 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Appearance Variations with 3D Consistent Features in Gaussian Splatting
Jan 18, 2025



Gaussian Splatting has emerged as a prominent 3D representation in novel view synthesis, but it still suffers from appearance variations, which are caused by various factors, such as modern camera ISPs, different time of day, weather conditions, and local light changes. These variations can lead to floaters and color distortions in the rendered images/videos. Recent appearance modeling approaches in Gaussian Splatting are either tightly coupled with the rendering process, hindering real-time rendering, or they only account for mild global variations, performing poorly in scenes with local light changes. In this paper, we propose DAVIGS, a method that decouples appearance variations in a plug-and-play and efficient manner. By transforming the rendering results at the image level instead of the Gaussian level, our approach can model appearance variations with minimal optimization time and memory overhead. Furthermore, our method gathers appearance-related information in 3D space to transform the rendered images, thus building 3D consistency across views implicitly. We validate our method on several appearance-variant scenes, and demonstrate that it achieves state-of-the-art rendering quality with minimal training time and memory usage, without compromising rendering speeds. Additionally, it provides performance improvements for different Gaussian Splatting baselines in a plug-and-play manner.
Grounding-IQA: Multimodal Language Grounding Model for Image Quality Assessment
Nov 26, 2024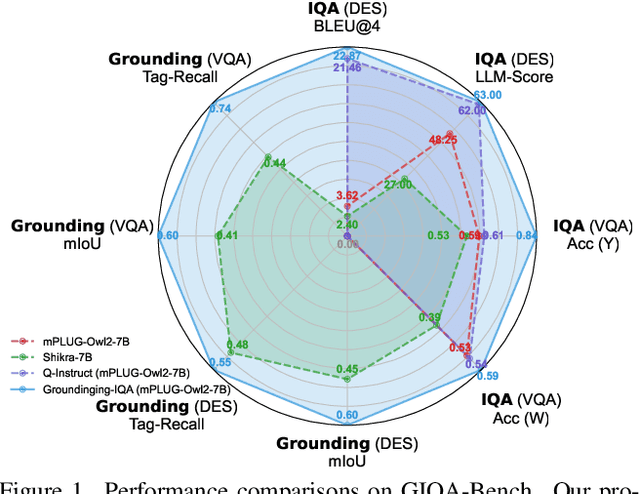


The development of multimodal large language models (MLLMs) enables the evaluation of image quality through natural language descriptions. This advancement allows for more detailed assessments. However, these MLLM-based IQA methods primarily rely on general contextual descriptions, sometimes limiting fine-grained quality assessment. To address this limitation, we introduce a new image quality assessment (IQA) task paradigm, grounding-IQA. This paradigm integrates multimodal referring and grounding with IQA to realize more fine-grained quality perception. Specifically, grounding-IQA comprises two subtasks: grounding-IQA-description (GIQA-DES) and visual question answering (GIQA-VQA). GIQA-DES involves detailed descriptions with precise locations (e.g., bounding boxes), while GIQA-VQA focuses on quality QA for local regions. To realize grounding-IQA, we construct a corresponding dataset, GIQA-160K, through our proposed automated annotation pipeline. Furthermore, we develop a well-designed benchmark, GIQA-Bench. The benchmark comprehensively evaluates the model grounding-IQA performance from three perspectives: description quality, VQA accuracy, and grounding precision. Experiments demonstrate that our proposed task paradigm, dataset, and benchmark facilitate the more fine-grained IQA application. Code: https://github.com/zhengchen1999/Grounding-IQA.
Dog-IQA: Standard-guided Zero-shot MLLM for Mix-grained Image Quality Assessment
Oct 03, 2024



