 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAST: Mitigating Object Hallucination in Large Vision-Language Models via Caption-Guided Visual Attention Steering
May 06, 2026Although Large Vision-Language Models (LVLMs) have demonstrated remarkable performance on downstream tasks, they frequently produce contents that deviate from visual information, leading to object hallucination. To tackle this, recent works mostly depend on expensive manual annotations and training cost, or decoding strategies which significantly increase inference time. In this work, we observe that LVLMs' attention to visual information is significantly enhanced when answering caption queries compared to non-caption queries. Inspired by this phenomenon, we propose Caption-guided Visual Attention Steering (CAST), a training-free, plug-and-play hallucination mitigation method that leverages the attention activation pattern corresponding to caption queries to enhance LVLMs' visual perception capability. Specifically, we use probing techniques to identify attention heads that are highly sensitive to caption queries and estimate optimized steering directions for their outputs. This steering strengthens LVLM's fine-grained visual perception capabilities, thereby effectively mitigating object hallucination. CAST reduced object hallucination by an average of 6.03% across five widely used LVLMs and five benchmarks including both discriminative and generative tasks, demonstrating state-of-the-art performance while adding little inference cost and preserving other foundational capabilities.
Can Large Language Models Simulate Human Cognition Beyond Behavioral Imitation?
Mar 29, 2026An essential problem in artificial intelligence is whether LLMs can simulate human cognition or merely imitate surface-level behaviors, while existing datasets suffer from either synthetic reasoning traces or population-level aggregation, failing to capture authentic individual cognitive patterns. We introduce a benchmark grounded in the longitudinal research trajectories of 217 researchers across diverse domains of artificial intelligence, where each author's scientific publications serve as an externalized representation of their cognitive processes. To distinguish whether LLMs transfer cognitive patterns or merely imitate behaviors, our benchmark deliberately employs a cross-domain, temporal-shift generalization setting. A multidimensional cognitive alignment metric is further proposed to assess individual-level cognitive consistency. Through systematic evaluation of state-of-the-art LLMs and various enhancement techniques, we provide a first-stage empirical study on the questions: (1) How well do current LLMs simulate human cognition? and (2) How far can existing techniques enhance these capabilities?
PERSONA: Dynamic and Compositional Inference-Time Personality Control via Activation Vector Algebra
Feb 17, 2026Current methods for personality control in Large Language Models rely on static prompting or expensive fine-tuning, failing to capture the dynamic and compositional nature of human traits. We introduce PERSONA, a training-free framework that achieves fine-tuning level performance through direct manipulation of personality vectors in activation space. Our key insight is that personality traits appear as extractable, approximately orthogonal directions in the model's representation space that support algebraic operations. The framework operates through three stages: Persona-Base extracts orthogonal trait vectors via contrastive activation analysis; Persona-Algebra enables precise control through vector arithmetic (scalar multiplication for intensity, addition for composition, subtraction for suppression); and Persona-Flow achieves context-aware adaptation by dynamically composing these vectors during inference. On PersonalityBench, our approach achieves a mean score of 9.60, nearly matching the supervised fine-tuning upper bound of 9.61 without any gradient updates. On our proposed Persona-Evolve benchmark for dynamic personality adaptation, we achieve up to 91% win rates across diverse model families. These results provide evidence that aspects of LLM personality are mathematically tractable, opening new directions for interpretable and efficient behavioral control.
Causal Tracing of Object Representations in Large Vision Language Models: Mechanistic Interpretability and Hallucination Mitigation
Nov 19, 2025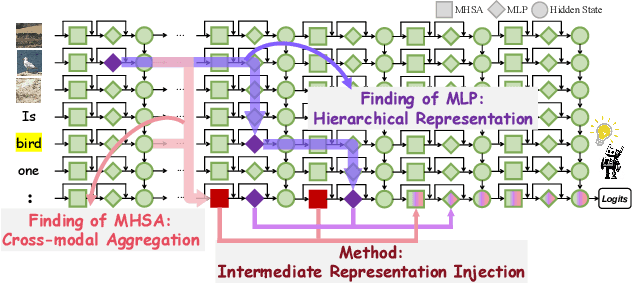

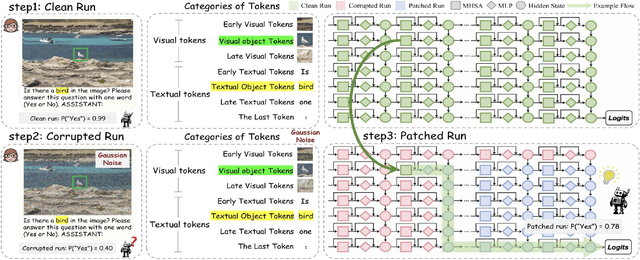
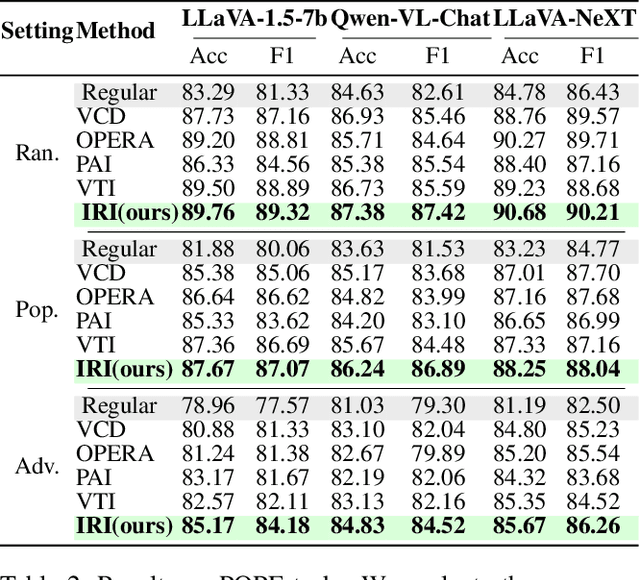
