 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePangu Pro MoE: Mixture of Grouped Experts for Efficient Sparsity
May 28, 2025The surgence of Mixture of Experts (MoE) in Large Language Models promises a small price of execution cost for a much larger model parameter count and learning capacity, because only a small fraction of parameters are activated for each input token. However, it is commonly observed that some experts are activated far more often than others, leading to system inefficiency when running the experts on different devices in parallel. Therefore, we introduce Mixture of Grouped Experts (MoGE), which groups the experts during selection and balances the expert workload better than MoE in nature. It constrains tokens to activate an equal number of experts within each predefined expert group. When a model execution is distributed on multiple devices, this architectural design ensures a balanced computational load across devices, significantly enhancing throughput, particularly for the inference phase. Further, we build Pangu Pro MoE on Ascend NPUs, a sparse model based on MoGE with 72 billion total parameters, 16 billion of which are activated for each token. The configuration of Pangu Pro MoE is optimized for Ascend 300I Duo and 800I A2 through extensive system simulation studies. Our experiments indicate that MoGE indeed leads to better expert load balancing and more efficient execution for both model training and inference on Ascend NPUs. The inference performance of Pangu Pro MoE achieves 1148 tokens/s per card and can be further improved to 1528 tokens/s per card by speculative acceleration, outperforming comparable 32B and 72B Dense models. Furthermore, we achieve an excellent cost-to-performance ratio for model inference on Ascend 300I Duo. Our studies show that Ascend NPUs are capable of training Pangu Pro MoE with massive parallelization to make it a leading model within the sub-100B total parameter class, outperforming prominent open-source models like GLM-Z1-32B and Qwen3-32B.
Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
LeRF: Learning Resampling Function for Adaptive and Efficient Image Interpolation
Jul 13, 2024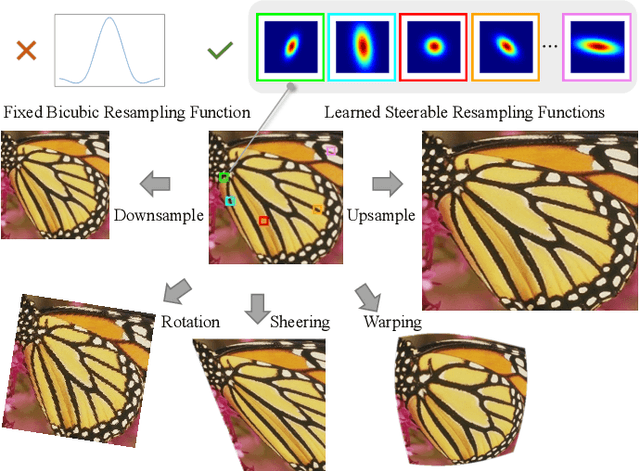

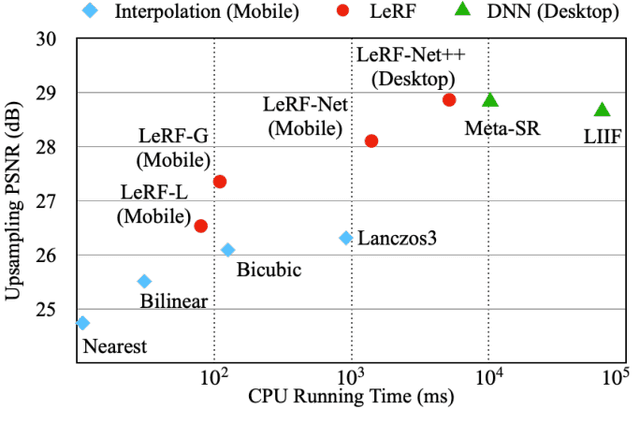
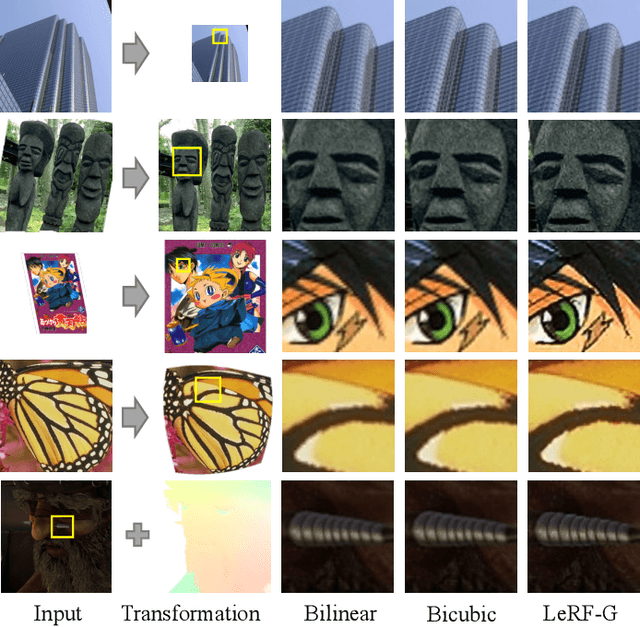
Image resampling is a basic technique that is widely employed in daily applications, such as camera photo editing. Recent deep neural networks (DNNs) have made impressive progress in performance by introducing learned data priors. Still, these methods are not the perfect substitute for interpolation, due to the drawbacks in efficiency and versatility. In this work, we propose a novel method of Learning Resampling Function (termed LeRF), which takes advantage of both the structural priors learned by DNNs and the locally continuous assumption of interpolation. Specifically, LeRF assigns spatially varying resampling functions to input image pixels and learns to predict the hyper-parameters that determine the shapes of these resampling functions with a neural network. Based on the formulation of LeRF, we develop a family of models, including both efficiency-orientated and performance-orientated ones. To achieve interpolation-level efficiency, we adopt look-up tables (LUTs) to accelerate the inference of the learned neural network. Furthermore, we design a directional ensemble strategy and edge-sensitive indexing patterns to better capture local structures. On the other hand, to obtain DNN-level performance, we propose an extension of LeRF to enable it in cooperation with pre-trained upsampling models for cascaded resampling. Extensive experiments show that the efficiency-orientated version of LeRF runs as fast as interpolation, generalizes well to arbitrary transformations, and outperforms interpolation significantly, e.g., up to 3dB PSNR gain over Bicubic for x2 upsampling on Manga109. Besides, the performance-orientated version of LeRF reaches comparable performance with existing DNNs at much higher efficiency, e.g., less than 25% running time on a desktop GPU.
GSD: View-Guided Gaussian Splatting Diffusion for 3D Reconstruction
Jul 05, 2024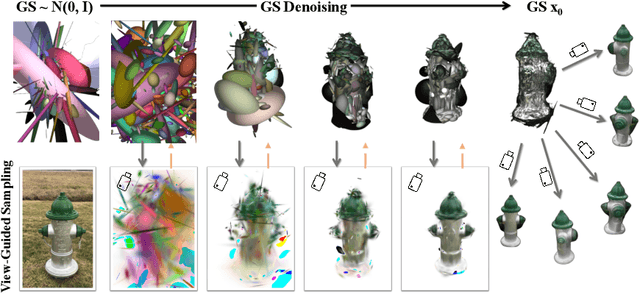



We present GSD, a diffusion model approach based on Gaussian Splatting (GS) representation for 3D object reconstruction from a single view. Prior works suffer from inconsistent 3D geometry or mediocre rendering quality due to improper representations. We take a step towards resolving these shortcomings by utilizing the recent state-of-the-art 3D explicit representation, Gaussian Splatting, and an unconditional diffusion model. This model learns to generate 3D objects represented by sets of GS ellipsoids. With these strong generative 3D priors, though learning unconditionally, the diffusion model is ready for view-guided reconstruction without further model fine-tuning. This is achieved by propagating fine-grained 2D features through the efficient yet flexible splatting function and the guided denoising sampling process. In addition, a 2D diffusion model is further employed to enhance rendering fidelity, and improve reconstructed GS quality by polishing and re-using the rendered images. The final reconstructed objects explicitly come with high-quality 3D structure and texture, and can be efficiently rendered in arbitrary views. Experiments on the challenging real-world CO3D dataset demonstrate the superiority of our approach.
