 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARAG-R1: Beyond Single Retriever via Reinforcement-Learned Multi-Tool Agentic Retrieval
Oct 31, 2025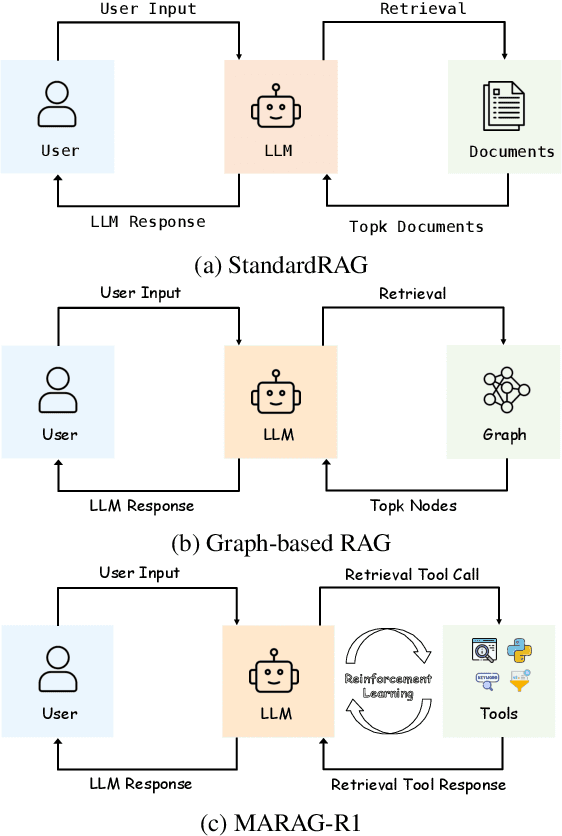
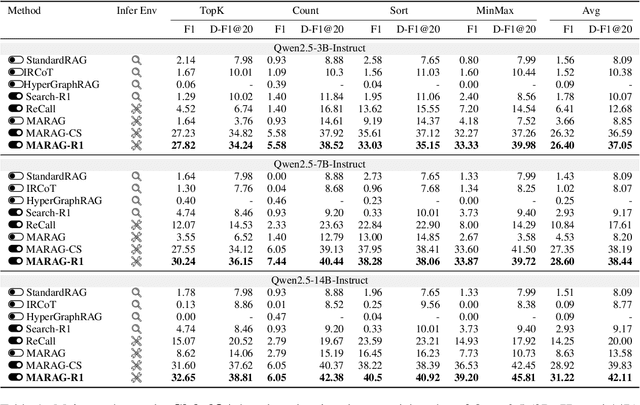
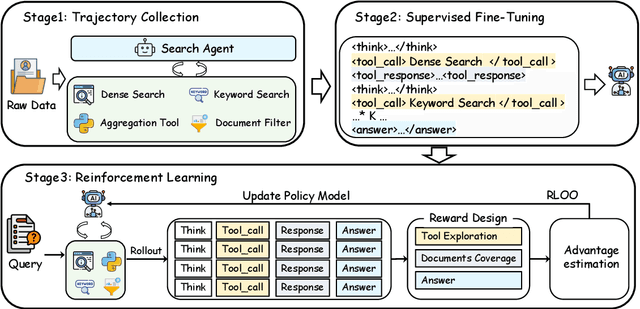
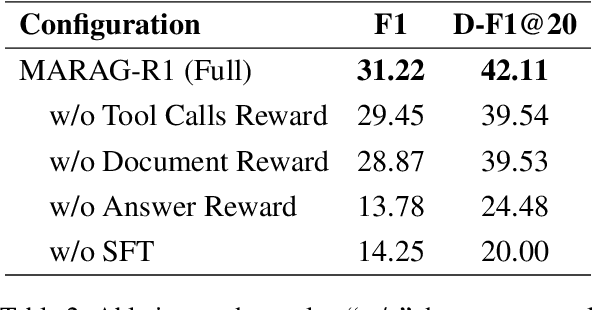
Large Language Models (LLMs) excel at reasoning and generation but are inherently limited by static pretraining data, resulting in factual inaccuracies and weak adaptability to new information. Retrieval-Augmented Generation (RAG) addresses this issue by grounding LLMs in external knowledge; However, the effectiveness of RAG critically depends on whether the model can adequately access relevant information. Existing RAG systems rely on a single retriever with fixed top-k selection, restricting access to a narrow and static subset of the corpus. As a result, this single-retriever paradigm has become the primary bottleneck for comprehensive external information acquisition, especially in tasks requiring corpus-level reasoning. To overcome this limitation, we propose MARAG-R1, a reinforcement-learned multi-tool RAG framework that enables LLMs to dynamically coordinate multiple retrieval mechanisms for broader and more precise information access. MARAG-R1 equips the model with four retrieval tools -- semantic search, keyword search, filtering, and aggregation -- and learns both how and when to use them through a two-stage training process: supervised fine-tuning followed by reinforcement learning. This design allows the model to interleave reasoning and retrieval, progressively gathering sufficient evidence for corpus-level synthesis. Experiments on GlobalQA, HotpotQA, and 2WikiMultiHopQA demonstrate that MARAG-R1 substantially outperforms strong baselines and achieves new state-of-the-art results in corpus-level reasoning tasks.
