 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Mem: Fine-Grained Feedback Alignment for Long-Horizon Memory Management
Jan 13, 2026Effective memory management is essential for large language model agents to navigate long-horizon tasks. Recent research has explored using Reinforcement Learning to develop specialized memory manager agents. However, existing approaches rely on final task performance as the primary reward, which results in severe reward sparsity and ineffective credit assignment, providing insufficient guidance for individual memory operations. To this end, we propose Fine-Mem, a unified framework designed for fine-grained feedback alignment. First, we introduce a Chunk-level Step Reward to provide immediate step-level supervision via auxiliary chunk-specific question answering tasks. Second, we devise Evidence-Anchored Reward Attribution to redistribute global rewards by anchoring credit to key memory operations, based on the specific memory items utilized as evidence in reasoning. Together, these components enable stable policy optimization and align local memory operations with the long-term utility of memory. Experiments on Memalpha and MemoryAgentBench demonstrate that Fine-Mem consistently outperforms strong baselines, achieving superior success rates across various sub-tasks. Further analysis reveals its adaptability and strong generalization capabilities across diverse model configurations and backbones.
WebAnchor: Anchoring Agent Planning to Stabilize Long-Horizon Web Reasoning
Jan 07, 2026Large Language Model(LLM)-based agents have shown strong capabilities in web information seeking, with reinforcement learning (RL) becoming a key optimization paradigm. However, planning remains a bottleneck, as existing methods struggle with long-horizon strategies. Our analysis reveals a critical phenomenon, plan anchor, where the first reasoning step disproportionately impacts downstream behavior in long-horizon web reasoning tasks. Current RL algorithms, fail to account for this by uniformly distributing rewards across the trajectory. To address this, we propose Anchor-GRPO, a two-stage RL framework that decouples planning and execution. In Stage 1, the agent optimizes its first-step planning using fine-grained rubrics derived from self-play experiences and human calibration. In Stage 2, execution is aligned with the initial plan through sparse rewards, ensuring stable and efficient tool usage. We evaluate Anchor-GRPO on four benchmarks: BrowseComp, BrowseComp-Zh, GAIA, and XBench-DeepSearch. Across models from 3B to 30B, Anchor-GRPO outperforms baseline GRPO and First-step GRPO, improving task success and tool efficiency. Notably, WebAnchor-30B achieves 46.0% pass@1 on BrowseComp and 76.4% on GAIA. Anchor-GRPO also demonstrates strong scalability, getting higher accuracy as model size and context length increase.
Causal Tracing of Object Representations in Large Vision Language Models: Mechanistic Interpretability and Hallucination Mitigation
Nov 19, 2025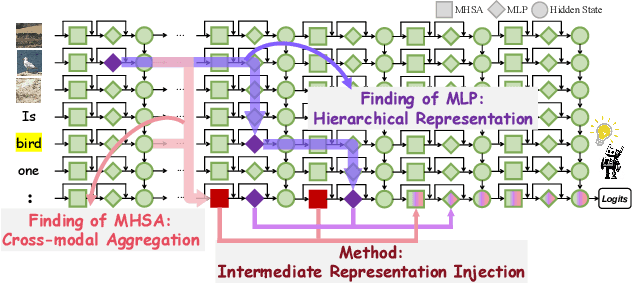

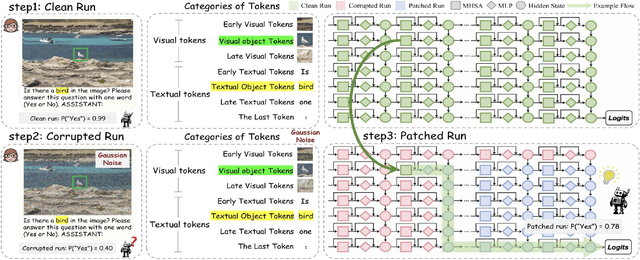
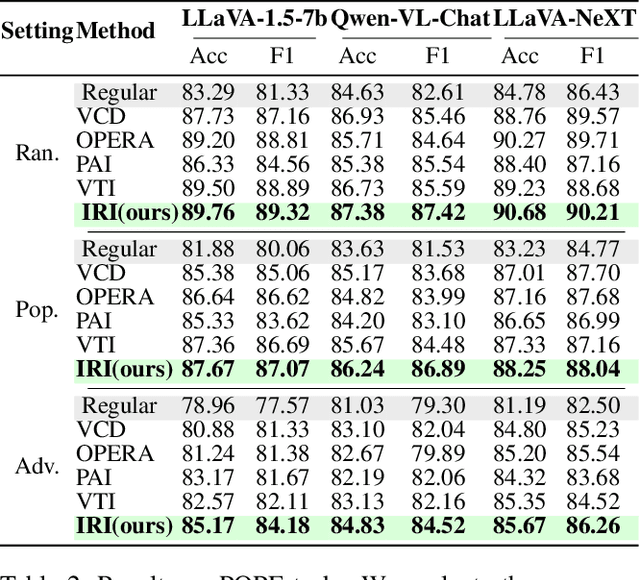
Despite the remarkable advancements of Large Vision-Language Models (LVLMs), the mechanistic interpretability remains underexplored. Existing analyses are insufficiently comprehensive and lack examination covering visual and textual tokens, model components, and the full range of layers. This limitation restricts actionable insights to improve the faithfulness of model output and the development of downstream tasks, such as hallucination mitigation. To address this limitation, we introduce Fine-grained Cross-modal Causal Tracing (FCCT) framework, which systematically quantifies the causal effects on visual object perception. FCCT conducts fine-grained analysis covering the full range of visual and textual tokens, three core model components including multi-head self-attention (MHSA), feed-forward networks (FFNs), and hidden states, across all decoder layers. Our analysis is the first to demonstrate that MHSAs of the last token in middle layers play a critical role in aggregating cross-modal information, while FFNs exhibit a three-stage hierarchical progression for the storage and transfer of visual object representations. Building on these insights, we propose Intermediate Representation Injection (IRI), a training-free inference-time technique that reinforces visual object information flow by precisely intervening on cross-modal representations at specific components and layers, thereby enhancing perception and mitigating hallucination. Consistent improvements across five widely used benchmarks and LVLMs demonstrate IRI achieves state-of-the-art performance, while preserving inference speed and other foundational performance.
