 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptR1: Reinforcement Learning Based Adaptive Interleaved Thinking in Multi-hop Question Answering
May 29, 2026Large Language Models (LLMs) have achieved remarkable performance in complex reasoning tasks through Chain-of-Thought (CoT) prompting. However, this approach often leads to ``over-thinking,'' where models generate unnecessarily long reasoning traces for simple queries and incur avoidable inference cost. While recent work has explored adaptive reasoning, existing methods typically make a single query-level decision about whether to reason. This overlooks the dynamic nature of multi-step tasks, where the need for explicit reasoning varies across intermediate stages. To address this limitation, we introduce AdaptR1, a Reinforcement Learning (RL) based framework for adaptive interleaved thinking in multi-hop Question Answering (QA). Unlike previous approaches that require Supervised Fine-Tuning (SFT) for cold-start initialization, AdaptR1 uses a fully RL-based strategy with a quality-gated efficiency reward to dynamically allocate reasoning budgets at each step. Under the Graph-R1 setting, AdaptR1 reduces average think tokens by 69.71\%, with a 90.35\% reduction on HotpotQA, while maintaining performance comparable to or better than standard baselines. Furthermore, our analysis reveals that overthinking in multi-hop reasoning is not uniformly distributed but occurs predominantly during the initial planning stages, highlighting the effectiveness of step-wise adaptive budget allocation.
Beyond Rating: A Comprehensive Evaluation and Benchmark for AI Reviews
Apr 22, 2026The rapid adoption of Large Language Models (LLMs) has spurred interest in automated peer review; however, progress is currently stifled by benchmarks that treat reviewing primarily as a rating prediction task. We argue that the utility of a review lies in its textual justification--its arguments, questions, and critique--rather than a scalar score. To address this, we introduce Beyond Rating, a holistic evaluation framework that assesses AI reviewers across five dimensions: Content Faithfulness, Argumentative Alignment, Focus Consistency, Question Constructiveness, and AI-Likelihood. Notably, we propose a Max-Recall strategy to accommodate valid expert disagreement and introduce a curated dataset of paper with high-confidence reviews, rigorously filtered to remove procedural noise. Extensive experiments demonstrate that while traditional n-gram metrics fail to reflect human preferences, our proposed text-centric metrics--particularly the recall of weakness arguments--correlate strongly with rating accuracy. These findings establish that aligning AI critique focus with human experts is a prerequisite for reliable automated scoring, offering a robust standard for future research.
The Past Is Not Past: Memory-Enhanced Dynamic Reward Shaping
Apr 13, 2026Despite the success of reinforcement learning for large language models, a common failure mode is reduced sampling diversity, where the policy repeatedly generates similar erroneous behaviors. Classical entropy regularization encourages randomness under the current policy, but does not explicitly discourage recurrent failure patterns across rollouts. We propose MEDS, a Memory-Enhanced Dynamic reward Shaping framework that incorporates historical behavioral signals into reward design. By storing and leveraging intermediate model representations, we capture features of past rollouts and use density-based clustering to identify frequently recurring error patterns. Rollouts assigned to more prevalent error clusters are penalized more heavily, encouraging broader exploration while reducing repeated mistakes. Across five datasets and three base models, MEDS consistently improves average performance over existing baselines, achieving gains of up to 4.13 pass@1 points and 4.37 pass@128 points. Additional analyses using both LLM-based annotations and quantitative diversity metrics show that MEDS increases behavioral diversity during sampling.
AI Can Learn Scientific Taste
Mar 15, 2026Great scientists have strong judgement and foresight, closely tied to what we call scientific taste. Here, we use the term to refer to the capacity to judge and propose research ideas with high potential impact. However, most relative research focuses on improving an AI scientist's executive capability, while enhancing an AI's scientific taste remains underexplored. In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem. For preference modeling, we train Scientific Judge on 700K field- and time-matched pairs of high- vs. low-citation papers to judge ideas. For preference alignment, using Scientific Judge as a reward model, we train a policy model, Scientific Thinker, to propose research ideas with high potential impact. Experiments show Scientific Judge outperforms SOTA LLMs (e.g., GPT-5.2, Gemini 3 Pro) and generalizes to future-year test, unseen fields, and peer-review preference. Furthermore, Scientific Thinker proposes research ideas with higher potential impact than baselines. Our findings show that AI can learn scientific taste, marking a key step toward reaching human-level AI scientists.