Towards Global Retrieval Augmented Generation: A Benchmark for Corpus-Level Reasoning
Oct 30, 2025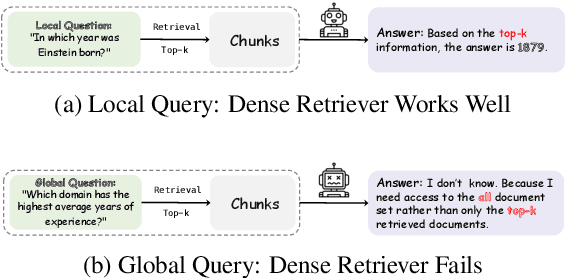
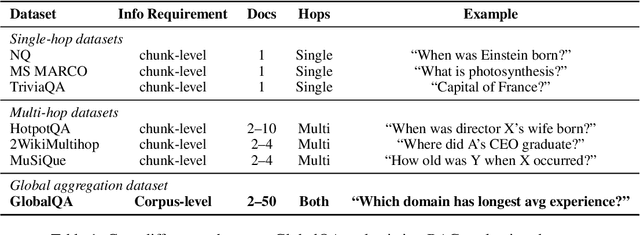
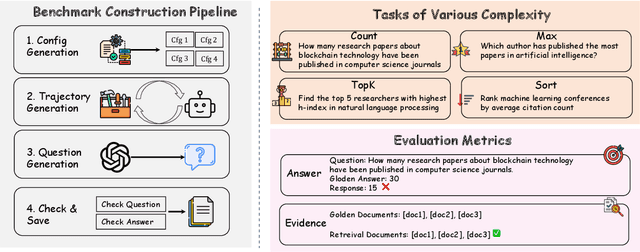
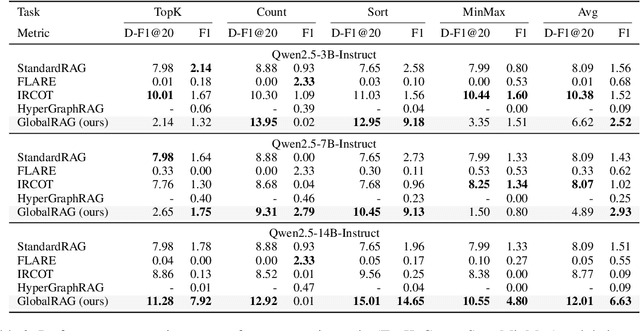
Retrieval-augmented generation (RAG) has emerged as a leading approach to reducing hallucinations in large language models (LLMs). Current RAG evaluation benchmarks primarily focus on what we call local RAG: retrieving relevant chunks from a small subset of documents to answer queries that require only localized understanding within specific text chunks. However, many real-world applications require a fundamentally different capability -- global RAG -- which involves aggregating and analyzing information across entire document collections to derive corpus-level insights (for example, "What are the top 10 most cited papers in 2023?"). In this paper, we introduce GlobalQA -- the first benchmark specifically designed to evaluate global RAG capabilities, covering four core task types: counting, extremum queries, sorting, and top-k extraction. Through systematic evaluation across different models and baselines, we find that existing RAG methods perform poorly on global tasks, with the strongest baseline achieving only 1.51 F1 score. To address these challenges, we propose GlobalRAG, a multi-tool collaborative framework that preserves structural coherence through chunk-level retrieval, incorporates LLM-driven intelligent filters to eliminate noisy documents, and integrates aggregation modules for precise symbolic computation. On the Qwen2.5-14B model, GlobalRAG achieves 6.63 F1 compared to the strongest baseline's 1.51 F1, validating the effectiveness of our method.