Despite the remarkable advancements of Large Vision-Language Models (LVLMs), the mechanistic interpretability remains underexplored. Existing analyses are insufficiently comprehensive and lack examination covering visual and textual tokens, model components, and the full range of layers. This limitation restricts actionable insights to improve the faithfulness of model output and the development of downstream tasks, such as hallucination mitigation. To address this limitation, we introduce Fine-grained Cross-modal Causal Tracing (FCCT) framework, which systematically quantifies the causal effects on visual object perception. FCCT conducts fine-grained analysis covering the full range of visual and textual tokens, three core model components including multi-head self-attention (MHSA), feed-forward networks (FFNs), and hidden states, across all decoder layers. Our analysis is the first to demonstrate that MHSAs of the last token in middle layers play a critical role in aggregating cross-modal information, while FFNs exhibit a three-stage hierarchical progression for the storage and transfer of visual object representations. Building on these insights, we propose Intermediate Representation Injection (IRI), a training-free inference-time technique that reinforces visual object information flow by precisely intervening on cross-modal representations at specific components and layers, thereby enhancing perception and mitigating hallucination. Consistent improvements across five widely used benchmarks and LVLMs demonstrate IRI achieves state-of-the-art performance, while preserving inference speed and other foundational performance.
Cross-Lingual Text-Rich Visual Comprehension: An Information Theory Perspective
Dec 23, 2024



Recent Large Vision-Language Models (LVLMs) have shown promising reasoning capabilities on text-rich images from charts, tables, and documents. However, the abundant text within such images may increase the model's sensitivity to language. This raises the need to evaluate LVLM performance on cross-lingual text-rich visual inputs, where the language in the image differs from the language of the instructions. To address this, we introduce XT-VQA (Cross-Lingual Text-Rich Visual Question Answering), a benchmark designed to assess how LVLMs handle language inconsistency between image text and questions. XT-VQA integrates five existing text-rich VQA datasets and a newly collected dataset, XPaperQA, covering diverse scenarios that require faithful recognition and comprehension of visual information despite language inconsistency. Our evaluation of prominent LVLMs on XT-VQA reveals a significant drop in performance for cross-lingual scenarios, even for models with multilingual capabilities. A mutual information analysis suggests that this performance gap stems from cross-lingual questions failing to adequately activate relevant visual information. To mitigate this issue, we propose MVCL-MI (Maximization of Vision-Language Cross-Lingual Mutual Information), where a visual-text cross-lingual alignment is built by maximizing mutual information between the model's outputs and visual information. This is achieved by distilling knowledge from monolingual to cross-lingual settings through KL divergence minimization, where monolingual output logits serve as a teacher. Experimental results on the XT-VQA demonstrate that MVCL-MI effectively reduces the visual-text cross-lingual performance disparity while preserving the inherent capabilities of LVLMs, shedding new light on the potential practice for improving LVLMs. Codes are available at: https://github.com/Stardust-y/XTVQA.git
Length Controlled Generation for Black-box LLMs
Dec 19, 2024



Large language models (LLMs) have demonstrated impressive instruction following capabilities, while still struggling to accurately manage the length of the generated text, which is a fundamental requirement in many real-world applications. Existing length control methods involve fine-tuning the parameters of LLMs, which is inefficient and suboptimal for practical use. In this paper, we propose a novel iterative sampling framework for text length control, integrating the Metropolis-Hastings algorithm with an importance sampling acceleration strategy. This framework efficiently and reliably regulates LLMs to generate length-constrained text without modifying the underlying parameters, thereby preserving the original capabilities of LLMs. Experimental results demonstrate that our framework achieves almost 100\% success rates of length control on Llama3.1 for tasks such as length-controlled abstractive summarization and length-constrained instruction following, with minimal additional computational overhead. This also highlights the significant potential of our method for precise length control across a broader range of applications, without compromising the versatility of LLMs.