AgentLongBench: A Controllable Long Benchmark For Long-Contexts Agents via Environment Rollouts
Jan 29, 2026The evolution of Large Language Models (LLMs) into autonomous agents necessitates the management of extensive, dynamic contexts. Current benchmarks, however, remain largely static, relying on passive retrieval tasks that fail to simulate the complexities of agent-environment interaction, such as non-linear reasoning and iterative feedback. To address this, we introduce \textbf{AgentLongBench}, which evaluates agents through simulated environment rollouts based on Lateral Thinking Puzzles. This framework generates rigorous interaction trajectories across knowledge-intensive and knowledge-free scenarios. Experiments with state-of-the-art models and memory systems (32K to 4M tokens) expose a critical weakness: while adept at static retrieval, agents struggle with the dynamic information synthesis essential for workflows. Our analysis indicates that this degradation is driven by the minimum number of tokens required to resolve a query. This factor explains why the high information density inherent in massive tool responses poses a significantly greater challenge than the memory fragmentation typical of long-turn dialogues.
ABC-Bench: Benchmarking Agentic Backend Coding in Real-World Development
Jan 16, 2026The evolution of Large Language Models (LLMs) into autonomous agents has expanded the scope of AI coding from localized code generation to complex, repository-level, and execution-driven problem solving. However, current benchmarks predominantly evaluate code logic in static contexts, neglecting the dynamic, full-process requirements of real-world engineering, particularly in backend development which demands rigorous environment configuration and service deployment. To address this gap, we introduce ABC-Bench, a benchmark explicitly designed to evaluate agentic backend coding within a realistic, executable workflow. Using a scalable automated pipeline, we curated 224 practical tasks spanning 8 languages and 19 frameworks from open-source repositories. Distinct from previous evaluations, ABC-Bench require the agents to manage the entire development lifecycle from repository exploration to instantiating containerized services and pass the external end-to-end API tests. Our extensive evaluation reveals that even state-of-the-art models struggle to deliver reliable performance on these holistic tasks, highlighting a substantial disparity between current model capabilities and the demands of practical backend engineering. Our code is available at https://github.com/OpenMOSS/ABC-Bench.
Multi-hop Reasoning via Early Knowledge Alignment
Dec 23, 2025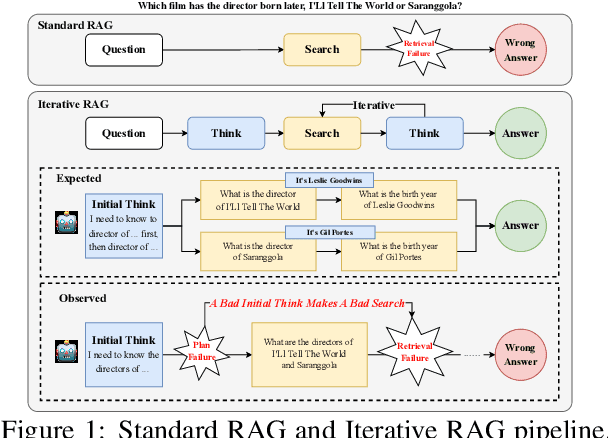