R3-RAG: Learning Step-by-Step Reasoning and Retrieval for LLMs via Reinforcement Learning
May 26, 2025



Retrieval-Augmented Generation (RAG) integrates external knowledge with Large Language Models (LLMs) to enhance factual correctness and mitigate hallucination. However, dense retrievers often become the bottleneck of RAG systems due to their limited parameters compared to LLMs and their inability to perform step-by-step reasoning. While prompt-based iterative RAG attempts to address these limitations, it is constrained by human-designed workflows. To address these limitations, we propose $\textbf{R3-RAG}$, which uses $\textbf{R}$einforcement learning to make the LLM learn how to $\textbf{R}$eason and $\textbf{R}$etrieve step by step, thus retrieving comprehensive external knowledge and leading to correct answers. R3-RAG is divided into two stages. We first use cold start to make the model learn the manner of iteratively interleaving reasoning and retrieval. Then we use reinforcement learning to further harness its ability to better explore the external retrieval environment. Specifically, we propose two rewards for R3-RAG: 1) answer correctness for outcome reward, which judges whether the trajectory leads to a correct answer; 2) relevance-based document verification for process reward, encouraging the model to retrieve documents that are relevant to the user question, through which we can let the model learn how to iteratively reason and retrieve relevant documents to get the correct answer. Experimental results show that R3-RAG significantly outperforms baselines and can transfer well to different retrievers. We release R3-RAG at https://github.com/Yuan-Li-FNLP/R3-RAG.
Understanding the Role of LLMs in Multimodal Evaluation Benchmarks
Oct 16, 2024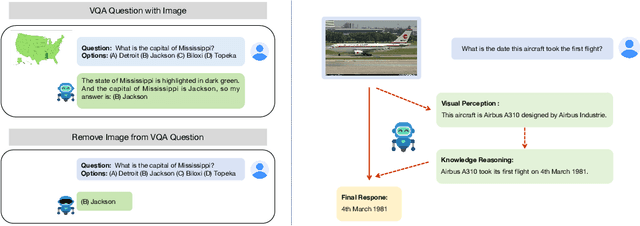
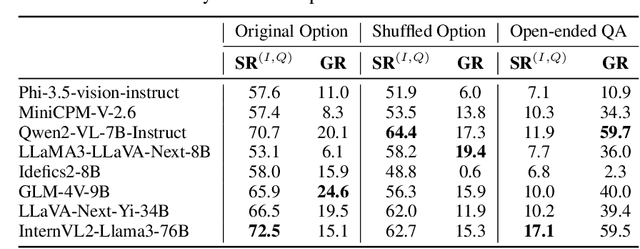
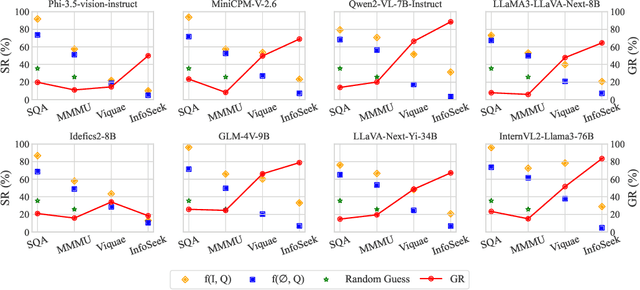
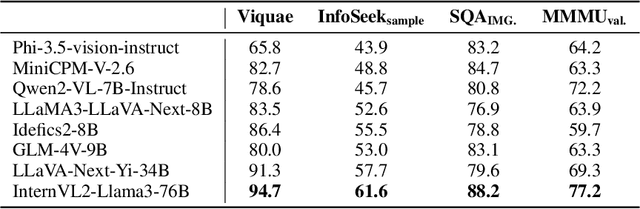
The rapid advancement of Multimodal Large Language Models (MLLMs) has been accompanied by the development of various benchmarks to evaluate their capabilities. However, the true nature of these evaluations and the extent to which they assess multimodal reasoning versus merely leveraging the underlying Large Language Model (LLM) backbone remain unclear. This paper presents a comprehensive investigation into the role of LLM backbones in MLLM evaluation, focusing on two critical aspects: the degree to which current benchmarks truly assess multimodal reasoning and the influence of LLM prior knowledge on performance. Specifically, we introduce a modified evaluation protocol to disentangle the contributions of the LLM backbone from multimodal integration, and an automatic knowledge identification technique for diagnosing whether LLMs equip the necessary knowledge for corresponding multimodal questions. Our study encompasses four diverse MLLM benchmarks and eight state-of-the-art MLLMs. Key findings reveal that some benchmarks allow high performance even without visual inputs and up to 50\% of error rates can be attributed to insufficient world knowledge in the LLM backbone, indicating a heavy reliance on language capabilities. To address knowledge deficiencies, we propose a knowledge augmentation pipeline that achieves significant performance gains, with improvements of up to 60\% on certain datasets, resulting in a approximately 4x increase in performance. Our work provides crucial insights into the role of the LLM backbone in MLLMs, and highlights the need for more nuanced benchmarking approaches.
