 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoViC: Efficient Long Video Generation with Context Compression
Jul 17, 2025

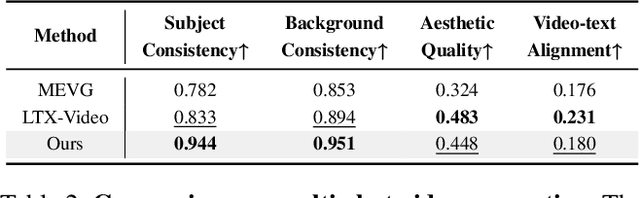

Despite recent advances in diffusion transformers (DiTs) for text-to-video generation, scaling to long-duration content remains challenging due to the quadratic complexity of self-attention. While prior efforts -- such as sparse attention and temporally autoregressive models -- offer partial relief, they often compromise temporal coherence or scalability. We introduce LoViC, a DiT-based framework trained on million-scale open-domain videos, designed to produce long, coherent videos through a segment-wise generation process. At the core of our approach is FlexFormer, an expressive autoencoder that jointly compresses video and text into unified latent representations. It supports variable-length inputs with linearly adjustable compression rates, enabled by a single query token design based on the Q-Former architecture. Additionally, by encoding temporal context through position-aware mechanisms, our model seamlessly supports prediction, retradiction, interpolation, and multi-shot generation within a unified paradigm. Extensive experiments across diverse tasks validate the effectiveness and versatility of our approach.
MC$^2$: Multi-concept Guidance for Customized Multi-concept Generation
Apr 12, 2024Customized text-to-image generation aims to synthesize instantiations of user-specified concepts and has achieved unprecedented progress in handling individual concept. However, when extending to multiple customized concepts, existing methods exhibit limitations in terms of flexibility and fidelity, only accommodating the combination of limited types of models and potentially resulting in a mix of characteristics from different concepts. In this paper, we introduce the Multi-concept guidance for Multi-concept customization, termed MC$^2$, for improved flexibility and fidelity. MC$^2$ decouples the requirements for model architecture via inference time optimization, allowing the integration of various heterogeneous single-concept customized models. It adaptively refines the attention weights between visual and textual tokens, directing image regions to focus on their associated words while diminishing the impact of irrelevant ones. Extensive experiments demonstrate that MC$^2$ even surpasses previous methods that require additional training in terms of consistency with input prompt and reference images. Moreover, MC$^2$ can be extended to elevate the compositional capabilities of text-to-image generation, yielding appealing results. Code will be publicly available at https://github.com/JIANGJiaXiu/MC-2.