Learning Depth from Past Selves: Self-Evolution Contrast for Robust Depth Estimation
Nov 19, 2025Self-supervised depth estimation has gained significant attention in autonomous driving and robotics. However, existing methods exhibit substantial performance degradation under adverse weather conditions such as rain and fog, where reduced visibility critically impairs depth prediction. To address this issue, we propose a novel self-evolution contrastive learning framework called SEC-Depth for self-supervised robust depth estimation tasks. Our approach leverages intermediate parameters generated during training to construct temporally evolving latency models. Using these, we design a self-evolution contrastive scheme to mitigate performance loss under challenging conditions. Concretely, we first design a dynamic update strategy of latency models for the depth estimation task to capture optimization states across training stages. To effectively leverage latency models, we introduce a self-evolution contrastive Loss (SECL) that treats outputs from historical latency models as negative samples. This mechanism adaptively adjusts learning objectives while implicitly sensing weather degradation severity, reducing the needs for manual intervention. Experiments show that our method integrates seamlessly into diverse baseline models and significantly enhances robustness in zero-shot evaluations.
LangGPS: Language Separability Guided Data Pre-Selection for Joint Multilingual Instruction Tuning
Nov 13, 2025Joint multilingual instruction tuning is a widely adopted approach to improve the multilingual instruction-following ability and downstream performance of large language models (LLMs), but the resulting multilingual capability remains highly sensitive to the composition and selection of the training data. Existing selection methods, often based on features like text quality, diversity, or task relevance, typically overlook the intrinsic linguistic structure of multilingual data. In this paper, we propose LangGPS, a lightweight two-stage pre-selection framework guided by language separability which quantifies how well samples in different languages can be distinguished in the model's representation space. LangGPS first filters training data based on separability scores and then refines the subset using existing selection methods. Extensive experiments across six benchmarks and 22 languages demonstrate that applying LangGPS on top of existing selection methods improves their effectiveness and generalizability in multilingual training, especially for understanding tasks and low-resource languages. Further analysis reveals that highly separable samples facilitate the formation of clearer language boundaries and support faster adaptation, while low-separability samples tend to function as bridges for cross-lingual alignment. Besides, we also find that language separability can serve as an effective signal for multilingual curriculum learning, where interleaving samples with diverse separability levels yields stable and generalizable gains. Together, we hope our work offers a new perspective on data utility in multilingual contexts and support the development of more linguistically informed LLMs.
CCFQA: A Benchmark for Cross-Lingual and Cross-Modal Speech and Text Factuality Evaluation
Aug 10, 2025As Large Language Models (LLMs) are increasingly popularized in the multilingual world, ensuring hallucination-free factuality becomes markedly crucial. However, existing benchmarks for evaluating the reliability of Multimodal Large Language Models (MLLMs) predominantly focus on textual or visual modalities with a primary emphasis on English, which creates a gap in evaluation when processing multilingual input, especially in speech. To bridge this gap, we propose a novel \textbf{C}ross-lingual and \textbf{C}ross-modal \textbf{F}actuality benchmark (\textbf{CCFQA}). Specifically, the CCFQA benchmark contains parallel speech-text factual questions across 8 languages, designed to systematically evaluate MLLMs' cross-lingual and cross-modal factuality capabilities. Our experimental results demonstrate that current MLLMs still face substantial challenges on the CCFQA benchmark. Furthermore, we propose a few-shot transfer learning strategy that effectively transfers the Question Answering (QA) capabilities of LLMs in English to multilingual Spoken Question Answering (SQA) tasks, achieving competitive performance with GPT-4o-mini-Audio using just 5-shot training. We release CCFQA as a foundational research resource to promote the development of MLLMs with more robust and reliable speech understanding capabilities. Our code and dataset are available at https://github.com/yxduir/ccfqa.
