 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Hypothesis to Publication: A Comprehensive Survey of AI-Driven Research Support Systems
Mar 03, 2025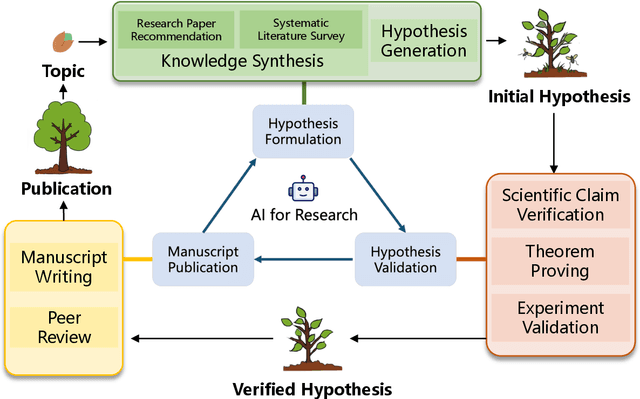
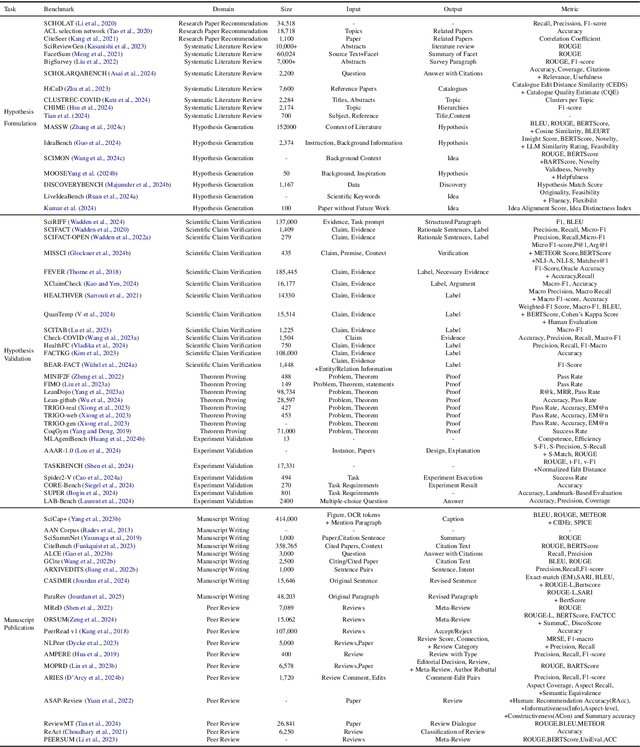

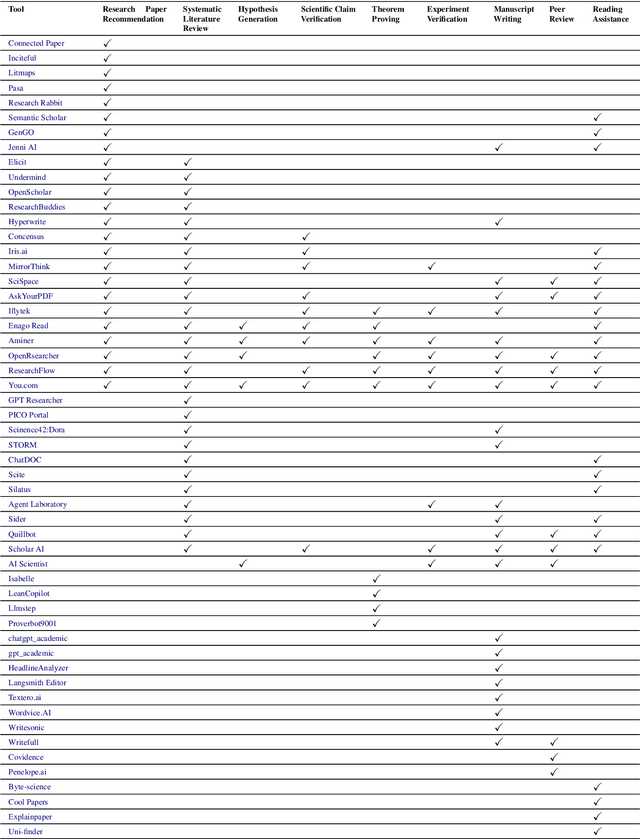
Research is a fundamental process driving the advancement of human civilization, yet it demands substantial time and effort from researchers. In recent years, the rapid development of artificial intelligence (AI) technologies has inspired researchers to explore how AI can accelerate and enhance research. To monitor relevant advancements, this paper presents a systematic review of the progress in this domain. Specifically, we organize the relevant studies into three main categories: hypothesis formulation, hypothesis validation, and manuscript publication. Hypothesis formulation involves knowledge synthesis and hypothesis generation. Hypothesis validation includes the verification of scientific claims, theorem proving, and experiment validation. Manuscript publication encompasses manuscript writing and the peer review process. Furthermore, we identify and discuss the current challenges faced in these areas, as well as potential future directions for research. Finally, we also offer a comprehensive overview of existing benchmarks and tools across various domains that support the integration of AI into the research process. We hope this paper serves as an introduction for beginners and fosters future research. Resources have been made publicly available at https://github.com/zkzhou126/AI-for-Research.
