 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTABES: Trajectory-Aware Backward-on-Entropy Steering for Masked Diffusion Models
Jan 30, 2026Masked Diffusion Models (MDMs) have emerged as a promising non-autoregressive paradigm for generative tasks, offering parallel decoding and bidirectional context utilization. However, current sampling methods rely on simple confidence-based heuristics that ignore the long-term impact of local decisions, leading to trajectory lock-in where early hallucinations cascade into global incoherence. While search-based methods mitigate this, they incur prohibitive computational costs ($O(K)$ forward passes per step). In this work, we propose Backward-on-Entropy (BoE) Steering, a gradient-guided inference framework that approximates infinite-horizon lookahead via a single backward pass. We formally derive the Token Influence Score (TIS) from a first-order expansion of the trajectory cost functional, proving that the gradient of future entropy with respect to input embeddings serves as an optimal control signal for minimizing uncertainty. To ensure scalability, we introduce \texttt{ActiveQueryAttention}, a sparse adjoint primitive that exploits the structure of the masking objective to reduce backward pass complexity. BoE achieves a superior Pareto frontier for inference-time scaling compared to existing unmasking methods, demonstrating that gradient-guided steering offers a mathematically principled and efficient path to robust non-autoregressive generation. We will release the code.
CIRAG: Construction-Integration Retrieval and Adaptive Generation for Multi-hop Question Answering
Jan 11, 2026Triple-based Iterative Retrieval-Augmented Generation (iRAG) mitigates document-level noise for multi-hop question answering. However, existing methods still face limitations: (i) greedy single-path expansion, which propagates early errors and fails to capture parallel evidence from different reasoning branches, and (ii) granularity-demand mismatch, where a single evidence representation struggles to balance noise control with contextual sufficiency. In this paper, we propose the Construction-Integration Retrieval and Adaptive Generation model, CIRAG. It introduces an Iterative Construction-Integration module that constructs candidate triples and history-conditionally integrates them to distill core triples and generate the next-hop query. This module mitigates the greedy trap by preserving multiple plausible evidence chains. Besides, we propose an Adaptive Cascaded Multi-Granularity Generation module that progressively expands contextual evidence based on the problem requirements, from triples to supporting sentences and full passages. Moreover, we introduce Trajectory Distillation, which distills the teacher model's integration policy into a lightweight student, enabling efficient and reliable long-horizon reasoning. Extensive experiments demonstrate that CIRAG achieves superior performance compared to existing iRAG methods.
Relational Visual Similarity
Dec 08, 2025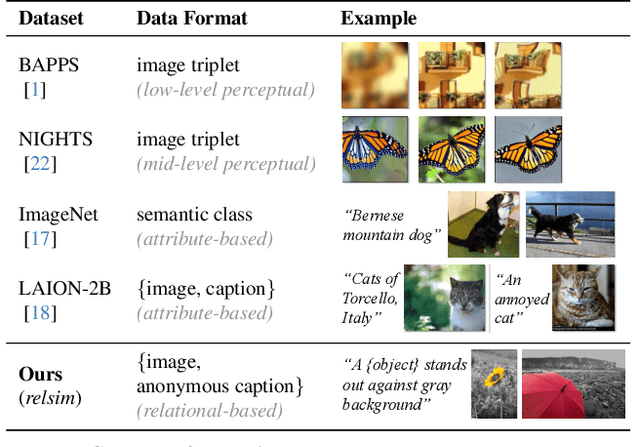
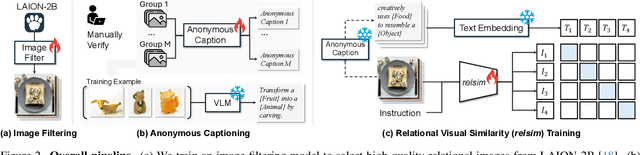
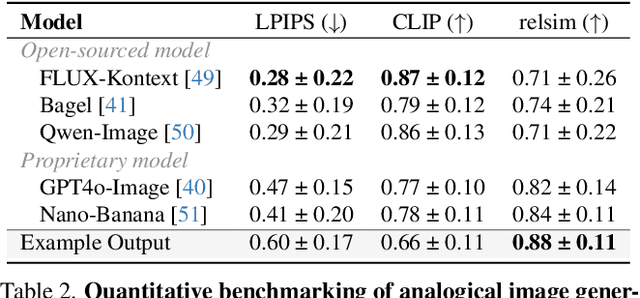

Humans do not just see attribute similarity -- we also see relational similarity. An apple is like a peach because both are reddish fruit, but the Earth is also like a peach: its crust, mantle, and core correspond to the peach's skin, flesh, and pit. This ability to perceive and recognize relational similarity, is arguable by cognitive scientist to be what distinguishes humans from other species. Yet, all widely used visual similarity metrics today (e.g., LPIPS, CLIP, DINO) focus solely on perceptual attribute similarity and fail to capture the rich, often surprising relational similarities that humans perceive. How can we go beyond the visible content of an image to capture its relational properties? How can we bring images with the same relational logic closer together in representation space? To answer these questions, we first formulate relational image similarity as a measurable problem: two images are relationally similar when their internal relations or functions among visual elements correspond, even if their visual attributes differ. We then curate 114k image-caption dataset in which the captions are anonymized -- describing the underlying relational logic of the scene rather than its surface content. Using this dataset, we finetune a Vision-Language model to measure the relational similarity between images. This model serves as the first step toward connecting images by their underlying relational structure rather than their visible appearance. Our study shows that while relational similarity has a lot of real-world applications, existing image similarity models fail to capture it -- revealing a critical gap in visual computing.