Image quality assessment (IQA) serves as the golden standard for all models' performance in nearly all computer vision fields. However, it still suffers from poor out-of-distribution generalization ability and expensive training costs. To address these problems, we propose Dog-IQA, a standard-guided zero-shot mix-grained IQA method, which is training-free and utilizes the exceptional prior knowledge of multimodal large language models (MLLMs). To obtain accurate IQA scores, namely scores consistent with humans, we design an MLLM-based inference pipeline that imitates human experts. In detail, Dog-IQA applies two techniques. First, Dog-IQA objectively scores with specific standards that utilize MLLM's behavior pattern and minimize the influence of subjective factors. Second, Dog-IQA comprehensively takes local semantic objects and the whole image as input and aggregates their scores, leveraging local and global information. Our proposed Dog-IQA achieves state-of-the-art (SOTA) performance compared with training-free methods, and competitive performance compared with training-based methods in cross-dataset scenarios. Our code and models will be available at https://github.com/Kai-Liu001/Dog-IQA.
RestoreAgent: Autonomous Image Restoration Agent via Multimodal Large Language Models
Jul 25, 2024



Natural images captured by mobile devices often suffer from multiple types of degradation, such as noise, blur, and low light. Traditional image restoration methods require manual selection of specific tasks, algorithms, and execution sequences, which is time-consuming and may yield suboptimal results. All-in-one models, though capable of handling multiple tasks, typically support only a limited range and often produce overly smooth, low-fidelity outcomes due to their broad data distribution fitting. To address these challenges, we first define a new pipeline for restoring images with multiple degradations, and then introduce RestoreAgent, an intelligent image restoration system leveraging multimodal large language models. RestoreAgent autonomously assesses the type and extent of degradation in input images and performs restoration through (1) determining the appropriate restoration tasks, (2) optimizing the task sequence, (3) selecting the most suitable models, and (4) executing the restoration. Experimental results demonstrate the superior performance of RestoreAgent in handling complex degradation, surpassing human experts. Furthermore, the system modular design facilitates the fast integration of new tasks and models, enhancing its flexibility and scalability for various applications.
LeRF: Learning Resampling Function for Adaptive and Efficient Image Interpolation
Jul 13, 2024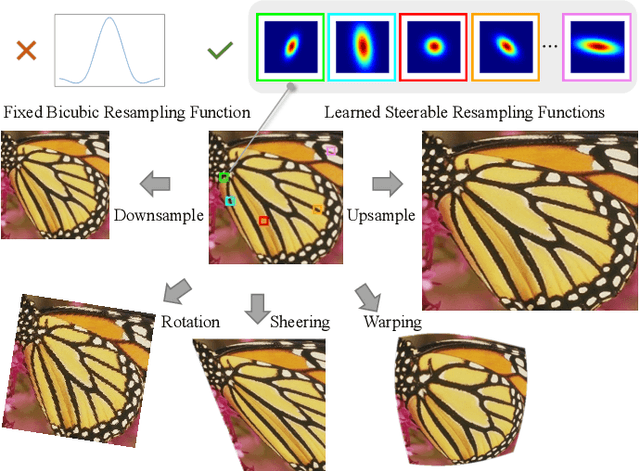

