 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating clinical reasoning into large language model-based diagnosis through etiology-aware attention steering
Aug 01, 2025Objective: Large Language Models (LLMs) demonstrate significant capabilities in medical text understanding and generation. However, their diagnostic reliability in complex clinical scenarios remains limited. This study aims to enhance LLMs' diagnostic accuracy and clinical reasoning ability. Method: We propose an Etiology-Aware Attention Steering Framework to integrate structured clinical reasoning into LLM-based diagnosis. Specifically, we first construct Clinical Reasoning Scaffolding (CRS) based on authoritative clinical guidelines for three representative acute abdominal emergencies: acute appendicitis, acute pancreatitis, and acute cholecystitis. Next, we develop the Etiology-Aware Head Identification algorithm to pinpoint attention heads crucial for the model's etiology reasoning. To ensure reliable clinical reasoning alignment, we introduce the Reasoning-Guided Parameter-Efficient Fine-tuning that embeds etiological reasoning cues into input representations and steers the selected Etiology-Aware Heads toward critical information through a Reasoning-Guided Loss function. Result: On the Consistent Diagnosis Cohort, our framework improves average diagnostic accuracy by 15.65% and boosts the average Reasoning Focus Score by 31.6% over baselines. External validation on the Discrepant Diagnosis Cohort further confirms its effectiveness in enhancing diagnostic accuracy. Further assessments via Reasoning Attention Frequency indicate that our models exhibit enhanced reliability when faced with real-world complex scenarios. Conclusion: This study presents a practical and effective approach to enhance clinical reasoning in LLM-based diagnosis. By aligning model attention with structured CRS, the proposed framework offers a promising paradigm for building more interpretable and reliable AI diagnostic systems in complex clinical settings.
LoViC: Efficient Long Video Generation with Context Compression
Jul 17, 2025


Despite recent advances in diffusion transformers (DiTs) for text-to-video generation, scaling to long-duration content remains challenging due to the quadratic complexity of self-attention. While prior efforts -- such as sparse attention and temporally autoregressive models -- offer partial relief, they often compromise temporal coherence or scalability. We introduce LoViC, a DiT-based framework trained on million-scale open-domain videos, designed to produce long, coherent videos through a segment-wise generation process. At the core of our approach is FlexFormer, an expressive autoencoder that jointly compresses video and text into unified latent representations. It supports variable-length inputs with linearly adjustable compression rates, enabled by a single query token design based on the Q-Former architecture. Additionally, by encoding temporal context through position-aware mechanisms, our model seamlessly supports prediction, retradiction, interpolation, and multi-shot generation within a unified paradigm. Extensive experiments across diverse tasks validate the effectiveness and versatility of our approach.
Turbo2K: Towards Ultra-Efficient and High-Quality 2K Video Synthesis
Apr 20, 2025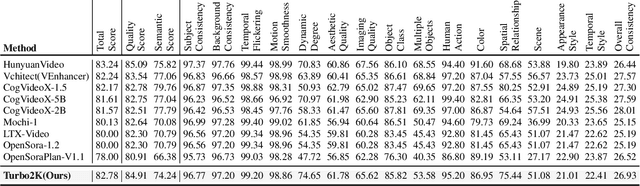