ForgeDAN: An Evolutionary Framework for Jailbreaking Aligned Large Language Models
Nov 17, 2025



The rapid adoption of large language models (LLMs) has brought both transformative applications and new security risks, including jailbreak attacks that bypass alignment safeguards to elicit harmful outputs. Existing automated jailbreak generation approaches e.g. AutoDAN, suffer from limited mutation diversity, shallow fitness evaluation, and fragile keyword-based detection. To address these limitations, we propose ForgeDAN, a novel evolutionary framework for generating semantically coherent and highly effective adversarial prompts against aligned LLMs. First, ForgeDAN introduces multi-strategy textual perturbations across \textit{character, word, and sentence-level} operations to enhance attack diversity; then we employ interpretable semantic fitness evaluation based on a text similarity model to guide the evolutionary process toward semantically relevant and harmful outputs; finally, ForgeDAN integrates dual-dimensional jailbreak judgment, leveraging an LLM-based classifier to jointly assess model compliance and output harmfulness, thereby reducing false positives and improving detection effectiveness. Our evaluation demonstrates ForgeDAN achieves high jailbreaking success rates while maintaining naturalness and stealth, outperforming existing SOTA solutions.
Continuously Steering LLMs Sensitivity to Contextual Knowledge with Proxy Models
Aug 28, 2025In Large Language Models (LLMs) generation, there exist knowledge conflicts and scenarios where parametric knowledge contradicts knowledge provided in the context. Previous works studied tuning, decoding algorithms, or locating and editing context-aware neurons to adapt LLMs to be faithful to new contextual knowledge. However, they are usually inefficient or ineffective for large models, not workable for black-box models, or unable to continuously adjust LLMs' sensitivity to the knowledge provided in the context. To mitigate these problems, we propose CSKS (Continuously Steering Knowledge Sensitivity), a simple framework that can steer LLMs' sensitivity to contextual knowledge continuously at a lightweight cost. Specifically, we tune two small LMs (i.e. proxy models) and use the difference in their output distributions to shift the original distribution of an LLM without modifying the LLM weights. In the evaluation process, we not only design synthetic data and fine-grained metrics to measure models' sensitivity to contextual knowledge but also use a real conflict dataset to validate CSKS's practical efficacy. Extensive experiments demonstrate that our framework achieves continuous and precise control over LLMs' sensitivity to contextual knowledge, enabling both increased sensitivity and reduced sensitivity, thereby allowing LLMs to prioritize either contextual or parametric knowledge as needed flexibly. Our data and code are available at https://github.com/OliveJuiceLin/CSKS.
CP-LLM: Context and Pixel Aware Large Language Model for Video Quality Assessment
May 21, 2025Video quality assessment (VQA) is a challenging research topic with broad applications. Effective VQA necessitates sensitivity to pixel-level distortions and a comprehensive understanding of video context to accurately determine the perceptual impact of distortions. Traditional hand-crafted and learning-based VQA models mainly focus on pixel-level distortions and lack contextual understanding, while recent LLM-based models struggle with sensitivity to small distortions or handle quality scoring and description as separate tasks. To address these shortcomings, we introduce CP-LLM: a Context and Pixel aware Large Language Model. CP-LLM is a novel multimodal LLM architecture featuring dual vision encoders designed to independently analyze perceptual quality at both high-level (video context) and low-level (pixel distortion) granularity, along with a language decoder subsequently reasons about the interplay between these aspects. This design enables CP-LLM to simultaneously produce robust quality scores and interpretable quality descriptions, with enhanced sensitivity to pixel distortions (e.g. compression artifacts). The model is trained via a multi-task pipeline optimizing for score prediction, description generation, and pairwise comparisons. Experiment results demonstrate that CP-LLM achieves state-of-the-art cross-dataset performance on established VQA benchmarks and superior robustness to pixel distortions, confirming its efficacy for comprehensive and practical video quality assessment in real-world scenarios.