Adaptive Backtracking for Privacy Protection in Large Language Models
Aug 08, 2025The preservation of privacy has emerged as a critical topic in the era of artificial intelligence. However, current work focuses on user-oriented privacy, overlooking severe enterprise data leakage risks exacerbated by the Retrieval-Augmented Generation paradigm. To address this gap, our paper introduces a novel objective: enterprise-oriented privacy concerns. Achieving this objective requires overcoming two fundamental challenges: existing methods such as data sanitization severely degrade model performance, and the field lacks public datasets for evaluation. We address these challenges with several solutions. (1) To prevent performance degradation, we propose ABack, a training-free mechanism that leverages a Hidden State Model to pinpoint the origin of a leakage intention and rewrite the output safely. (2) To solve the lack of datasets, we construct PriGenQA, a new benchmark for enterprise privacy scenarios in healthcare and finance. To ensure a rigorous evaluation, we move beyond simple static attacks by developing a powerful adaptive attacker with Group Relative Policy Optimization. Experiments show that against this superior adversary, ABack improves the overall privacy utility score by up to 15\% over strong baselines, avoiding the performance trade-offs of prior methods.
IOCC: Aligning Semantic and Cluster Centers for Few-shot Short Text Clustering
Aug 08, 2025In clustering tasks, it is essential to structure the feature space into clear, well-separated distributions. However, because short text representations have limited expressiveness, conventional methods struggle to identify cluster centers that truly capture each category's underlying semantics, causing the representations to be optimized in suboptimal directions. To address this issue, we propose IOCC, a novel few-shot contrastive learning method that achieves alignment between the cluster centers and the semantic centers. IOCC consists of two key modules: Interaction-enhanced Optimal Transport (IEOT) and Center-aware Contrastive Learning (CACL). Specifically, IEOT incorporates semantic interactions between individual samples into the conventional optimal transport problem, and generate pseudo-labels. Based on these pseudo-labels, we aggregate high-confidence samples to construct pseudo-centers that approximate the semantic centers. Next, CACL optimizes text representations toward their corresponding pseudo-centers. As training progresses, the collaboration between the two modules gradually reduces the gap between cluster centers and semantic centers. Therefore, the model will learn a high-quality distribution, improving clustering performance. Extensive experiments on eight benchmark datasets show that IOCC outperforms previous methods, achieving up to 7.34\% improvement on challenging Biomedical dataset and also excelling in clustering stability and efficiency. The code is available at: https://anonymous.4open.science/r/IOCC-C438.
Enhancing Non-English Capabilities of English-Centric Large Language Models through Deep Supervision Fine-Tuning
Mar 05, 2025Large language models (LLMs) have demonstrated significant progress in multilingual language understanding and generation. However, due to the imbalance in training data, their capabilities in non-English languages are limited. Recent studies revealed the English-pivot multilingual mechanism of LLMs, where LLMs implicitly convert non-English queries into English ones at the bottom layers and adopt English for thinking at the middle layers. However, due to the absence of explicit supervision for cross-lingual alignment in the intermediate layers of LLMs, the internal representations during these stages may become inaccurate. In this work, we introduce a deep supervision fine-tuning method (DFT) that incorporates additional supervision in the internal layers of the model to guide its workflow. Specifically, we introduce two training objectives on different layers of LLMs: one at the bottom layers to constrain the conversion of the target language into English, and another at the middle layers to constrain reasoning in English. To effectively achieve the guiding purpose, we designed two types of supervision signals: logits and feature, which represent a stricter constraint and a relatively more relaxed guidance. Our method guides the model to not only consider the final generated result when processing non-English inputs but also ensure the accuracy of internal representations. We conducted extensive experiments on typical English-centric large models, LLaMA-2 and Gemma-2, and the results on multiple multilingual datasets show that our method significantly outperforms traditional fine-tuning methods.
