 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMIBench: Benchmarking Olympiad-Level Multi-Image Reasoning in Large Vision-Language Model
Apr 22, 2026Large vision-language models (LVLMs) have made substantial advances in reasoning tasks at the Olympiad level. Nevertheless, current Olympiad-level multimodal reasoning benchmarks for these models often emphasize single-image analysis and fail to exploit contextual information across multiple images. We present OMIBench, a benchmark designed to evaluate Olympiad-level reasoning when the required evidence is distributed over multiple images. It contains problems from biology, chemistry, mathematics, and physics Olympiads, together with manually annotated rationales and evaluation protocols for both exact and semantic answer matching. Across extensive experiments on OMIBench, we observe meaningful performance gaps in existing models. Even the strongest LVLMs, such as Gemini-3-Pro, attain only about 50% on the benchmark. These results position OMIBench as a focused resources for studying and improving multi-image reasoning in LVLMs.
SAVOIR: Learning Social Savoir-Faire via Shapley-based Reward Attribution
Apr 21, 2026Social intelligence, the ability to navigate complex interpersonal interactions, presents a fundamental challenge for language agents. Training such agents via reinforcement learning requires solving the credit assignment problem: determining how individual utterances contribute to multi-turn dialogue outcomes. Existing approaches directly employ language models to distribute episode-level rewards, yielding attributions that are retrospective and lack theoretical grounding. We propose SAVOIR (ShApley Value fOr SocIal RL), a novel principled framework grounded in cooperative game theory. Our approach combines two complementary principles: expected utility shifts evaluation from retrospective attribution to prospective valuation, capturing an utterance's strategic potential for enabling favorable future trajectories; Shapley values ensure fair credit distribution with axiomatic guarantees of efficiency, symmetry, and marginality. Experiments on the SOTOPIA benchmark demonstrate that SAVOIR achieves new state-of-the-art performance across all evaluation settings, with our 7B model matching or exceeding proprietary models including GPT-4o and Claude-3.5-Sonnet. Notably, even large reasoning models consistently underperform, suggesting social intelligence requires qualitatively different capabilities than analytical reasoning.
Stratagem: Learning Transferable Reasoning via Trajectory-Modulated Game Self-Play
Apr 20, 2026Games offer a compelling paradigm for developing general reasoning capabilities in language models, as they naturally demand strategic planning, probabilistic inference, and adaptive decision-making. However, existing self-play approaches rely solely on terminal game outcomes, providing no mechanism to distinguish transferable reasoning patterns from game-specific heuristics. We present STRATAGEM, which addresses two fundamental barriers to reasoning transfer: domain specificity, where learned patterns remain anchored in game semantics, and contextual stasis, where static game contexts fail to cultivate progressive reasoning. STRATAGEM selectively reinforces trajectories exhibiting abstract, domain-agnostic reasoning through a Reasoning Transferability Coefficient, while incentivizing adaptive reasoning development via a Reasoning Evolution Reward. Experiments across mathematical reasoning, general reasoning, and code generation benchmarks demonstrate substantial improvements, with particularly strong gains on competition-level mathematics where multi-step reasoning is critical. Ablation studies and human evaluation confirm that both components contribute to transferable reasoning.
ImplicitMemBench: Measuring Unconscious Behavioral Adaptation in Large Language Models
Apr 09, 2026Existing memory benchmarks for LLM agents evaluate explicit recall of facts, yet overlook implicit memory where experience becomes automated behavior without conscious retrieval. This gap is critical: effective assistants must automatically apply learned procedures or avoid failed actions without explicit reminders. We introduce ImplicitMemBench, the first systematic benchmark evaluating implicit memory through three cognitively grounded constructs drawn from standard cognitive-science accounts of non-declarative memory: Procedural Memory (one-shot skill acquisition after interference), Priming (theme-driven bias via paired experimental/control instances), and Classical Conditioning (Conditioned Stimulus--Unconditioned Stimulus (CS--US) associations shaping first decisions). Our 300-item suite employs a unified Learning/Priming-Interfere-Test protocol with first-attempt scoring. Evaluation of 17 models reveals severe limitations: no model exceeds 66% overall, with top performers DeepSeek-R1 (65.3%), Qwen3-32B (64.1%), and GPT-5 (63.0%) far below human baselines. Analysis uncovers dramatic asymmetries (inhibition 17.6% vs. preference 75.0%) and universal bottlenecks requiring architectural innovations beyond parameter scaling. ImplicitMemBench reframes evaluation from "what agents recall" to "what they automatically enact".