OmniStyle: Filtering High Quality Style Transfer Data at Scale
May 20, 2025
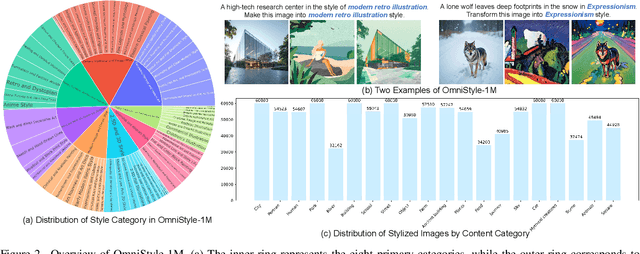
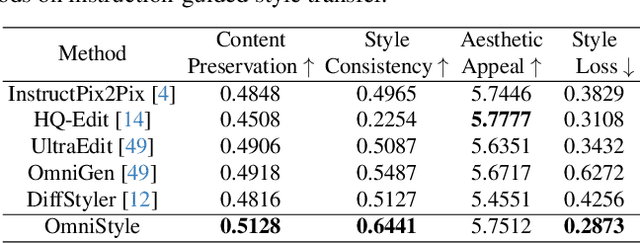
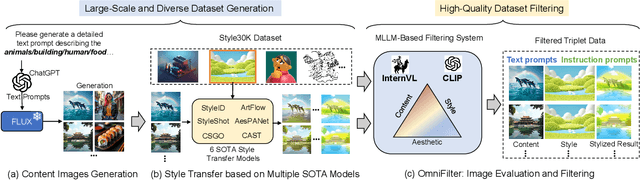
In this paper, we introduce OmniStyle-1M, a large-scale paired style transfer dataset comprising over one million content-style-stylized image triplets across 1,000 diverse style categories, each enhanced with textual descriptions and instruction prompts. We show that OmniStyle-1M can not only enable efficient and scalable of style transfer models through supervised training but also facilitate precise control over target stylization. Especially, to ensure the quality of the dataset, we introduce OmniFilter, a comprehensive style transfer quality assessment framework, which filters high-quality triplets based on content preservation, style consistency, and aesthetic appeal. Building upon this foundation, we propose OmniStyle, a framework based on the Diffusion Transformer (DiT) architecture designed for high-quality and efficient style transfer. This framework supports both instruction-guided and image-guided style transfer, generating high resolution outputs with exceptional detail. Extensive qualitative and quantitative evaluations demonstrate OmniStyle's superior performance compared to existing approaches, highlighting its efficiency and versatility. OmniStyle-1M and its accompanying methodologies provide a significant contribution to advancing high-quality style transfer, offering a valuable resource for the research community.
CreoPep: A Universal Deep Learning Framework for Target-Specific Peptide Design and Optimization
May 05, 2025Target-specific peptides, such as conotoxins, exhibit exceptional binding affinity and selectivity toward ion channels and receptors. However, their therapeutic potential remains underutilized due to the limited diversity of natural variants and the labor-intensive nature of traditional optimization strategies. Here, we present CreoPep, a deep learning-based conditional generative framework that integrates masked language modeling with a progressive masking scheme to design high-affinity peptide mutants while uncovering novel structural motifs. CreoPep employs an integrative augmentation pipeline, combining FoldX-based energy screening with temperature-controlled multinomial sampling, to generate structurally and functionally diverse peptides that retain key pharmacological properties. We validate this approach by designing conotoxin inhibitors targeting the $\alpha$7 nicotinic acetylcholine receptor, achieving submicromolar potency in electrophysiological assays. Structural analysis reveals that CreoPep-generated variants engage in both conserved and novel binding modes, including disulfide-deficient forms, thus expanding beyond conventional design paradigms. Overall, CreoPep offers a robust and generalizable platform that bridges computational peptide design with experimental validation, accelerating the discovery of next-generation peptide therapeutics.