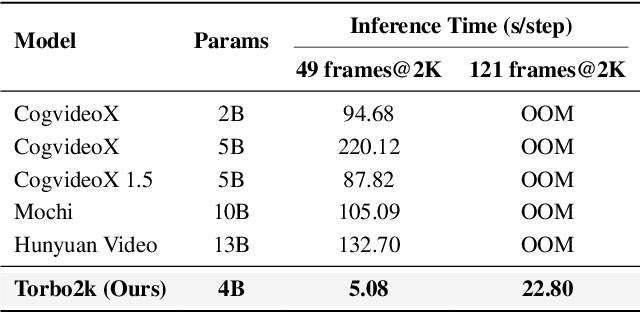

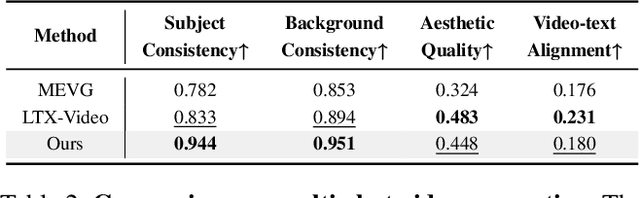
Demand for 2K video synthesis is rising with increasing consumer expectations for ultra-clear visuals. While diffusion transformers (DiTs) have demonstrated remarkable capabilities in high-quality video generation, scaling them to 2K resolution remains computationally prohibitive due to quadratic growth in memory and processing costs. In this work, we propose Turbo2K, an efficient and practical framework for generating detail-rich 2K videos while significantly improving training and inference efficiency. First, Turbo2K operates in a highly compressed latent space, reducing computational complexity and memory footprint, making high-resolution video synthesis feasible. However, the high compression ratio of the VAE and limited model size impose constraints on generative quality. To mitigate this, we introduce a knowledge distillation strategy that enables a smaller student model to inherit the generative capacity of a larger, more powerful teacher model. Our analysis reveals that, despite differences in latent spaces and architectures, DiTs exhibit structural similarities in their internal representations, facilitating effective knowledge transfer. Second, we design a hierarchical two-stage synthesis framework that first generates multi-level feature at lower resolutions before guiding high-resolution video generation. This approach ensures structural coherence and fine-grained detail refinement while eliminating redundant encoding-decoding overhead, further enhancing computational efficiency.Turbo2K achieves state-of-the-art efficiency, generating 5-second, 24fps, 2K videos with significantly reduced computational cost. Compared to existing methods, Turbo2K is up to 20$\times$ faster for inference, making high-resolution video generation more scalable and practical for real-world applications.
POSTA: A Go-to Framework for Customized Artistic Poster Generation
Mar 19, 2025


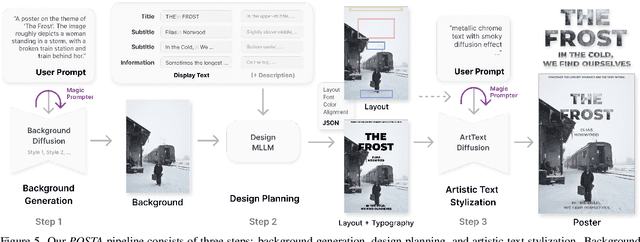
Poster design is a critical medium for visual communication. Prior work has explored automatic poster design using deep learning techniques, but these approaches lack text accuracy, user customization, and aesthetic appeal, limiting their applicability in artistic domains such as movies and exhibitions, where both clear content delivery and visual impact are essential. To address these limitations, we present POSTA: a modular framework powered by diffusion models and multimodal large language models (MLLMs) for customized artistic poster generation. The framework consists of three modules. Background Diffusion creates a themed background based on user input. Design MLLM then generates layout and typography elements that align with and complement the background style. Finally, to enhance the poster's aesthetic appeal, ArtText Diffusion applies additional stylization to key text elements. The final result is a visually cohesive and appealing poster, with a fully modular process that allows for complete customization. To train our models, we develop the PosterArt dataset, comprising high-quality artistic posters annotated with layout, typography, and pixel-level stylized text segmentation. Our comprehensive experimental analysis demonstrates POSTA's exceptional controllability and design diversity, outperforming existing models in both text accuracy and aesthetic quality.
Semi-Supervised Video Desnowing Network via Temporal Decoupling Experts and Distribution-Driven Contrastive Regularization
Oct 10, 2024



