 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 The 3rd Restore Any Image Model (RAIM) Challenge: Professional Image Quality Assessment (Track 1)
Apr 14, 2026In this paper, we present an overview of the NTIRE 2026 challenge on the 3rd Restore Any Image Model in the Wild, specifically focusing on Track 1: Professional Image Quality Assessment. Conventional Image Quality Assessment (IQA) typically relies on scalar scores. By compressing complex visual characteristics into a single number, these methods fundamentally struggle to distinguish subtle differences among uniformly high-quality images. Furthermore, they fail to articulate why one image is superior, lacking the reasoning capabilities required to provide guidance for vision tasks. To bridge this gap, recent advancements in Multimodal Large Language Models (MLLMs) offer a promising paradigm. Inspired by this potential, our challenge establishes a novel benchmark exploring the ability of MLLMs to mimic human expert cognition in evaluating high-quality image pairs. Participants were tasked with overcoming critical bottlenecks in professional scenarios, centering on two primary objectives: (1) Comparative Quality Selection: reliably identifying the visually superior image within a high-quality pair; and (2) Interpretative Reasoning: generating grounded, expert-level explanations that detail the rationale behind the selection. In total, the challenge attracted nearly 200 registrations and over 2,500 submissions. The top-performing methods significantly advanced the state of the art in professional IQA. The challenge dataset is available at https://github.com/narthchin/RAIM-PIQA, and the official homepage is accessible at https://www.codabench.org/competitions/12789/.
Can Large Language Models Simulate Human Cognition Beyond Behavioral Imitation?
Mar 29, 2026An essential problem in artificial intelligence is whether LLMs can simulate human cognition or merely imitate surface-level behaviors, while existing datasets suffer from either synthetic reasoning traces or population-level aggregation, failing to capture authentic individual cognitive patterns. We introduce a benchmark grounded in the longitudinal research trajectories of 217 researchers across diverse domains of artificial intelligence, where each author's scientific publications serve as an externalized representation of their cognitive processes. To distinguish whether LLMs transfer cognitive patterns or merely imitate behaviors, our benchmark deliberately employs a cross-domain, temporal-shift generalization setting. A multidimensional cognitive alignment metric is further proposed to assess individual-level cognitive consistency. Through systematic evaluation of state-of-the-art LLMs and various enhancement techniques, we provide a first-stage empirical study on the questions: (1) How well do current LLMs simulate human cognition? and (2) How far can existing techniques enhance these capabilities?
VFM-Loc: Zero-Shot Cross-View Geo-Localization via Aligning Discriminative Visual Hierarchies
Mar 14, 2026Cross-View Geo-Localization (CVGL) in remote sensing aims to locate a drone-view query by matching it to geo-tagged satellite images. Although supervised methods have achieved strong results on closeset benchmarks, they often fail to generalize to unconstrained, real-world scenarios due to severe viewpoint differences and dataset bias. To overcome these limitations, we present VFM-Loc, a training-free framework for zero-shot CVGL that leverages the generalizable visual representations from vision foundational models (VFMs). VFM-Loc identifies and matches discriminative visual clues across different viewpoints through a progressive alignment strategy. First, we design a hierarchical clue extraction mechanism using Generalized Mean pooling and Scale-Weighted RMAC to preserve distinctive visual clues across scales while maintaining hierarchical confidence. Second, we introduce a statistical manifold alignment pipeline based on domain-wise PCA and Orthogonal Procrustes analysis, linearly aligning heterogeneous feature distributions in a shared metric space. Experiments demonstrate that VFM-Loc exhibits strong zero-shot accuracy on standard benchmarks and surpasses supervised methods by over 20% in Recall@1 on the challenging LO-UCV dataset with large oblique angles. This work highlights that principled alignment of pre-trained features can effectively bridge the cross-view gap, establishing a robust and training-free paradigm for real-world CVGL. The relevant code is made available at: https://github.com/DingLei14/VFM-Loc.