From Hypothesis to Publication: A Comprehensive Survey of AI-Driven Research Support Systems
Mar 03, 2025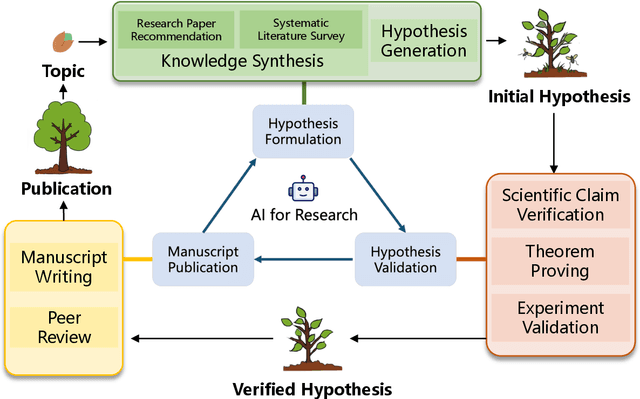
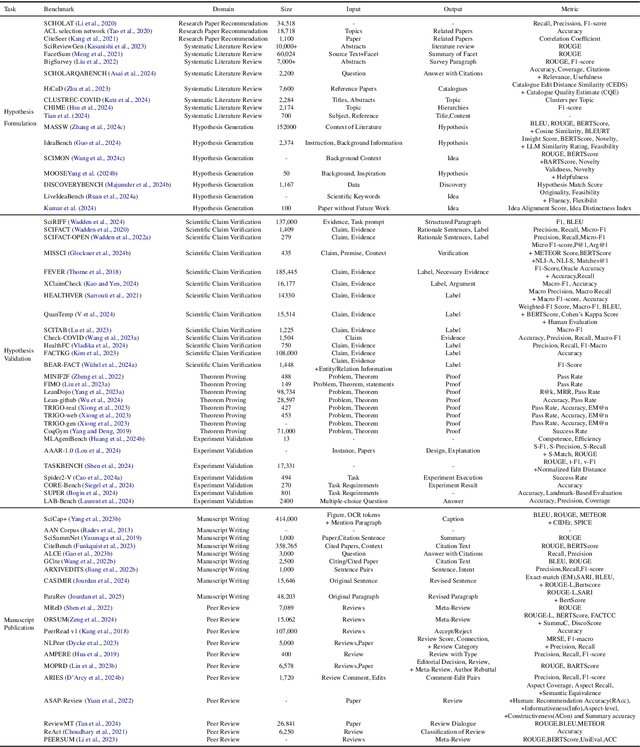

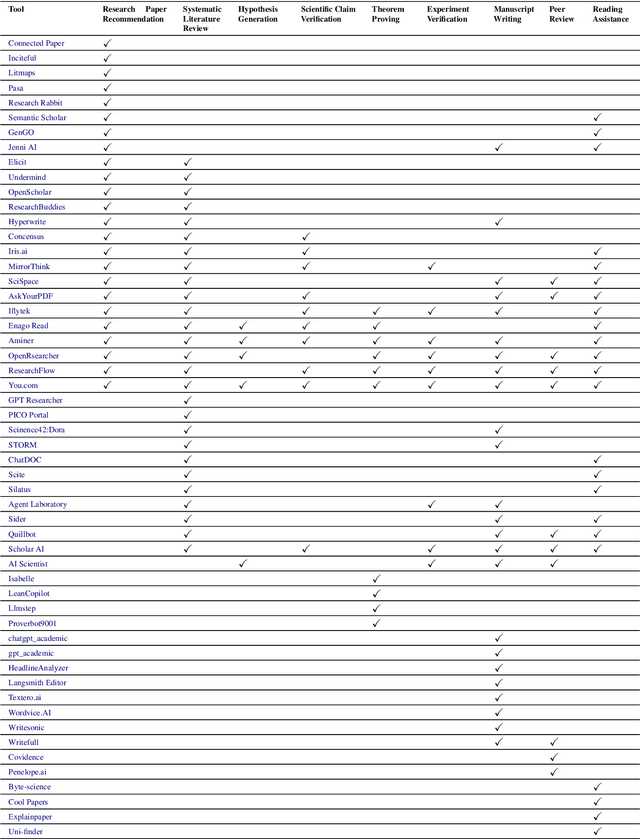
Research is a fundamental process driving the advancement of human civilization, yet it demands substantial time and effort from researchers. In recent years, the rapid development of artificial intelligence (AI) technologies has inspired researchers to explore how AI can accelerate and enhance research. To monitor relevant advancements, this paper presents a systematic review of the progress in this domain. Specifically, we organize the relevant studies into three main categories: hypothesis formulation, hypothesis validation, and manuscript publication. Hypothesis formulation involves knowledge synthesis and hypothesis generation. Hypothesis validation includes the verification of scientific claims, theorem proving, and experiment validation. Manuscript publication encompasses manuscript writing and the peer review process. Furthermore, we identify and discuss the current challenges faced in these areas, as well as potential future directions for research. Finally, we also offer a comprehensive overview of existing benchmarks and tools across various domains that support the integration of AI into the research process. We hope this paper serves as an introduction for beginners and fosters future research. Resources have been made publicly available at https://github.com/zkzhou126/AI-for-Research.