PERSONA: Dynamic and Compositional Inference-Time Personality Control via Activation Vector Algebra
Feb 17, 2026Current methods for personality control in Large Language Models rely on static prompting or expensive fine-tuning, failing to capture the dynamic and compositional nature of human traits. We introduce PERSONA, a training-free framework that achieves fine-tuning level performance through direct manipulation of personality vectors in activation space. Our key insight is that personality traits appear as extractable, approximately orthogonal directions in the model's representation space that support algebraic operations. The framework operates through three stages: Persona-Base extracts orthogonal trait vectors via contrastive activation analysis; Persona-Algebra enables precise control through vector arithmetic (scalar multiplication for intensity, addition for composition, subtraction for suppression); and Persona-Flow achieves context-aware adaptation by dynamically composing these vectors during inference. On PersonalityBench, our approach achieves a mean score of 9.60, nearly matching the supervised fine-tuning upper bound of 9.61 without any gradient updates. On our proposed Persona-Evolve benchmark for dynamic personality adaptation, we achieve up to 91% win rates across diverse model families. These results provide evidence that aspects of LLM personality are mathematically tractable, opening new directions for interpretable and efficient behavioral control.
Proxy Compression for Language Modeling
Feb 04, 2026Modern language models are trained almost exclusively on token sequences produced by a fixed tokenizer, an external lossless compressor often over UTF-8 byte sequences, thereby coupling the model to that compressor. This work introduces proxy compression, an alternative training scheme that preserves the efficiency benefits of compressed inputs while providing an end-to-end, raw-byte interface at inference time. During training, one language model is jointly trained on raw byte sequences and compressed views generated by external compressors; through the process, the model learns to internally align compressed sequences and raw bytes. This alignment enables strong transfer between the two formats, even when training predominantly on compressed inputs which are discarded at inference. Extensive experiments on code language modeling demonstrate that proxy compression substantially improves training efficiency and significantly outperforms pure byte-level baselines given fixed compute budgets. As model scale increases, these gains become more pronounced, and proxy-trained models eventually match or rival tokenizer approaches, all while operating solely on raw bytes and retaining the inherent robustness of byte-level modeling.
Fine-Mem: Fine-Grained Feedback Alignment for Long-Horizon Memory Management
Jan 13, 2026Effective memory management is essential for large language model agents to navigate long-horizon tasks. Recent research has explored using Reinforcement Learning to develop specialized memory manager agents. However, existing approaches rely on final task performance as the primary reward, which results in severe reward sparsity and ineffective credit assignment, providing insufficient guidance for individual memory operations. To this end, we propose Fine-Mem, a unified framework designed for fine-grained feedback alignment. First, we introduce a Chunk-level Step Reward to provide immediate step-level supervision via auxiliary chunk-specific question answering tasks. Second, we devise Evidence-Anchored Reward Attribution to redistribute global rewards by anchoring credit to key memory operations, based on the specific memory items utilized as evidence in reasoning. Together, these components enable stable policy optimization and align local memory operations with the long-term utility of memory. Experiments on Memalpha and MemoryAgentBench demonstrate that Fine-Mem consistently outperforms strong baselines, achieving superior success rates across various sub-tasks. Further analysis reveals its adaptability and strong generalization capabilities across diverse model configurations and backbones.
Causal Tracing of Object Representations in Large Vision Language Models: Mechanistic Interpretability and Hallucination Mitigation
Nov 19, 2025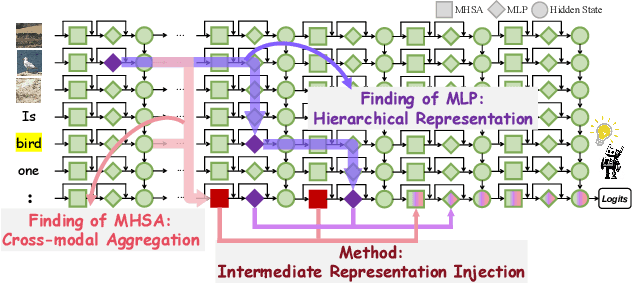

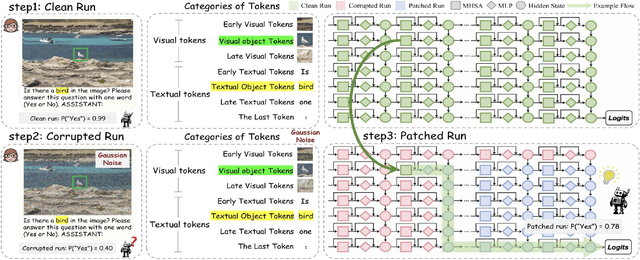
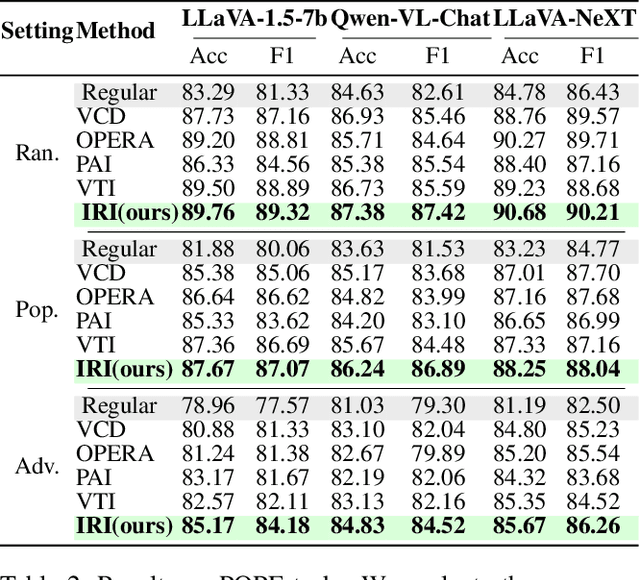