Bridging Cognitive Neuroscience and Graph Intelligence: Hippocampus-Inspired Multi-View Hypergraph Learning for Web Finance Fraud
Jan 16, 2026Online financial services constitute an essential component of contemporary web ecosystems, yet their openness introduces substantial exposure to fraud that harms vulnerable users and weakens trust in digital finance. Such threats have become a significant web harm that erodes societal fairness and affects the well being of online communities. However, existing detection methods based on graph neural networks (GNNs) struggle with two persistent challenges: (1) fraud camouflage, where malicious transactions mimic benign behaviors to evade detection, and (2) long-tailed data distributions, which obscure rare but critical fraudulent cases. To fill these gaps, we propose HIMVH, a Hippocampus-Inspired Multi-View Hypergraph learning model for web finance fraud detection. Specifically, drawing inspiration from the scene conflict monitoring role of the hippocampus, we design a cross-view inconsistency perception module that captures subtle discrepancies and behavioral heterogeneity across multiple transaction views. This module enables the model to identify subtle cross-view conflicts for detecting online camouflaged fraudulent behaviors. Furthermore, inspired by the match-mismatch novelty detection mechanism of the CA1 region, we introduce a novelty-aware hypergraph learning module that measures feature deviations from neighborhood expectations and adaptively reweights messages, thereby enhancing sensitivity to online rare fraud patterns in the long-tailed settings. Extensive experiments on six web-based financial fraud datasets demonstrate that HIMVH achieves 6.42\% improvement in AUC, 9.74\% in F1 and 39.14\% in AP on average over 15 SOTA models.
EEG-FM-Bench: A Comprehensive Benchmark for the Systematic Evaluation of EEG Foundation Models
Aug 25, 2025
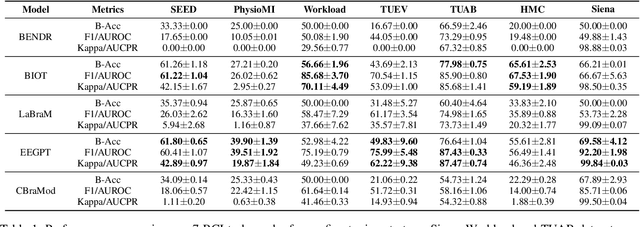
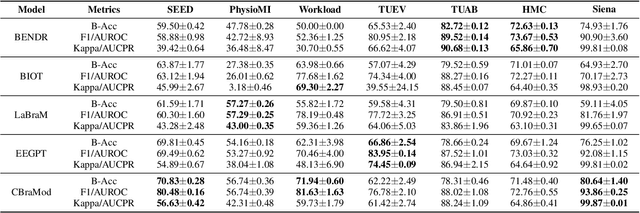
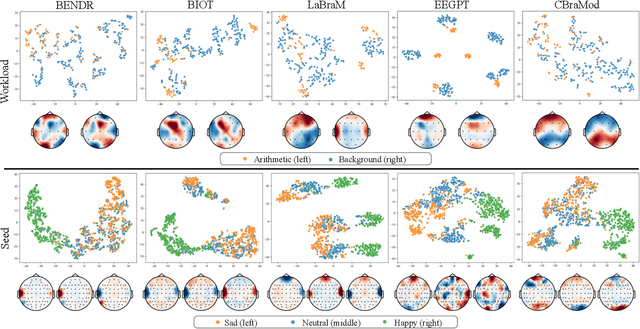
Electroencephalography (EEG) foundation models are poised to significantly advance brain signal analysis by learning robust representations from large-scale, unlabeled datasets. However, their rapid proliferation has outpaced the development of standardized evaluation benchmarks, which complicates direct model comparisons and hinders systematic scientific progress. This fragmentation fosters scientific inefficiency and obscures genuine architectural advancements. To address this critical gap, we introduce EEG-FM-Bench, the first comprehensive benchmark for the systematic and standardized evaluation of EEG foundation models (EEG-FMs). Our contributions are threefold: (1) we curate a diverse suite of downstream tasks and datasets from canonical EEG paradigms, implementing standardized processing and evaluation protocols within a unified open-source framework; (2) we benchmark prominent state-of-the-art foundation models to establish comprehensive baseline results for a clear comparison of the current landscape; (3) we perform qualitative analyses of the learned representations to provide insights into model behavior and inform future architectural design. Through extensive experiments, we find that fine-grained spatio-temporal feature interaction, multitask unified training and neuropsychological priors would contribute to enhancing model performance and generalization capabilities. By offering a unified platform for fair comparison and reproducible research, EEG-FM-Bench seeks to catalyze progress and guide the community toward the development of more robust and generalizable EEG-FMs. Code is released at https://github.com/xw1216/EEG-FM-Bench.
Length Controlled Generation for Black-box LLMs
Dec 19, 2024