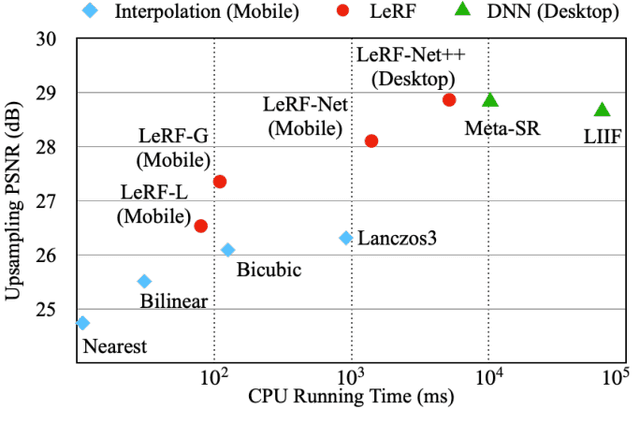
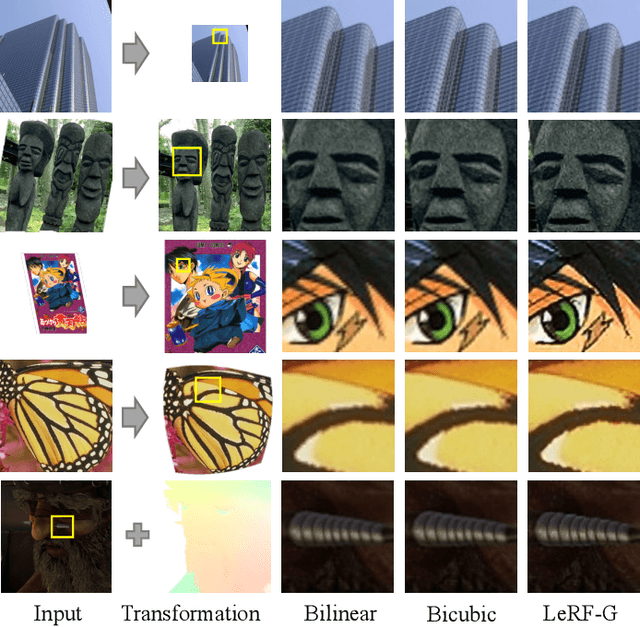
Image resampling is a basic technique that is widely employed in daily applications, such as camera photo editing. Recent deep neural networks (DNNs) have made impressive progress in performance by introducing learned data priors. Still, these methods are not the perfect substitute for interpolation, due to the drawbacks in efficiency and versatility. In this work, we propose a novel method of Learning Resampling Function (termed LeRF), which takes advantage of both the structural priors learned by DNNs and the locally continuous assumption of interpolation. Specifically, LeRF assigns spatially varying resampling functions to input image pixels and learns to predict the hyper-parameters that determine the shapes of these resampling functions with a neural network. Based on the formulation of LeRF, we develop a family of models, including both efficiency-orientated and performance-orientated ones. To achieve interpolation-level efficiency, we adopt look-up tables (LUTs) to accelerate the inference of the learned neural network. Furthermore, we design a directional ensemble strategy and edge-sensitive indexing patterns to better capture local structures. On the other hand, to obtain DNN-level performance, we propose an extension of LeRF to enable it in cooperation with pre-trained upsampling models for cascaded resampling. Extensive experiments show that the efficiency-orientated version of LeRF runs as fast as interpolation, generalizes well to arbitrary transformations, and outperforms interpolation significantly, e.g., up to 3dB PSNR gain over Bicubic for x2 upsampling on Manga109. Besides, the performance-orientated version of LeRF reaches comparable performance with existing DNNs at much higher efficiency, e.g., less than 25% running time on a desktop GPU.
Urban Waterlogging Detection: A Challenging Benchmark and Large-Small Model Co-Adapter
Jul 11, 2024



Urban waterlogging poses a major risk to public safety and infrastructure. Conventional methods using water-level sensors need high-maintenance to hardly achieve full coverage. Recent advances employ surveillance camera imagery and deep learning for detection, yet these struggle amidst scarce data and adverse environmental conditions. In this paper, we establish a challenging Urban Waterlogging Benchmark (UW-Bench) under diverse adverse conditions to advance real-world applications. We propose a Large-Small Model co-adapter paradigm (LSM-adapter), which harnesses the substantial generic segmentation potential of large model and the specific task-directed guidance of small model. Specifically, a Triple-S Prompt Adapter module alongside a Dynamic Prompt Combiner are proposed to generate then merge multiple prompts for mask decoder adaptation. Meanwhile, a Histogram Equalization Adap-ter module is designed to infuse the image specific information for image encoder adaptation. Results and analysis show the challenge and superiority of our developed benchmark and algorithm. Project page: \url{https://github.com/zhang-chenxu/LSM-Adapter}
UltraPixel: Advancing Ultra-High-Resolution Image Synthesis to New Peaks
Jul 02, 2024