Despite the remarkable advancements of Large Vision-Language Models (LVLMs), the mechanistic interpretability remains underexplored. Existing analyses are insufficiently comprehensive and lack examination covering visual and textual tokens, model components, and the full range of layers. This limitation restricts actionable insights to improve the faithfulness of model output and the development of downstream tasks, such as hallucination mitigation. To address this limitation, we introduce Fine-grained Cross-modal Causal Tracing (FCCT) framework, which systematically quantifies the causal effects on visual object perception. FCCT conducts fine-grained analysis covering the full range of visual and textual tokens, three core model components including multi-head self-attention (MHSA), feed-forward networks (FFNs), and hidden states, across all decoder layers. Our analysis is the first to demonstrate that MHSAs of the last token in middle layers play a critical role in aggregating cross-modal information, while FFNs exhibit a three-stage hierarchical progression for the storage and transfer of visual object representations. Building on these insights, we propose Intermediate Representation Injection (IRI), a training-free inference-time technique that reinforces visual object information flow by precisely intervening on cross-modal representations at specific components and layers, thereby enhancing perception and mitigating hallucination. Consistent improvements across five widely used benchmarks and LVLMs demonstrate IRI achieves state-of-the-art performance, while preserving inference speed and other foundational performance.
LangGPS: Language Separability Guided Data Pre-Selection for Joint Multilingual Instruction Tuning
Nov 13, 2025Joint multilingual instruction tuning is a widely adopted approach to improve the multilingual instruction-following ability and downstream performance of large language models (LLMs), but the resulting multilingual capability remains highly sensitive to the composition and selection of the training data. Existing selection methods, often based on features like text quality, diversity, or task relevance, typically overlook the intrinsic linguistic structure of multilingual data. In this paper, we propose LangGPS, a lightweight two-stage pre-selection framework guided by language separability which quantifies how well samples in different languages can be distinguished in the model's representation space. LangGPS first filters training data based on separability scores and then refines the subset using existing selection methods. Extensive experiments across six benchmarks and 22 languages demonstrate that applying LangGPS on top of existing selection methods improves their effectiveness and generalizability in multilingual training, especially for understanding tasks and low-resource languages. Further analysis reveals that highly separable samples facilitate the formation of clearer language boundaries and support faster adaptation, while low-separability samples tend to function as bridges for cross-lingual alignment. Besides, we also find that language separability can serve as an effective signal for multilingual curriculum learning, where interleaving samples with diverse separability levels yields stable and generalizable gains. Together, we hope our work offers a new perspective on data utility in multilingual contexts and support the development of more linguistically informed LLMs.
Adaptive Backtracking for Privacy Protection in Large Language Models
Aug 08, 2025The preservation of privacy has emerged as a critical topic in the era of artificial intelligence. However, current work focuses on user-oriented privacy, overlooking severe enterprise data leakage risks exacerbated by the Retrieval-Augmented Generation paradigm. To address this gap, our paper introduces a novel objective: enterprise-oriented privacy concerns. Achieving this objective requires overcoming two fundamental challenges: existing methods such as data sanitization severely degrade model performance, and the field lacks public datasets for evaluation. We address these challenges with several solutions. (1) To prevent performance degradation, we propose ABack, a training-free mechanism that leverages a Hidden State Model to pinpoint the origin of a leakage intention and rewrite the output safely. (2) To solve the lack of datasets, we construct PriGenQA, a new benchmark for enterprise privacy scenarios in healthcare and finance. To ensure a rigorous evaluation, we move beyond simple static attacks by developing a powerful adaptive attacker with Group Relative Policy Optimization. Experiments show that against this superior adversary, ABack improves the overall privacy utility score by up to 15\% over strong baselines, avoiding the performance trade-offs of prior methods.