Large language models (LLMs) have demonstrated impressive instruction following capabilities, while still struggling to accurately manage the length of the generated text, which is a fundamental requirement in many real-world applications. Existing length control methods involve fine-tuning the parameters of LLMs, which is inefficient and suboptimal for practical use. In this paper, we propose a novel iterative sampling framework for text length control, integrating the Metropolis-Hastings algorithm with an importance sampling acceleration strategy. This framework efficiently and reliably regulates LLMs to generate length-constrained text without modifying the underlying parameters, thereby preserving the original capabilities of LLMs. Experimental results demonstrate that our framework achieves almost 100\% success rates of length control on Llama3.1 for tasks such as length-controlled abstractive summarization and length-constrained instruction following, with minimal additional computational overhead. This also highlights the significant potential of our method for precise length control across a broader range of applications, without compromising the versatility of LLMs.
A Semantic Communication System for Real-time 3D Reconstruction Tasks
Dec 02, 2024



3D semantic maps have played an increasingly important role in high-precision robot localization and scene understanding. However, real-time construction of semantic maps requires mobile edge devices with extremely high computing power, which are expensive and limit the widespread application of semantic mapping. In order to address this limitation, inspired by cloud-edge collaborative computing and the high transmission efficiency of semantic communication, this paper proposes a method to achieve real-time semantic mapping tasks with limited-resource mobile devices. Specifically, we design an encoding-decoding semantic communication framework for real-time semantic mapping tasks under limited-resource situations. In addition, considering the impact of different channel conditions on communication, this paper designs a module based on the attention mechanism to achieve stable data transmission under various channel conditions. In terms of simulation experiments, based on the TUM dataset, it was verified that the system has an error of less than 0.1% compared to the groundtruth in mapping and localization accuracy and is superior to some novel semantic communication algorithms in real-time performance and channel adaptation. Besides, we implement a prototype system to verify the effectiveness of the proposed framework and designed module in real indoor scenarios. The results show that our system can complete real-time semantic mapping tasks for common indoor objects (chairs, computers, people, etc.) with a limited-resource device, and the mapping update time is less than 1 second.
Discrete Modeling via Boundary Conditional Diffusion Processes
Oct 29, 2024

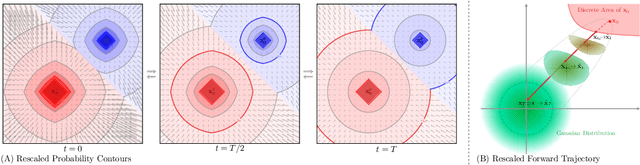

We present an novel framework for efficiently and effectively extending the powerful continuous diffusion processes to discrete modeling. Previous approaches have suffered from the discrepancy between discrete data and continuous modeling. Our study reveals that the absence of guidance from discrete boundaries in learning probability contours is one of the main reasons. To address this issue, we propose a two-step forward process that first estimates the boundary as a prior distribution and then rescales the forward trajectory to construct a boundary conditional diffusion model. The reverse process is proportionally adjusted to guarantee that the learned contours yield more precise discrete data. Experimental results indicate that our approach achieves strong performance in both language modeling and discrete image generation tasks. In language modeling, our approach surpasses previous state-of-the-art continuous diffusion language models in three translation tasks and a summarization task, while also demonstrating competitive performance compared to auto-regressive transformers. Moreover, our method achieves comparable results to continuous diffusion models when using discrete ordinal pixels and establishes a new state-of-the-art for categorical image generation on the Cifar-10 dataset.
BFA-YOLO: Balanced multiscale object detection network for multi-view building facade attachments detection
Sep 06, 2024


Detection of building facade attachments such as doors, windows, balconies, air conditioner units, billboards, and glass curtain walls plays a pivotal role in numerous applications. Building facade attachments detection aids in vbuilding information modeling (BIM) construction and meeting Level of Detail 3 (LOD3) standards. Yet, it faces challenges like uneven object distribution, small object detection difficulty, and background interference. To counter these, we propose BFA-YOLO, a model for detecting facade attachments in multi-view images. BFA-YOLO incorporates three novel innovations: the Feature Balanced Spindle Module (FBSM) for addressing uneven distribution, the Target Dynamic Alignment Task Detection Head (TDATH) aimed at improving small object detection, and the Position Memory Enhanced Self-Attention Mechanism (PMESA) to combat background interference, with each component specifically designed to solve its corresponding challenge. Detection efficacy of deep network models deeply depends on the dataset's characteristics. Existing open source datasets related to building facades are limited by their single perspective, small image pool, and incomplete category coverage. We propose a novel method for building facade attachments detection dataset construction and construct the BFA-3D dataset for facade attachments detection. The BFA-3D dataset features multi-view, accurate labels, diverse categories, and detailed classification. BFA-YOLO surpasses YOLOv8 by 1.8% and 2.9% in mAP@0.5 on the multi-view BFA-3D and street-view Facade-WHU datasets, respectively. These results underscore BFA-YOLO's superior performance in detecting facade attachments.
BeamAggR: Beam Aggregation Reasoning over Multi-source Knowledge for Multi-hop Question Answering
Jun 28, 2024



Large language models (LLMs) have demonstrated strong reasoning capabilities. Nevertheless, they still suffer from factual errors when tackling knowledge-intensive tasks. Retrieval-augmented reasoning represents a promising approach. However, significant challenges still persist, including inaccurate and insufficient retrieval for complex questions, as well as difficulty in integrating multi-source knowledge. To address this, we propose Beam Aggregation Reasoning, BeamAggR, a reasoning framework for knowledge-intensive multi-hop QA. BeamAggR explores and prioritizes promising answers at each hop of question. Concretely, we parse the complex questions into trees, which include atom and composite questions, followed by bottom-up reasoning. For atomic questions, the LLM conducts reasoning on multi-source knowledge to get answer candidates. For composite questions, the LLM combines beam candidates, explores multiple reasoning paths through probabilistic aggregation, and prioritizes the most promising trajectory. Extensive experiments on four open-domain multi-hop reasoning datasets show that our method significantly outperforms SOTA methods by 8.5%. Furthermore, our analysis reveals that BeamAggR elicits better knowledge collaboration and answer aggregation.