PTCL: Pseudo-Label Temporal Curriculum Learning for Label-Limited Dynamic Graph
Apr 24, 2025Dynamic node classification is critical for modeling evolving systems like financial transactions and academic collaborations. In such systems, dynamically capturing node information changes is critical for dynamic node classification, which usually requires all labels at every timestamp. However, it is difficult to collect all dynamic labels in real-world scenarios due to high annotation costs and label uncertainty (e.g., ambiguous or delayed labels in fraud detection). In contrast, final timestamp labels are easier to obtain as they rely on complete temporal patterns and are usually maintained as a unique label for each user in many open platforms, without tracking the history data. To bridge this gap, we propose PTCL(Pseudo-label Temporal Curriculum Learning), a pioneering method addressing label-limited dynamic node classification where only final labels are available. PTCL introduces: (1) a temporal decoupling architecture separating the backbone (learning time-aware representations) and decoder (strictly aligned with final labels), which generate pseudo-labels, and (2) a Temporal Curriculum Learning strategy that prioritizes pseudo-labels closer to the final timestamp by assigning them higher weights using an exponentially decaying function. We contribute a new academic dataset (CoOAG), capturing long-range research interest in dynamic graph. Experiments across real-world scenarios demonstrate PTCL's consistent superiority over other methods adapted to this task. Beyond methodology, we propose a unified framework FLiD (Framework for Label-Limited Dynamic Node Classification), consisting of a complete preparation workflow, training pipeline, and evaluation standards, and supporting various models and datasets. The code can be found at https://github.com/3205914485/FLiD.
Leveraging Large Self-Supervised Time-Series Models for Transferable Diagnosis in Cross-Aircraft Type Bleed Air System
Apr 12, 2025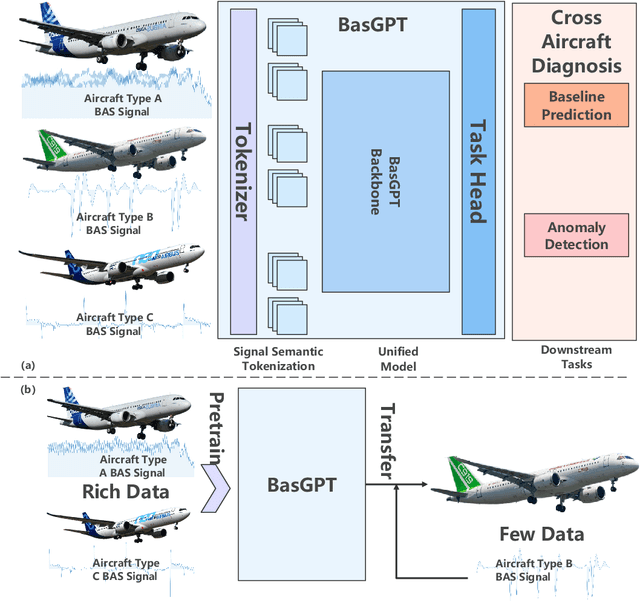

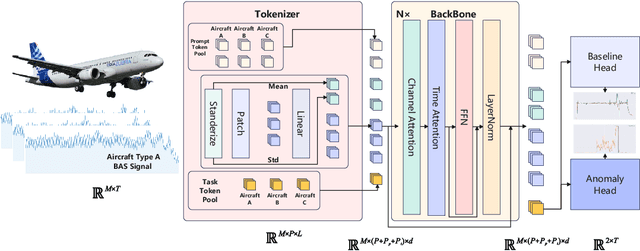

Bleed Air System (BAS) is critical for maintaining flight safety and operational efficiency, supporting functions such as cabin pressurization, air conditioning, and engine anti-icing. However, BAS malfunctions, including overpressure, low pressure, and overheating, pose significant risks such as cabin depressurization, equipment failure, or engine damage. Current diagnostic approaches face notable limitations when applied across different aircraft types, particularly for newer models that lack sufficient operational data. To address these challenges, this paper presents a self-supervised learning-based foundation model that enables the transfer of diagnostic knowledge from mature aircraft (e.g., A320, A330) to newer ones (e.g., C919). Leveraging self-supervised pretraining, the model learns universal feature representations from flight signals without requiring labeled data, making it effective in data-scarce scenarios. This model enhances both anomaly detection and baseline signal prediction, thereby improving system reliability. The paper introduces a cross-model dataset, a self-supervised learning framework for BAS diagnostics, and a novel Joint Baseline and Anomaly Detection Loss Function tailored to real-world flight data. These innovations facilitate efficient transfer of diagnostic knowledge across aircraft types, ensuring robust support for early operational stages of new models. Additionally, the paper explores the relationship between model capacity and transferability, providing a foundation for future research on large-scale flight signal models.