Case2Code: Learning Inductive Reasoning with Synthetic Data
Jul 17, 2024



Complex reasoning is an impressive ability shown by large language models (LLMs). Most LLMs are skilled in deductive reasoning, such as chain-of-thought prompting or iterative tool-using to solve challenging tasks step-by-step. In this paper, we hope to focus on evaluating and teaching LLMs to conduct inductive reasoning, that is, LLMs are supposed to infer underlying rules by observing examples or sequential transformations. However, collecting large-scale and diverse human-generated inductive data is challenging. We focus on data synthesis in the code domain and propose a \textbf{Case2Code} task by exploiting the expressiveness and correctness of programs. Specifically, we collect a diverse set of executable programs, synthesize input-output transformations for each program, and force LLMs to infer the underlying code implementations based on the synthetic I/O cases. We first evaluate representative LLMs on the synthesized Case2Code task and demonstrate that the Case-to-code induction is challenging for LLMs. Then, we synthesize large-scale Case2Code training samples to train LLMs to perform inductive reasoning. Experimental results show that such induction training benefits not only in distribution Case2Code performance but also enhances various coding abilities of trained LLMs, demonstrating the great potential of learning inductive reasoning via synthetic data.
Scaling Laws for Fact Memorization of Large Language Models
Jun 22, 2024Fact knowledge memorization is crucial for Large Language Models (LLM) to generate factual and reliable responses. However, the behaviors of LLM fact memorization remain under-explored. In this paper, we analyze the scaling laws for LLM's fact knowledge and LLMs' behaviors of memorizing different types of facts. We find that LLMs' fact knowledge capacity has a linear and negative exponential law relationship with model size and training epochs, respectively. Estimated by the built scaling law, memorizing the whole Wikidata's facts requires training an LLM with 1000B non-embed parameters for 100 epochs, suggesting that using LLMs to memorize all public facts is almost implausible for a general pre-training setting. Meanwhile, we find that LLMs can generalize on unseen fact knowledge and its scaling law is similar to general pre-training. Additionally, we analyze the compatibility and preference of LLMs' fact memorization. For compatibility, we find LLMs struggle with memorizing redundant facts in a unified way. Only when correlated facts have the same direction and structure, the LLM can compatibly memorize them. This shows the inefficiency of LLM memorization for redundant facts. For preference, the LLM pays more attention to memorizing more frequent and difficult facts, and the subsequent facts can overwrite prior facts' memorization, which significantly hinders low-frequency facts memorization. Our findings reveal the capacity and characteristics of LLMs' fact knowledge learning, which provide directions for LLMs' fact knowledge augmentation.
