2I generation and lack support for image editing. In this paper, we propose DreamLite, a compact unified on-device diffusion model (0.39B) that supports both T2I generation and text-guided image editing within a single network. DreamLite is built on a pruned mobile U-Net backbone and unifies conditioning through in-context spatial concatenation in the latent space. It concatenates images horizontally as input, using a (target | blank) configuration for generation tasks and (target | source) for editing tasks. To stabilize the training of this compact model, we introduce a task-progressive joint pretraining strategy that sequentially targets T2I, editing, and joint tasks. After high-quality SFT and reinforcement learning, DreamLite achieves GenEval (0.72) for image generation and ImgEdit (4.11) for image editing, outperforming existing on-device models and remaining competitive with several server-side models. By employing step distillation, we further reduce denoising processing to just 4 steps, enabling our DreamLite could generate or edit a 1024 x 1024 image in less than 1s on a Xiaomi 14 smartphone. To the best of our knowledge, DreamLite is the first unified on-device diffusion model that supports both image generation and image editing.
VitaGlyph: Vitalizing Artistic Typography with Flexible Dual-branch Diffusion Models
Oct 02, 2024



Artistic typography is a technique to visualize the meaning of input character in an imaginable and readable manner. With powerful text-to-image diffusion models, existing methods directly design the overall geometry and texture of input character, making it challenging to ensure both creativity and legibility. In this paper, we introduce a dual-branch and training-free method, namely VitaGlyph, enabling flexible artistic typography along with controllable geometry change to maintain the readability. The key insight of VitaGlyph is to treat input character as a scene composed of Subject and Surrounding, followed by rendering them under varying degrees of geometry transformation. The subject flexibly expresses the essential concept of input character, while the surrounding enriches relevant background without altering the shape. Specifically, we implement VitaGlyph through a three-phase framework: (i) Knowledge Acquisition leverages large language models to design text descriptions of subject and surrounding. (ii) Regional decomposition detects the part that most matches the subject description and divides input glyph image into subject and surrounding regions. (iii) Typography Stylization firstly refines the structure of subject region via Semantic Typography, and then separately renders the textures of Subject and Surrounding regions through Controllable Compositional Generation. Experimental results demonstrate that VitaGlyph not only achieves better artistry and readability, but also manages to depict multiple customize concepts, facilitating more creative and pleasing artistic typography generation. Our code will be made publicly at https://github.com/Carlofkl/VitaGlyph.
MC$^2$: Multi-concept Guidance for Customized Multi-concept Generation
Apr 12, 2024Customized text-to-image generation aims to synthesize instantiations of user-specified concepts and has achieved unprecedented progress in handling individual concept. However, when extending to multiple customized concepts, existing methods exhibit limitations in terms of flexibility and fidelity, only accommodating the combination of limited types of models and potentially resulting in a mix of characteristics from different concepts. In this paper, we introduce the Multi-concept guidance for Multi-concept customization, termed MC$^2$, for improved flexibility and fidelity. MC$^2$ decouples the requirements for model architecture via inference time optimization, allowing the integration of various heterogeneous single-concept customized models. It adaptively refines the attention weights between visual and textual tokens, directing image regions to focus on their associated words while diminishing the impact of irrelevant ones. Extensive experiments demonstrate that MC$^2$ even surpasses previous methods that require additional training in terms of consistency with input prompt and reference images. Moreover, MC$^2$ can be extended to elevate the compositional capabilities of text-to-image generation, yielding appealing results. Code will be publicly available at https://github.com/JIANGJiaXiu/MC-2.
Ref-Diff: Zero-shot Referring Image Segmentation with Generative Models
Sep 01, 2023Zero-shot referring image segmentation is a challenging task because it aims to find an instance segmentation mask based on the given referring descriptions, without training on this type of paired data. Current zero-shot methods mainly focus on using pre-trained discriminative models (e.g., CLIP). However, we have observed that generative models (e.g., Stable Diffusion) have potentially understood the relationships between various visual elements and text descriptions, which are rarely investigated in this task. In this work, we introduce a novel Referring Diffusional segmentor (Ref-Diff) for this task, which leverages the fine-grained multi-modal information from generative models. We demonstrate that without a proposal generator, a generative model alone can achieve comparable performance to existing SOTA weakly-supervised models. When we combine both generative and discriminative models, our Ref-Diff outperforms these competing methods by a significant margin. This indicates that generative models are also beneficial for this task and can complement discriminative models for better referring segmentation. Our code is publicly available at https://github.com/kodenii/Ref-Diff.
ImaginaryNet: Learning Object Detectors without Real Images and Annotations
Oct 13, 2022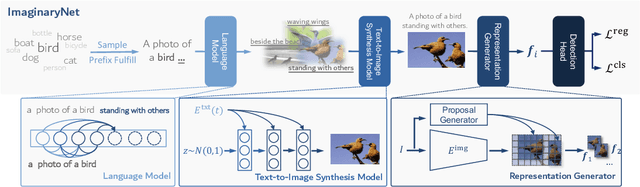
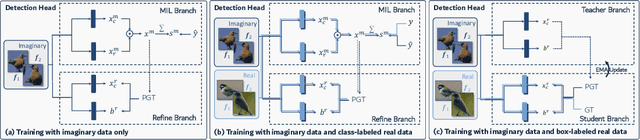

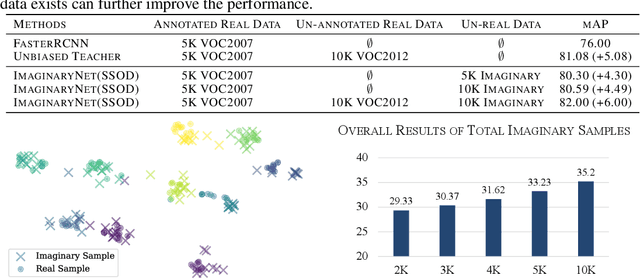
Without the demand of training in reality, humans can easily detect a known concept simply based on its language description. Empowering deep learning with this ability undoubtedly enables the neural network to handle complex vision tasks, e.g., object detection, without collecting and annotating real images. To this end, this paper introduces a novel challenging learning paradigm Imaginary-Supervised Object Detection (ISOD), where neither real images nor manual annotations are allowed for training object detectors. To resolve this challenge, we propose ImaginaryNet, a framework to synthesize images by combining pretrained language model and text-to-image synthesis model. Given a class label, the language model is used to generate a full description of a scene with a target object, and the text-to-image model deployed to generate a photo-realistic image. With the synthesized images and class labels, weakly supervised object detection can then be leveraged to accomplish ISOD. By gradually introducing real images and manual annotations, ImaginaryNet can collaborate with other supervision settings to further boost detection performance. Experiments show that ImaginaryNet can (i) obtain about 70% performance in ISOD compared with the weakly supervised counterpart of the same backbone trained on real data, (ii) significantly improve the baseline while achieving state-of-the-art or comparable performance by incorporating ImaginaryNet with other supervision settings.