Low-Res Leads the Way: Improving Generalization for Super-Resolution by Self-Supervised Learning
Mar 05, 2024
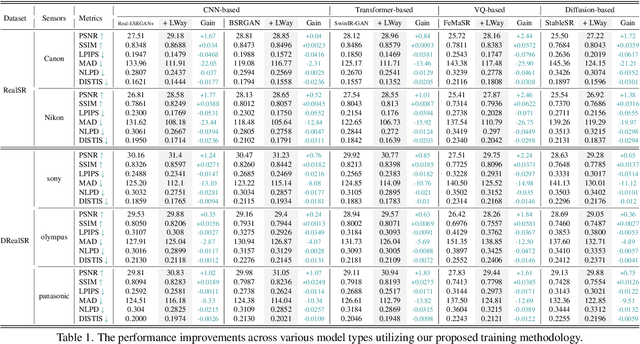
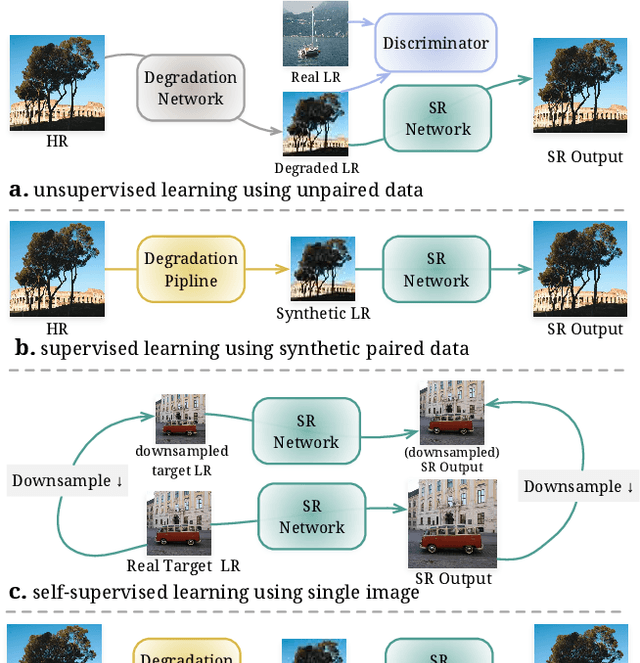

For image super-resolution (SR), bridging the gap between the performance on synthetic datasets and real-world degradation scenarios remains a challenge. This work introduces a novel "Low-Res Leads the Way" (LWay) training framework, merging Supervised Pre-training with Self-supervised Learning to enhance the adaptability of SR models to real-world images. Our approach utilizes a low-resolution (LR) reconstruction network to extract degradation embeddings from LR images, merging them with super-resolved outputs for LR reconstruction. Leveraging unseen LR images for self-supervised learning guides the model to adapt its modeling space to the target domain, facilitating fine-tuning of SR models without requiring paired high-resolution (HR) images. The integration of Discrete Wavelet Transform (DWT) further refines the focus on high-frequency details. Extensive evaluations show that our method significantly improves the generalization and detail restoration capabilities of SR models on unseen real-world datasets, outperforming existing methods. Our training regime is universally compatible, requiring no network architecture modifications, making it a practical solution for real-world SR applications.
VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction
Feb 27, 2024Existing NeRF-based methods for large scene reconstruction often have limitations in visual quality and rendering speed. While the recent 3D Gaussian Splatting works well on small-scale and object-centric scenes, scaling it up to large scenes poses challenges due to limited video memory, long optimization time, and noticeable appearance variations. To address these challenges, we present VastGaussian, the first method for high-quality reconstruction and real-time rendering on large scenes based on 3D Gaussian Splatting. We propose a progressive partitioning strategy to divide a large scene into multiple cells, where the training cameras and point cloud are properly distributed with an airspace-aware visibility criterion. These cells are merged into a complete scene after parallel optimization. We also introduce decoupled appearance modeling into the optimization process to reduce appearance variations in the rendered images. Our approach outperforms existing NeRF-based methods and achieves state-of-the-art results on multiple large scene datasets, enabling fast optimization and high-fidelity real-time rendering.