Inference-Time Decontamination: Reusing Leaked Benchmarks for Large Language Model Evaluation
Jun 20, 2024
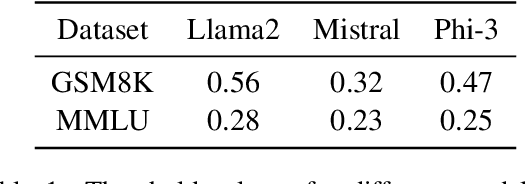


The training process of large language models (LLMs) often involves varying degrees of test data contamination. Although current LLMs are achieving increasingly better performance on various benchmarks, their performance in practical applications does not always match their benchmark results. Leakage of benchmarks can prevent the accurate assessment of LLMs' true performance. However, constructing new benchmarks is costly, labor-intensive and still carries the risk of leakage. Therefore, in this paper, we ask the question, Can we reuse these leaked benchmarks for LLM evaluation? We propose Inference-Time Decontamination (ITD) to address this issue by detecting and rewriting leaked samples without altering their difficulties. ITD can mitigate performance inflation caused by memorizing leaked benchmarks. Our proof-of-concept experiments demonstrate that ITD reduces inflated accuracy by 22.9% on GSM8K and 19.0% on MMLU. On MMLU, using Inference-time Decontamination can lead to a decrease in the results of Phi3 and Mistral by 6.7% and 3.6% respectively. We hope that ITD can provide more truthful evaluation results for large language models.
Unified Active Retrieval for Retrieval Augmented Generation
Jun 18, 2024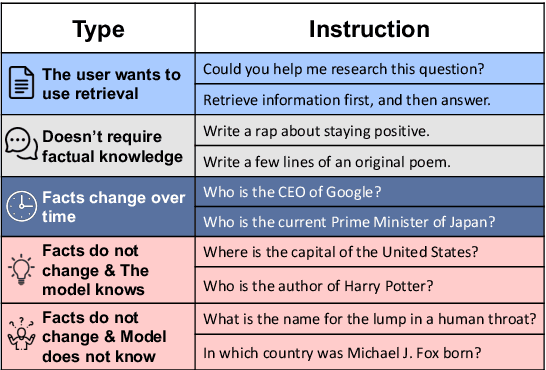

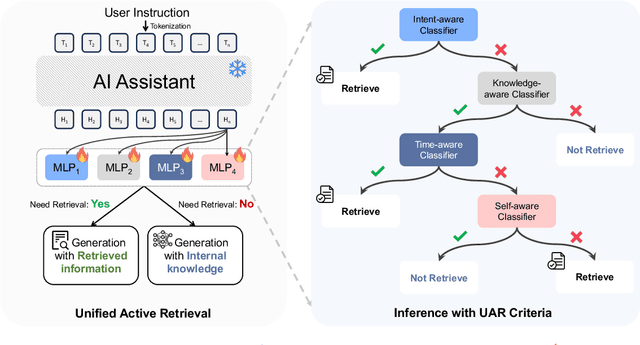
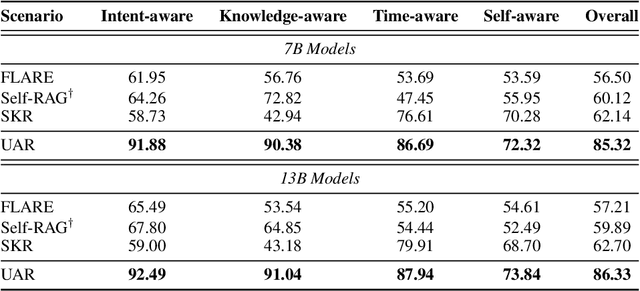
In Retrieval-Augmented Generation (RAG), retrieval is not always helpful and applying it to every instruction is sub-optimal. Therefore, determining whether to retrieve is crucial for RAG, which is usually referred to as Active Retrieval. However, existing active retrieval methods face two challenges: 1. They usually rely on a single criterion, which struggles with handling various types of instructions. 2. They depend on specialized and highly differentiated procedures, and thus combining them makes the RAG system more complicated and leads to higher response latency. To address these challenges, we propose Unified Active Retrieval (UAR). UAR contains four orthogonal criteria and casts them into plug-and-play classification tasks, which achieves multifaceted retrieval timing judgements with negligible extra inference cost. We further introduce the Unified Active Retrieval Criteria (UAR-Criteria), designed to process diverse active retrieval scenarios through a standardized procedure. Experiments on four representative types of user instructions show that UAR significantly outperforms existing work on the retrieval timing judgement and the performance of downstream tasks, which shows the effectiveness of UAR and its helpfulness to downstream tasks.