Discrete Modeling via Boundary Conditional Diffusion Processes
Oct 29, 2024

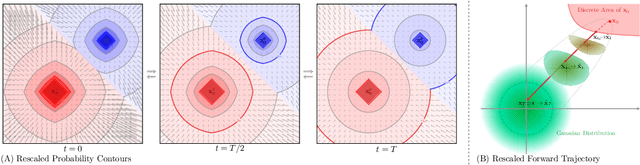

We present an novel framework for efficiently and effectively extending the powerful continuous diffusion processes to discrete modeling. Previous approaches have suffered from the discrepancy between discrete data and continuous modeling. Our study reveals that the absence of guidance from discrete boundaries in learning probability contours is one of the main reasons. To address this issue, we propose a two-step forward process that first estimates the boundary as a prior distribution and then rescales the forward trajectory to construct a boundary conditional diffusion model. The reverse process is proportionally adjusted to guarantee that the learned contours yield more precise discrete data. Experimental results indicate that our approach achieves strong performance in both language modeling and discrete image generation tasks. In language modeling, our approach surpasses previous state-of-the-art continuous diffusion language models in three translation tasks and a summarization task, while also demonstrating competitive performance compared to auto-regressive transformers. Moreover, our method achieves comparable results to continuous diffusion models when using discrete ordinal pixels and establishes a new state-of-the-art for categorical image generation on the Cifar-10 dataset.
Advancing Large Language Model Attribution through Self-Improving
Oct 17, 2024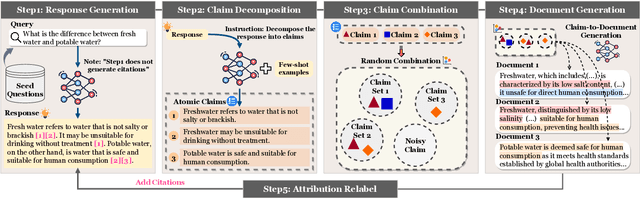
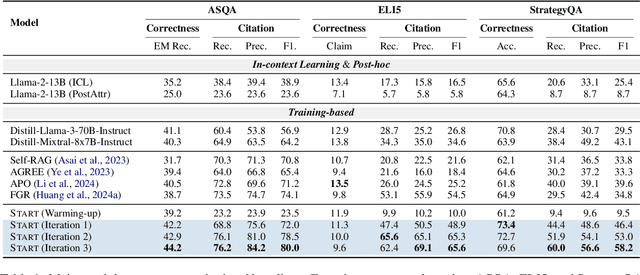
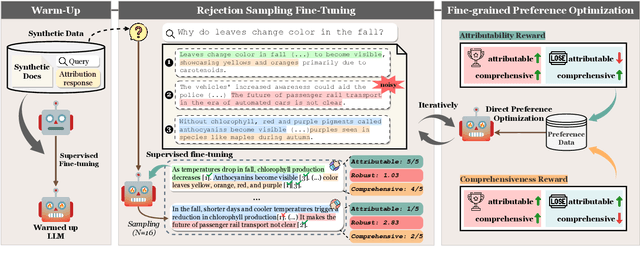
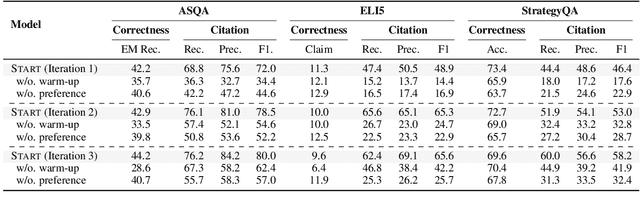
Teaching large language models (LLMs) to generate text with citations to evidence sources can mitigate hallucinations and enhance verifiability in information-seeking systems. However, improving this capability requires high-quality attribution data, which is costly and labor-intensive. Inspired by recent advances in self-improvement that enhance LLMs without manual annotation, we present START, a Self-Taught AttRibuTion framework for iteratively improving the attribution capability of LLMs. First, to prevent models from stagnating due to initially insufficient supervision signals, START leverages the model to self-construct synthetic training data for warming up. To further self-improve the model's attribution ability, START iteratively utilizes fine-grained preference supervision signals constructed from its sampled responses to encourage robust, comprehensive, and attributable generation. Experiments on three open-domain question-answering datasets, covering long-form QA and multi-step reasoning, demonstrate significant performance gains of 25.13% on average without relying on human annotations and more advanced models. Further analysis reveals that START excels in aggregating information across multiple sources.