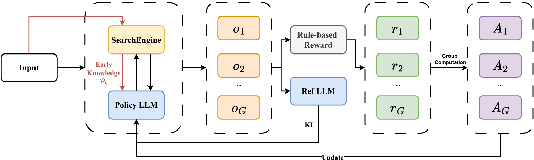
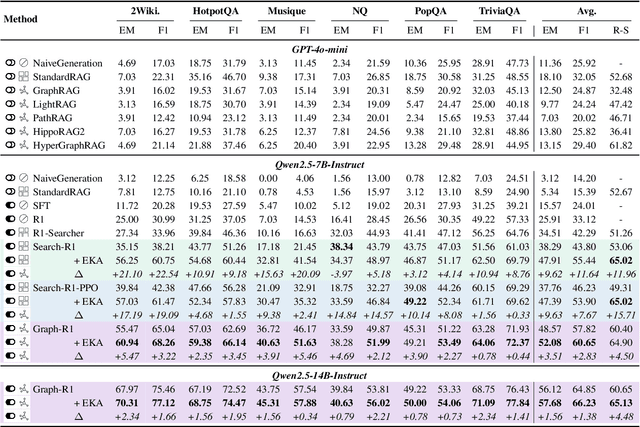
Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm for Large Language Models (LLMs) to address knowledge-intensive queries requiring domain-specific or up-to-date information. To handle complex multi-hop questions that are challenging for single-step retrieval, iterative RAG approaches incorporating reinforcement learning have been proposed. However, existing iterative RAG systems typically plan to decompose questions without leveraging information about the available retrieval corpus, leading to inefficient retrieval and reasoning chains that cascade into suboptimal performance. In this paper, we introduce Early Knowledge Alignment (EKA), a simple but effective module that aligns LLMs with retrieval set before planning in iterative RAG systems with contextually relevant retrieved knowledge. Extensive experiments on six standard RAG datasets demonstrate that by establishing a stronger reasoning foundation, EKA significantly improves retrieval precision, reduces cascading errors, and enhances both performance and efficiency. Our analysis from an entropy perspective demonstrate that incorporating early knowledge reduces unnecessary exploration during the reasoning process, enabling the model to focus more effectively on relevant information subsets. Moreover, EKA proves effective as a versatile, training-free inference strategy that scales seamlessly to large models. Generalization tests across diverse datasets and retrieval corpora confirm the robustness of our approach. Overall, EKA advances the state-of-the-art in iterative RAG systems while illuminating the critical interplay between structured reasoning and efficient exploration in reinforcement learning-augmented frameworks. The code is released at \href{https://github.com/yxzwang/EarlyKnowledgeAlignment}{Github}.
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Nov 06, 2025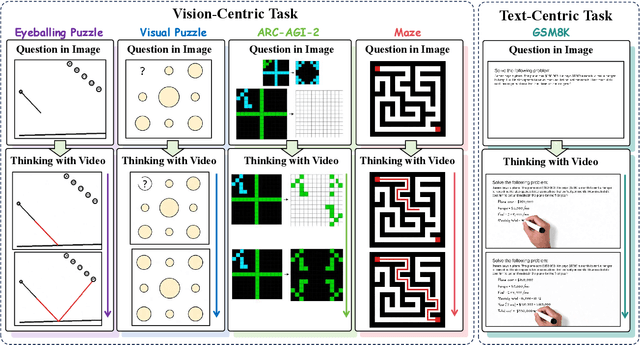
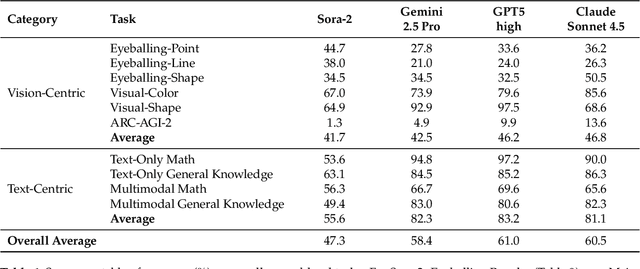
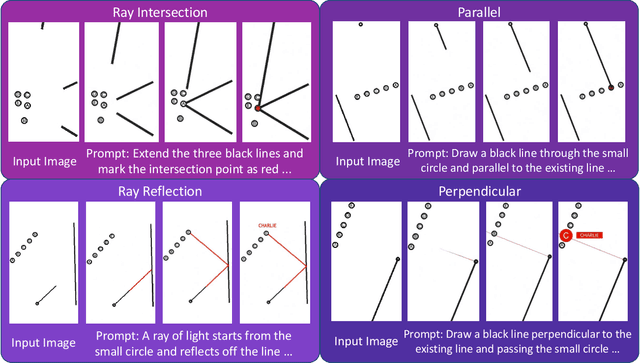
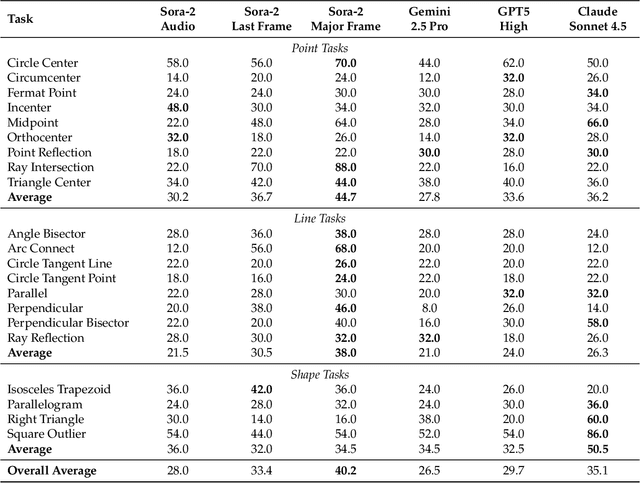
"Thinking with Text" and "Thinking with Images" paradigm significantly improve the reasoning ability of large language models (LLMs) and Vision Language Models (VLMs). However, these paradigms have inherent limitations. (1) Images capture only single moments and fail to represent dynamic processes or continuous changes, and (2) The separation of text and vision as distinct modalities, hindering unified multimodal understanding and generation. To overcome these limitations, we introduce "Thinking with Video", a new paradigm that leverages video generation models, such as