Cross-Lingual Text-Rich Visual Comprehension: An Information Theory Perspective
Dec 23, 2024



Recent Large Vision-Language Models (LVLMs) have shown promising reasoning capabilities on text-rich images from charts, tables, and documents. However, the abundant text within such images may increase the model's sensitivity to language. This raises the need to evaluate LVLM performance on cross-lingual text-rich visual inputs, where the language in the image differs from the language of the instructions. To address this, we introduce XT-VQA (Cross-Lingual Text-Rich Visual Question Answering), a benchmark designed to assess how LVLMs handle language inconsistency between image text and questions. XT-VQA integrates five existing text-rich VQA datasets and a newly collected dataset, XPaperQA, covering diverse scenarios that require faithful recognition and comprehension of visual information despite language inconsistency. Our evaluation of prominent LVLMs on XT-VQA reveals a significant drop in performance for cross-lingual scenarios, even for models with multilingual capabilities. A mutual information analysis suggests that this performance gap stems from cross-lingual questions failing to adequately activate relevant visual information. To mitigate this issue, we propose MVCL-MI (Maximization of Vision-Language Cross-Lingual Mutual Information), where a visual-text cross-lingual alignment is built by maximizing mutual information between the model's outputs and visual information. This is achieved by distilling knowledge from monolingual to cross-lingual settings through KL divergence minimization, where monolingual output logits serve as a teacher. Experimental results on the XT-VQA demonstrate that MVCL-MI effectively reduces the visual-text cross-lingual performance disparity while preserving the inherent capabilities of LVLMs, shedding new light on the potential practice for improving LVLMs. Codes are available at: https://github.com/Stardust-y/XTVQA.git
Rapid and Accurate Diagnosis of Acute Aortic Syndrome using Non-contrast CT: A Large-scale, Retrospective, Multi-center and AI-based Study
Jun 25, 2024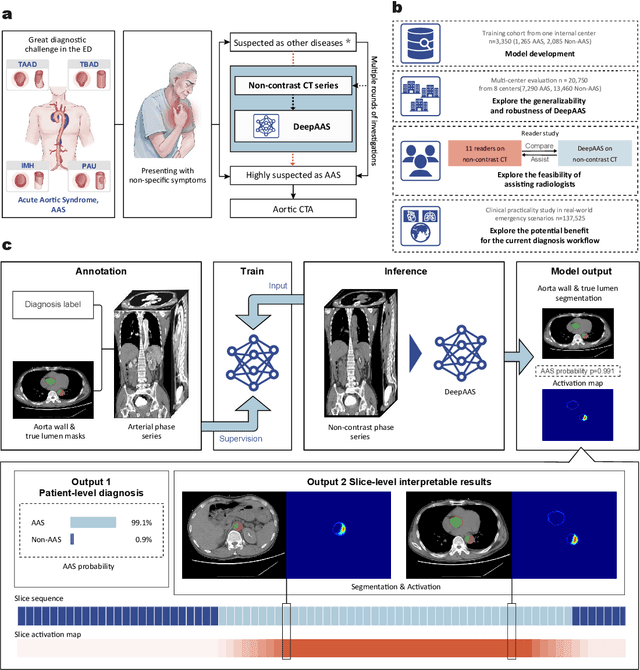
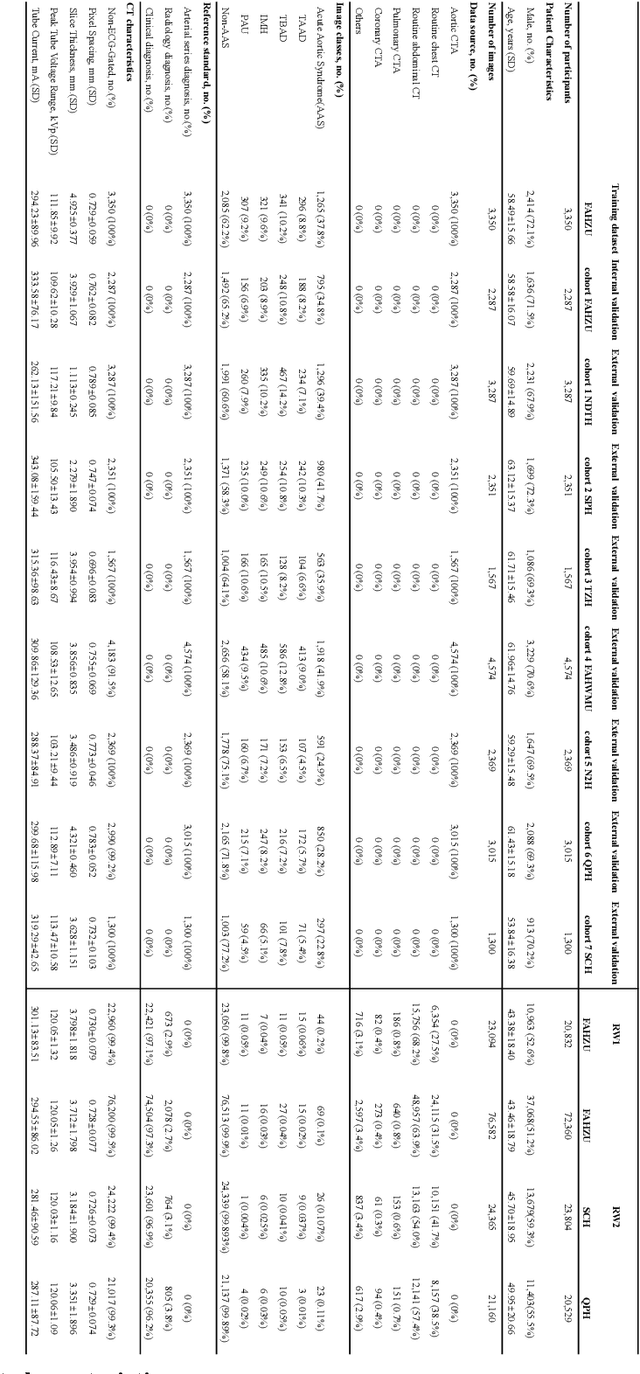
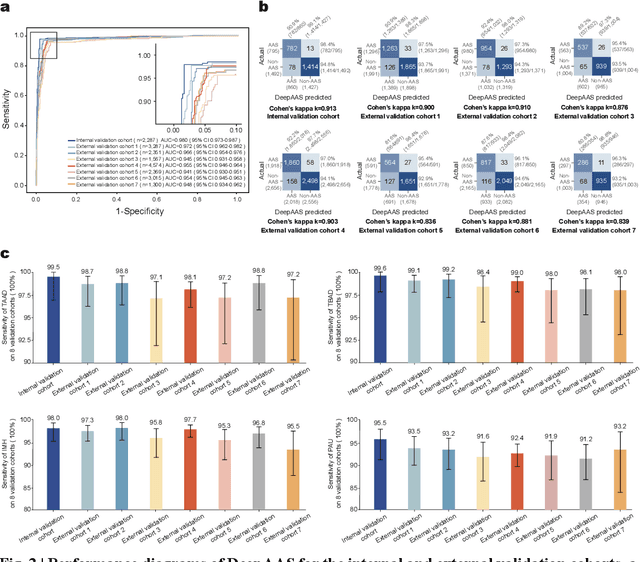
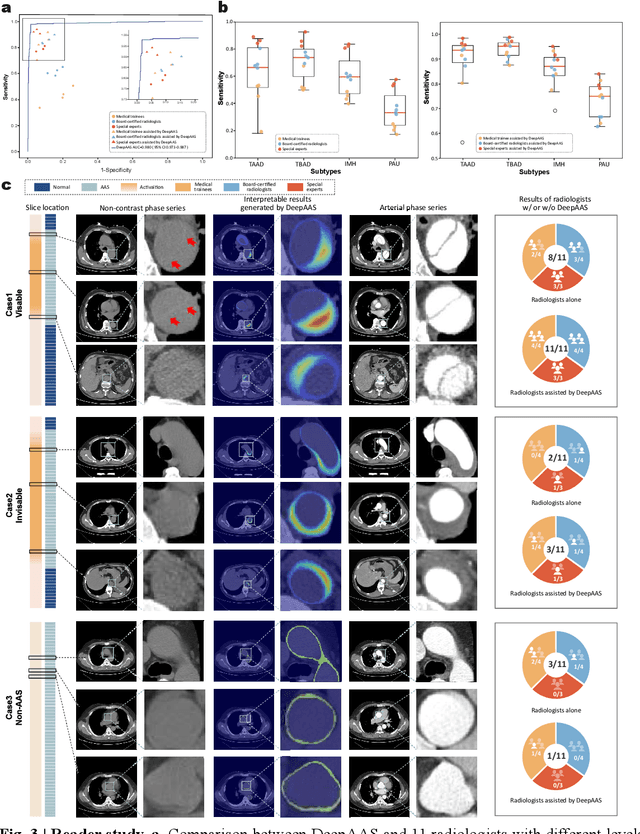
Chest pain symptoms are highly prevalent in emergency departments (EDs), where acute aortic syndrome (AAS) is a catastrophic cardiovascular emergency with a high fatality rate, especially when timely and accurate treatment is not administered. However, current triage practices in the ED can cause up to approximately half of patients with AAS to have an initially missed diagnosis or be misdiagnosed as having other acute chest pain