Learning Fine-Grained Grounded Citations for Attributed Large Language Models
Aug 08, 2024Despite the impressive performance on information-seeking tasks, large language models (LLMs) still struggle with hallucinations. Attributed LLMs, which augment generated text with in-line citations, have shown potential in mitigating hallucinations and improving verifiability. However, current approaches suffer from suboptimal citation quality due to their reliance on in-context learning. Furthermore, the practice of citing only coarse document identifiers makes it challenging for users to perform fine-grained verification. In this work, we introduce FRONT, a training framework designed to teach LLMs to generate Fine-Grained Grounded Citations. By grounding model outputs in fine-grained supporting quotes, these quotes guide the generation of grounded and consistent responses, not only improving citation quality but also facilitating fine-grained verification. Experiments on the ALCE benchmark demonstrate the efficacy of FRONT in generating superior grounded responses and highly supportive citations. With LLaMA-2-7B, the framework significantly outperforms all the baselines, achieving an average of 14.21% improvement in citation quality across all datasets, even surpassing ChatGPT.
Investigating and Mitigating the Multimodal Hallucination Snowballing in Large Vision-Language Models
Jun 30, 2024
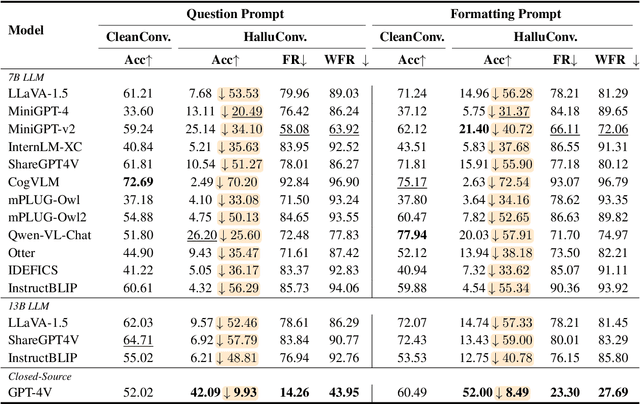
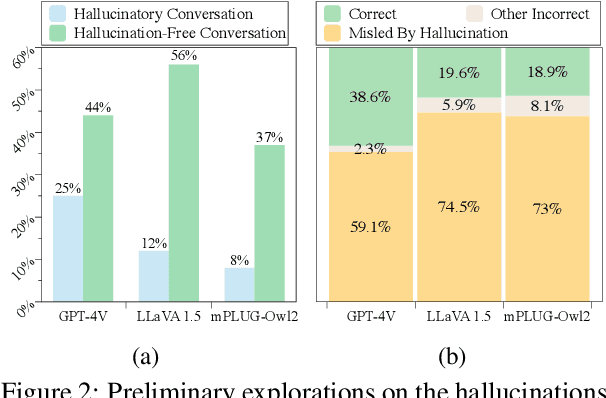
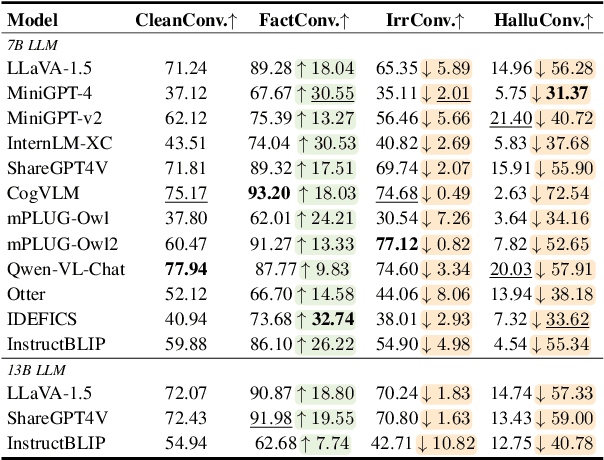
Though advanced in understanding visual information with human languages, Large Vision-Language Models (LVLMs) still suffer from multimodal hallucinations. A natural concern is that during multimodal interaction, the generated hallucinations could influence the LVLMs' subsequent generation. Thus, we raise a question: When presented with a query relevant to the previously generated hallucination, will LVLMs be misled and respond incorrectly, even though the ground visual information exists? To answer this, we propose a framework called MMHalSnowball to evaluate LVLMs' behaviors when encountering generated hallucinations, where LVLMs are required to answer specific visual questions within a curated hallucinatory conversation. Crucially, our experiment shows that the performance of open-source LVLMs drops by at least $31\%$, indicating that LVLMs are prone to accept the generated hallucinations and make false claims that they would not have supported without distractions. We term this phenomenon Multimodal Hallucination Snowballing. To mitigate this, we further propose a training-free method called Residual Visual Decoding, where we revise the output distribution of LVLMs with the one derived from the residual visual input, providing models with direct access to the visual information. Experiments show that our method can mitigate more than $24\%$ of the snowballed multimodal hallucination while maintaining capabilities.