Aggregation of Reasoning: A Hierarchical Framework for Enhancing Answer Selection in Large Language Models
May 21, 2024

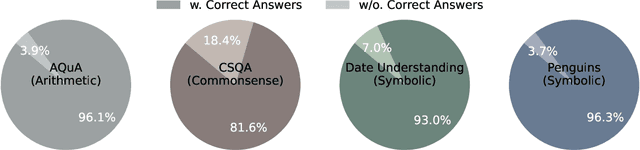
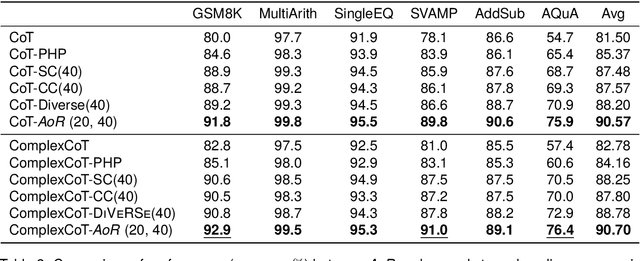
Recent advancements in Chain-of-Thought prompting have facilitated significant breakthroughs for Large Language Models (LLMs) in complex reasoning tasks. Current research enhances the reasoning performance of LLMs by sampling multiple reasoning chains and ensembling based on the answer frequency. However, this approach fails in scenarios where the correct answers are in the minority. We identify this as a primary factor constraining the reasoning capabilities of LLMs, a limitation that cannot be resolved solely based on the predicted answers. To address this shortcoming, we introduce a hierarchical reasoning aggregation framework AoR (Aggregation of Reasoning), which selects answers based on the evaluation of reasoning chains. Additionally, AoR incorporates dynamic sampling, adjusting the number of reasoning chains in accordance with the complexity of the task. Experimental results on a series of complex reasoning tasks show that AoR outperforms prominent ensemble methods. Further analysis reveals that AoR not only adapts various LLMs but also achieves a superior performance ceiling when compared to current methods.
LLatrieval: LLM-Verified Retrieval for Verifiable Generation
Nov 14, 2023


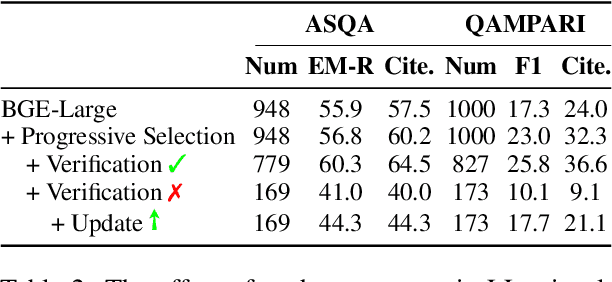
Verifiable generation aims to let the large language model (LLM) generate text with corresponding supporting documents, which enables the user to flexibly verify the answer and makes it more trustworthy. Its evaluation not only measures the correctness of the answer, but also the answer's verifiability, i.e., how well the answer is supported by the corresponding documents. In typical, verifiable generation adopts the retrieval-read pipeline, which is divided into two stages: 1) retrieve relevant documents of the question. 2) according to the documents, generate the corresponding answer. Since the retrieved documents can supplement knowledge for the LLM to generate the answer and serve as evidence, the retrieval stage is essential for the correctness and verifiability of the answer. However, the widely used retrievers become the bottleneck of the entire pipeline and limit the overall performance. They often have fewer parameters than the large language model and have not been proven to scale well to the size of LLMs. Since the LLM passively receives the retrieval result, if the retriever does not correctly find the supporting documents, the LLM can not generate the correct and verifiable answer, which overshadows the LLM's remarkable abilities. In this paper, we propose LLatrieval (Large Language Model Verified Retrieval), where the LLM updates the retrieval result until it verifies that the retrieved documents can support answering the question. Thus, the LLM can iteratively provide feedback to retrieval and facilitate the retrieval result to sufficiently support verifiable generation. Experimental results show that our method significantly outperforms extensive baselines and achieves new state-of-the-art results.