Ultra-high-resolution image generation poses great challenges, such as increased semantic planning complexity and detail synthesis difficulties, alongside substantial training resource demands. We present UltraPixel, a novel architecture utilizing cascade diffusion models to generate high-quality images at multiple resolutions (\textit{e.g.}, 1K to 6K) within a single model, while maintaining computational efficiency. UltraPixel leverages semantics-rich representations of lower-resolution images in the later denoising stage to guide the whole generation of highly detailed high-resolution images, significantly reducing complexity. Furthermore, we introduce implicit neural representations for continuous upsampling and scale-aware normalization layers adaptable to various resolutions. Notably, both low- and high-resolution processes are performed in the most compact space, sharing the majority of parameters with less than 3$\%$ additional parameters for high-resolution outputs, largely enhancing training and inference efficiency. Our model achieves fast training with reduced data requirements, producing photo-realistic high-resolution images and demonstrating state-of-the-art performance in extensive experiments.
DI-Retinex: Digital-Imaging Retinex Theory for Low-Light Image Enhancement
Apr 04, 2024



Many existing methods for low-light image enhancement (LLIE) based on Retinex theory ignore important factors that affect the validity of this theory in digital imaging, such as noise, quantization error, non-linearity, and dynamic range overflow. In this paper, we propose a new expression called Digital-Imaging Retinex theory (DI-Retinex) through theoretical and experimental analysis of Retinex theory in digital imaging. Our new expression includes an offset term in the enhancement model, which allows for pixel-wise brightness contrast adjustment with a non-linear mapping function. In addition, to solve the lowlight enhancement problem in an unsupervised manner, we propose an image-adaptive masked reverse degradation loss in Gamma space. We also design a variance suppression loss for regulating the additional offset term. Extensive experiments show that our proposed method outperforms all existing unsupervised methods in terms of visual quality, model size, and speed. Our algorithm can also assist downstream face detectors in low-light, as it shows the most performance gain after the low-light enhancement compared to other methods.
Learning Exhaustive Correlation for Spectral Super-Resolution: Where Unified Spatial-Spectral Attention Meets Mutual Linear Dependence
Dec 20, 2023Spectral super-resolution from the easily obtainable RGB image to hyperspectral image (HSI) has drawn increasing interest in the field of computational photography. The crucial aspect of spectral super-resolution lies in exploiting the correlation within HSIs. However, two types of bottlenecks in existing Transformers limit performance improvement and practical applications. First, existing Transformers often separately emphasize either spatial-wise or spectral-wise correlation, disrupting the 3D features of HSI and hindering the exploitation of unified spatial-spectral correlation. Second, the existing self-attention mechanism learns the correlation between pairs of tokens and captures the full-rank correlation matrix, leading to its inability to establish mutual linear dependence among multiple tokens. To address these issues, we propose a novel Exhaustive Correlation Transformer (ECT) for spectral super-resolution. First, we propose a Spectral-wise Discontinuous 3D (SD3D) splitting strategy, which models unified spatial-spectral correlation by simultaneously utilizing spatial-wise continuous splitting and spectral-wise discontinuous splitting. Second, we propose a Dynamic Low-Rank Mapping (DLRM) model, which captures mutual linear dependence among multiple tokens through a dynamically calculated low-rank dependence map. By integrating unified spatial-spectral attention with mutual linear dependence, our ECT can establish exhaustive correlation within HSI. The experimental results on both simulated and real data indicate that our method achieves state-of-the-art performance. Codes and pretrained models will be available later.
Computational Spectral Imaging with Unified Encoding Model: A Comparative Study and Beyond
Dec 20, 2023Computational spectral imaging is drawing increasing attention owing to the snapshot advantage, and amplitude, phase, and wavelength encoding systems are three types of representative implementations. Fairly comparing and understanding the performance of these systems is essential, but challenging due to the heterogeneity in encoding design. To overcome this limitation, we propose the unified encoding model (UEM) that covers all physical systems using the three encoding types. Specifically, the UEM comprises physical amplitude, physical phase, and physical wavelength encoding models that can be combined with a digital decoding model in a joint encoder-decoder optimization framework to compare the three systems under a unified experimental setup fairly. Furthermore, we extend the UEMs to ideal versions, namely, ideal amplitude, ideal phase, and ideal wavelength encoding models, which are free from physical constraints, to explore the full potential of the three types of computational spectral imaging systems. Finally, we conduct a holistic comparison of the three types of computational spectral imaging systems and provide valuable insights for designing and exploiting these systems in the future.