Sora-2, to bridge visual and textual reasoning in a unified temporal framework. To support this exploration, we developed the Video Thinking Benchmark (VideoThinkBench). VideoThinkBench encompasses two task categories: (1) vision-centric tasks (e.g., Eyeballing Puzzles), and (2) text-centric tasks (e.g., subsets of GSM8K, MMMU). Our evaluation establishes Sora-2 as a capable reasoner. On vision-centric tasks, Sora-2 is generally comparable to state-of-the-art (SOTA) VLMs, and even surpasses VLMs on several tasks, such as Eyeballing Games. On text-centric tasks, Sora-2 achieves 92% accuracy on MATH, and 75.53% accuracy on MMMU. Furthermore, we systematically analyse the source of these abilities. We also find that self-consistency and in-context learning can improve Sora-2's performance. In summary, our findings demonstrate that the video generation model is the potential unified multimodal understanding and generation model, positions "thinking with video" as a unified multimodal reasoning paradigm.
R3-RAG: Learning Step-by-Step Reasoning and Retrieval for LLMs via Reinforcement Learning
May 26, 2025



Retrieval-Augmented Generation (RAG) integrates external knowledge with Large Language Models (LLMs) to enhance factual correctness and mitigate hallucination. However, dense retrievers often become the bottleneck of RAG systems due to their limited parameters compared to LLMs and their inability to perform step-by-step reasoning. While prompt-based iterative RAG attempts to address these limitations, it is constrained by human-designed workflows. To address these limitations, we propose $\textbf{R3-RAG}$, which uses $\textbf{R}$einforcement learning to make the LLM learn how to $\textbf{R}$eason and $\textbf{R}$etrieve step by step, thus retrieving comprehensive external knowledge and leading to correct answers. R3-RAG is divided into two stages. We first use cold start to make the model learn the manner of iteratively interleaving reasoning and retrieval. Then we use reinforcement learning to further harness its ability to better explore the external retrieval environment. Specifically, we propose two rewards for R3-RAG: 1) answer correctness for outcome reward, which judges whether the trajectory leads to a correct answer; 2) relevance-based document verification for process reward, encouraging the model to retrieve documents that are relevant to the user question, through which we can let the model learn how to iteratively reason and retrieve relevant documents to get the correct answer. Experimental results show that R3-RAG significantly outperforms baselines and can transfer well to different retrievers. We release R3-RAG at https://github.com/Yuan-Li-FNLP/R3-RAG.