conditions. Subsequently, these AAS patients will undergo clinically inaccurate or suboptimal differential diagnosis. Fortunately, even under these suboptimal protocols, nearly all these patients underwent non-contrast CT covering the aorta anatomy at the early stage of differential diagnosis. In this study, we developed an artificial intelligence model (DeepAAS) using non-contrast CT, which is highly accurate for identifying AAS and provides interpretable results to assist in clinical decision-making. Performance was assessed in two major phases: a multi-center retrospective study (n = 20,750) and an exploration in real-world emergency scenarios (n = 137,525). In the multi-center cohort, DeepAAS achieved a mean area under the receiver operating characteristic curve of 0.958 (95% CI 0.950-0.967). In the real-world cohort, DeepAAS detected 109 AAS patients with misguided initial suspicion, achieving 92.6% (95% CI 76.2%-97.5%) in mean sensitivity and 99.2% (95% CI 99.1%-99.3%) in mean specificity. Our AI model performed well on non-contrast CT at all applicable early stages of differential diagnosis workflows, effectively reduced the overall missed diagnosis and misdiagnosis rate from 48.8% to 4.8% and shortened the diagnosis time for patients with misguided initial suspicion from an average of 681.8 (74-11,820) mins to 68.5 (23-195) mins. DeepAAS could effectively fill the gap in the current clinical workflow without requiring additional tests.