Snow degradations present formidable challenges to the advancement of computer vision tasks by the undesirable corruption in outdoor scenarios. While current deep learning-based desnowing approaches achieve success on synthetic benchmark datasets, they struggle to restore out-of-distribution real-world snowy videos due to the deficiency of paired real-world training data. To address this bottleneck, we devise a new paradigm for video desnowing in a semi-supervised spirit to involve unlabeled real data for the generalizable snow removal. Specifically, we construct a real-world dataset with 85 snowy videos, and then present a Semi-supervised Video Desnowing Network (SemiVDN) equipped by a novel Distribution-driven Contrastive Regularization. The elaborated contrastive regularization mitigates the distribution gap between the synthetic and real data, and consequently maintains the desired snow-invariant background details. Furthermore, based on the atmospheric scattering model, we introduce a Prior-guided Temporal Decoupling Experts module to decompose the physical components that make up a snowy video in a frame-correlated manner. We evaluate our SemiVDN on benchmark datasets and the collected real snowy data. The experimental results demonstrate the superiority of our approach against state-of-the-art image- and video-level desnowing methods.
HiFiSeg: High-Frequency Information Enhanced Polyp Segmentation with Global-Local Vision Transformer
Oct 03, 2024
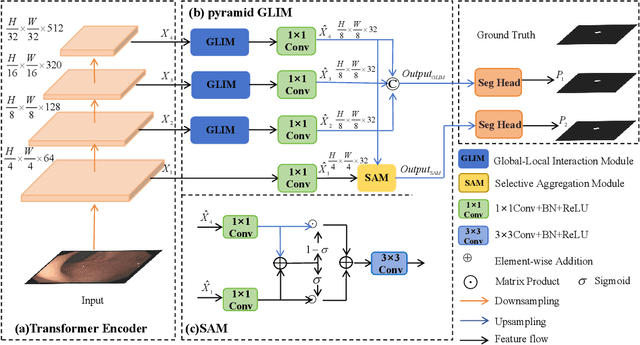
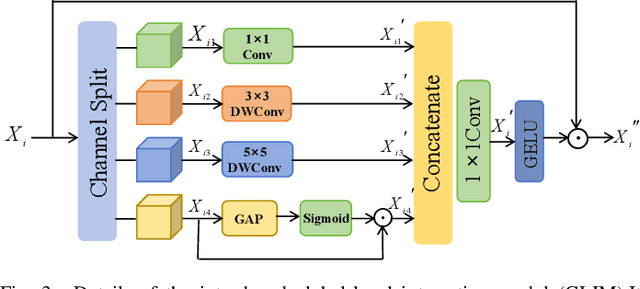
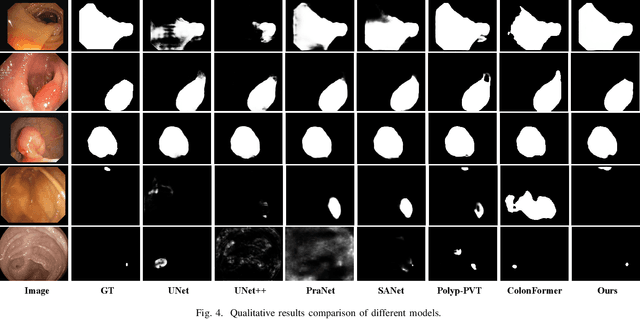
Numerous studies have demonstrated the strong performance of Vision Transformer (ViT)-based methods across various computer vision tasks. However, ViT models often struggle to effectively capture high-frequency components in images, which are crucial for detecting small targets and preserving edge details, especially in complex scenarios. This limitation is particularly challenging in colon polyp segmentation, where polyps exhibit significant variability in structure, texture, and shape. High-frequency information, such as boundary details, is essential for achieving precise semantic segmentation in this context. To address these challenges, we propose HiFiSeg, a novel network for colon polyp segmentation that enhances high-frequency information processing through a global-local vision transformer framework. HiFiSeg leverages the pyramid vision transformer (PVT) as its encoder and introduces two key modules: the global-local interaction module (GLIM) and the selective aggregation module (SAM). GLIM employs a parallel structure to fuse global and local information at multiple scales, effectively capturing fine-grained features. SAM selectively integrates boundary details from low-level features with semantic information from high-level features, significantly improving the model's ability to accurately detect and segment polyps. Extensive experiments on five widely recognized benchmark datasets demonstrate the effectiveness of HiFiSeg for polyp segmentation. Notably, the mDice scores on the challenging CVC-ColonDB and ETIS datasets reached 0.826 and 0.822, respectively, underscoring the superior performance of HiFiSeg in handling the specific complexities of this task.
RestoreAgent: Autonomous Image Restoration Agent via Multimodal Large Language Models
Jul 25, 2024



Natural images captured by mobile devices often suffer from multiple types of degradation, such as noise, blur, and low light. Traditional image restoration methods require manual selection of specific tasks, algorithms, and execution sequences, which is time-consuming and may yield suboptimal results. All-in-one models, though capable of handling multiple tasks, typically support only a limited range and often produce overly smooth, low-fidelity outcomes due to their broad data distribution fitting. To address these challenges, we first define a new pipeline for restoring images with multiple degradations, and then introduce RestoreAgent, an intelligent image restoration system leveraging multimodal large language models. RestoreAgent autonomously assesses the type and extent of degradation in input images and performs restoration through (1) determining the appropriate restoration tasks, (2) optimizing the task sequence, (3) selecting the most suitable models, and (4) executing the restoration. Experimental results demonstrate the superior performance of RestoreAgent in handling complex degradation, surpassing human experts. Furthermore, the system modular design facilitates the fast integration of new tasks and models, enhancing its flexibility and scalability for various applications.
UltraPixel: Advancing Ultra-High-Resolution Image Synthesis to New Peaks
Jul 02, 2024