FamilyTool: A Multi-hop Personalized Tool Use Benchmark
Apr 09, 2025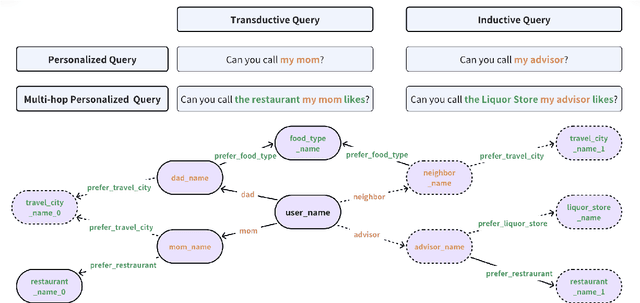

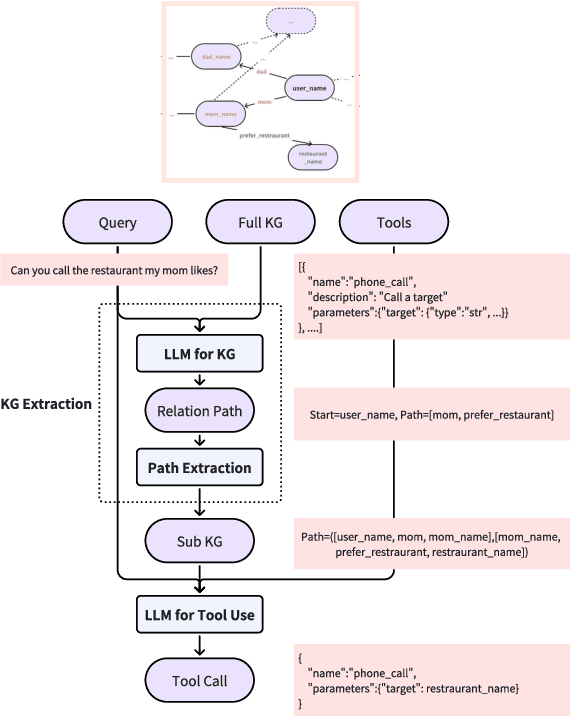

The integration of tool learning with Large Language Models (LLMs) has expanded their capabilities in handling complex tasks by leveraging external tools. However, existing benchmarks for tool learning inadequately address critical real-world personalized scenarios, particularly those requiring multi-hop reasoning and inductive knowledge adaptation in dynamic environments. To bridge this gap, we introduce FamilyTool, a novel benchmark grounded in a family-based knowledge graph (KG) that simulates personalized, multi-hop tool use scenarios. FamilyTool challenges LLMs with queries spanning 1 to 3 relational hops (e.g., inferring familial connections and preferences) and incorporates an inductive KG setting where models must adapt to unseen user preferences and relationships without re-training, a common limitation in prior approaches that compromises generalization. We further propose KGETool: a simple KG-augmented evaluation pipeline to systematically assess LLMs' tool use ability in these settings. Experiments reveal significant performance gaps in state-of-the-art LLMs, with accuracy dropping sharply as hop complexity increases and inductive scenarios exposing severe generalization deficits. These findings underscore the limitations of current LLMs in handling personalized, evolving real-world contexts and highlight the urgent need for advancements in tool-learning frameworks. FamilyTool serves as a critical resource for evaluating and advancing LLM agents' reasoning, adaptability, and scalability in complex, dynamic environments. Code and dataset are available at Github.