Generative Human Motion Stylization in Latent Space
Jan 24, 2024



Human motion stylization aims to revise the style of an input motion while keeping its content unaltered. Unlike existing works that operate directly in pose space, we leverage the latent space of pretrained autoencoders as a more expressive and robust representation for motion extraction and infusion. Building upon this, we present a novel generative model that produces diverse stylization results of a single motion (latent) code. During training, a motion code is decomposed into two coding components: a deterministic content code, and a probabilistic style code adhering to a prior distribution; then a generator massages the random combination of content and style codes to reconstruct the corresponding motion codes. Our approach is versatile, allowing the learning of probabilistic style space from either style labeled or unlabeled motions, providing notable flexibility in stylization as well. In inference, users can opt to stylize a motion using style cues from a reference motion or a label. Even in the absence of explicit style input, our model facilitates novel re-stylization by sampling from the unconditional style prior distribution. Experimental results show that our proposed stylization models, despite their lightweight design, outperform the state-of-the-arts in style reeanactment, content preservation, and generalization across various applications and settings. Project Page: https://yxmu.foo/GenMoStyle
Learning Exhaustive Correlation for Spectral Super-Resolution: Where Unified Spatial-Spectral Attention Meets Mutual Linear Dependence
Dec 20, 2023Spectral super-resolution from the easily obtainable RGB image to hyperspectral image (HSI) has drawn increasing interest in the field of computational photography. The crucial aspect of spectral super-resolution lies in exploiting the correlation within HSIs. However, two types of bottlenecks in existing Transformers limit performance improvement and practical applications. First, existing Transformers often separately emphasize either spatial-wise or spectral-wise correlation, disrupting the 3D features of HSI and hindering the exploitation of unified spatial-spectral correlation. Second, the existing self-attention mechanism learns the correlation between pairs of tokens and captures the full-rank correlation matrix, leading to its inability to establish mutual linear dependence among multiple tokens. To address these issues, we propose a novel Exhaustive Correlation Transformer (ECT) for spectral super-resolution. First, we propose a Spectral-wise Discontinuous 3D (SD3D) splitting strategy, which models unified spatial-spectral correlation by simultaneously utilizing spatial-wise continuous splitting and spectral-wise discontinuous splitting. Second, we propose a Dynamic Low-Rank Mapping (DLRM) model, which captures mutual linear dependence among multiple tokens through a dynamically calculated low-rank dependence map. By integrating unified spatial-spectral attention with mutual linear dependence, our ECT can establish exhaustive correlation within HSI. The experimental results on both simulated and real data indicate that our method achieves state-of-the-art performance. Codes and pretrained models will be available later.
Computational Spectral Imaging with Unified Encoding Model: A Comparative Study and Beyond
Dec 20, 2023Computational spectral imaging is drawing increasing attention owing to the snapshot advantage, and amplitude, phase, and wavelength encoding systems are three types of representative implementations. Fairly comparing and understanding the performance of these systems is essential, but challenging due to the heterogeneity in encoding design. To overcome this limitation, we propose the unified encoding model (UEM) that covers all physical systems using the three encoding types. Specifically, the UEM comprises physical amplitude, physical phase, and physical wavelength encoding models that can be combined with a digital decoding model in a joint encoder-decoder optimization framework to compare the three systems under a unified experimental setup fairly. Furthermore, we extend the UEMs to ideal versions, namely, ideal amplitude, ideal phase, and ideal wavelength encoding models, which are free from physical constraints, to explore the full potential of the three types of computational spectral imaging systems. Finally, we conduct a holistic comparison of the three types of computational spectral imaging systems and provide valuable insights for designing and exploiting these systems in the future.
CoSeR: Bridging Image and Language for Cognitive Super-Resolution
Dec 02, 2023Existing super-resolution (SR) models primarily focus on restoring local texture details, often neglecting the global semantic information within the scene. This oversight can lead to the omission of crucial semantic details or the introduction of inaccurate textures during the recovery process. In our work, we introduce the Cognitive Super-Resolution (CoSeR) framework, empowering SR models with the capacity to comprehend low-resolution images. We achieve this by marrying image appearance and language understanding to generate a cognitive embedding, which not only activates prior information from large text-to-image diffusion models but also facilitates the generation of high-quality reference images to optimize the SR process. To further improve image fidelity, we propose a novel condition injection scheme called "All-in-Attention", consolidating all conditional information into a single module. Consequently, our method successfully restores semantically correct and photorealistic details, demonstrating state-of-the-art performance across multiple benchmarks. Code: https://github.com/VINHYU/CoSeR