Ultra-high-resolution image generation poses great challenges, such as increased semantic planning complexity and detail synthesis difficulties, alongside substantial training resource demands. We present UltraPixel, a novel architecture utilizing cascade diffusion models to generate high-quality images at multiple resolutions (\textit{e.g.}, 1K to 6K) within a single model, while maintaining computational efficiency. UltraPixel leverages semantics-rich representations of lower-resolution images in the later denoising stage to guide the whole generation of highly detailed high-resolution images, significantly reducing complexity. Furthermore, we introduce implicit neural representations for continuous upsampling and scale-aware normalization layers adaptable to various resolutions. Notably, both low- and high-resolution processes are performed in the most compact space, sharing the majority of parameters with less than 3$\%$ additional parameters for high-resolution outputs, largely enhancing training and inference efficiency. Our model achieves fast training with reduced data requirements, producing photo-realistic high-resolution images and demonstrating state-of-the-art performance in extensive experiments.
Towards Realistic Data Generation for Real-World Super-Resolution
Jun 12, 2024



Existing image super-resolution (SR) techniques often fail to generalize effectively in complex real-world settings due to the significant divergence between training data and practical scenarios. To address this challenge, previous efforts have either manually simulated intricate physical-based degradations or utilized learning-based techniques, yet these approaches remain inadequate for producing large-scale, realistic, and diverse data simultaneously. In this paper, we introduce a novel Realistic Decoupled Data Generator (RealDGen), an unsupervised learning data generation framework designed for real-world super-resolution. We meticulously develop content and degradation extraction strategies, which are integrated into a novel content-degradation decoupled diffusion model to create realistic low-resolution images from unpaired real LR and HR images. Extensive experiments demonstrate that RealDGen excels in generating large-scale, high-quality paired data that mirrors real-world degradations, significantly advancing the performance of popular SR models on various real-world benchmarks.
Low-Res Leads the Way: Improving Generalization for Super-Resolution by Self-Supervised Learning
Mar 05, 2024
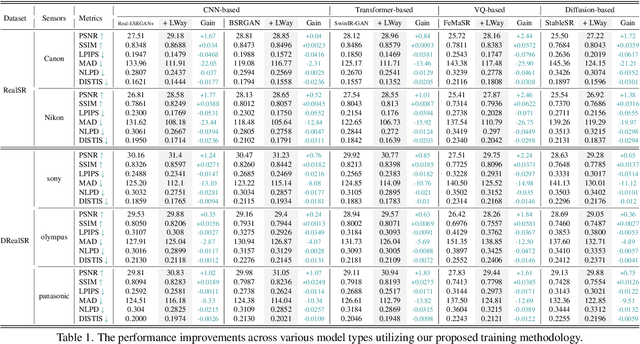
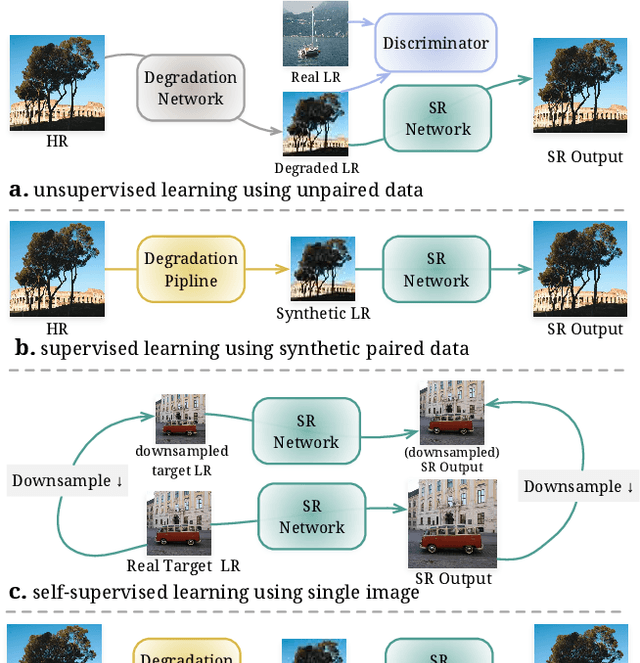

For image super-resolution (SR), bridging the gap between the performance on synthetic datasets and real-world degradation scenarios remains a challenge. This work introduces a novel "Low-Res Leads the Way" (LWay) training framework, merging Supervised Pre-training with Self-supervised Learning to enhance the adaptability of SR models to real-world images. Our approach utilizes a low-resolution (LR) reconstruction network to extract degradation embeddings from LR images, merging them with super-resolved outputs for LR reconstruction. Leveraging unseen LR images for self-supervised learning guides the model to adapt its modeling space to the target domain, facilitating fine-tuning of SR models without requiring paired high-resolution (HR) images. The integration of Discrete Wavelet Transform (DWT) further refines the focus on high-frequency details. Extensive evaluations show that our method significantly improves the generalization and detail restoration capabilities of SR models on unseen real-world datasets, outperforming existing methods. Our training regime is universally compatible, requiring no network architecture modifications, making it a practical solution for real-world SR applications.