 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Synthetic Control Method
Feb 04, 2026The synthetic control method (SCM) estimates causal effects in panel data with a single-treated unit by constructing a counterfactual outcome as a weighted combination of untreated control units that matches the pre-treatment trajectory. In this paper, we introduce the targeted synthetic control (TSC) method, a new two-stage estimator that directly estimates the counterfactual outcome. Specifically, our TSC method (1) yields a targeted debiasing estimator, in the sense that the targeted updating refines the initial weights to produce more stable weights; and (2) ensures that the final counterfactual estimation is a convex combination of observed control outcomes to enable direct interpretation of the synthetic control weights. TSC is flexible and can be instantiated with arbitrary machine learning models. Methodologically, TSC starts from an initial set of synthetic-control weights via a one-dimensional targeted update through the weight-tilting submodel, which calibrates the weights to reduce bias of weights estimation arising from pre-treatment fit. Furthermore, TSC avoids key shortcomings of existing methods (e.g., the augmented SCM), which can produce unbounded counterfactual estimates. Across extensive synthetic and real-world experiments, TSC consistently improves estimation accuracy over state-of-the-art SCM baselines.
On the Spectral Flattening of Quantized Embeddings
Feb 01, 2026Training Large Language Models (LLMs) at ultra-low precision is critically impeded by instability rooted in the conflict between discrete quantization constraints and the intrinsic heavy-tailed spectral nature of linguistic data. By formalizing the connection between Zipfian statistics and random matrix theory, we prove that the power-law decay in the singular value spectra of embeddings is a fundamental requisite for semantic encoding. We derive theoretical bounds showing that uniform quantization introduces a noise floor that disproportionately truncates this spectral tail, which induces spectral flattening and a strictly provable increase in the stable rank of representations. Empirical validation across diverse architectures including GPT-2 and TinyLlama corroborates that this geometric degradation precipitates representational collapse. This work not only quantifies the spectral sensitivity of LLMs but also establishes spectral fidelity as a necessary condition for stable low-bit optimization.
AgentLongBench: A Controllable Long Benchmark For Long-Contexts Agents via Environment Rollouts
Jan 29, 2026The evolution of Large Language Models (LLMs) into autonomous agents necessitates the management of extensive, dynamic contexts. Current benchmarks, however, remain largely static, relying on passive retrieval tasks that fail to simulate the complexities of agent-environment interaction, such as non-linear reasoning and iterative feedback. To address this, we introduce \textbf{AgentLongBench}, which evaluates agents through simulated environment rollouts based on Lateral Thinking Puzzles. This framework generates rigorous interaction trajectories across knowledge-intensive and knowledge-free scenarios. Experiments with state-of-the-art models and memory systems (32K to 4M tokens) expose a critical weakness: while adept at static retrieval, agents struggle with the dynamic information synthesis essential for workflows. Our analysis indicates that this degradation is driven by the minimum number of tokens required to resolve a query. This factor explains why the high information density inherent in massive tool responses poses a significantly greater challenge than the memory fragmentation typical of long-turn dialogues.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
ABC-Bench: Benchmarking Agentic Backend Coding in Real-World Development
Jan 16, 2026The evolution of Large Language Models (LLMs) into autonomous agents has expanded the scope of AI coding from localized code generation to complex, repository-level, and execution-driven problem solving. However, current benchmarks predominantly evaluate code logic in static contexts, neglecting the dynamic, full-process requirements of real-world engineering, particularly in backend development which demands rigorous environment configuration and service deployment. To address this gap, we introduce ABC-Bench, a benchmark explicitly designed to evaluate agentic backend coding within a realistic, executable workflow. Using a scalable automated pipeline, we curated 224 practical tasks spanning 8 languages and 19 frameworks from open-source repositories. Distinct from previous evaluations, ABC-Bench require the agents to manage the entire development lifecycle from repository exploration to instantiating containerized services and pass the external end-to-end API tests. Our extensive evaluation reveals that even state-of-the-art models struggle to deliver reliable performance on these holistic tasks, highlighting a substantial disparity between current model capabilities and the demands of practical backend engineering. Our code is available at https://github.com/OpenMOSS/ABC-Bench.
DAVOS: An Autonomous Vehicle Operating System in the Vehicle Computing Era
Jan 08, 2026Vehicle computing represents a fundamental shift in how autonomous vehicles are designed and deployed, transforming them from isolated transportation systems into mobile computing platforms that support both safety-critical, real-time driving and data-centric services. In this setting, vehicles simultaneously support real-time driving pipelines and a growing set of data-driven applications, placing increased responsibility on the vehicle operating system to coordinate computation, data movement, storage, and access. These demands highlight recurring system considerations related to predictable execution, data and execution protection, efficient handling of high-rate sensor data, and long-term system evolvability, commonly summarized as Safety, Security, Efficiency, and Extensibility (SSEE). Existing vehicle operating systems and runtimes address these concerns in isolation, resulting in fragmented software stacks that limit coordination between autonomy workloads and vehicle data services. This paper presents DAVOS, the Delaware Autonomous Vehicle Operating System, a unified vehicle operating system architecture designed for the vehicle computing context. DAVOS provides a cohesive operating system foundation that supports both real-time autonomy and extensible vehicle computing within a single system framework.
Efficient MoE Inference with Fine-Grained Scheduling of Disaggregated Expert Parallelism
Dec 25, 2025



The mixture-of-experts (MoE) architecture scales model size with sublinear computational increase but suffers from memory-intensive inference due to KV caches and sparse expert activation. Recent disaggregated expert parallelism (DEP) distributes attention and experts to dedicated GPU groups but lacks support for shared experts and efficient task scheduling, limiting performance. We propose FinDEP, a fine-grained task scheduling algorithm for DEP that maximizes task overlap to improve MoE inference throughput. FinDEP introduces three innovations: 1) partitioning computation/communication into smaller tasks for fine-grained pipelining, 2) formulating a scheduling optimization supporting variable granularity and ordering, and 3) developing an efficient solver for this large search space. Experiments on four GPU systems with DeepSeek-V2 and Qwen3-MoE show FinDEP improves throughput by up to 1.61x over prior methods, achieving up to 1.24x speedup on a 32-GPU system.
Multi-hop Reasoning via Early Knowledge Alignment
Dec 23, 2025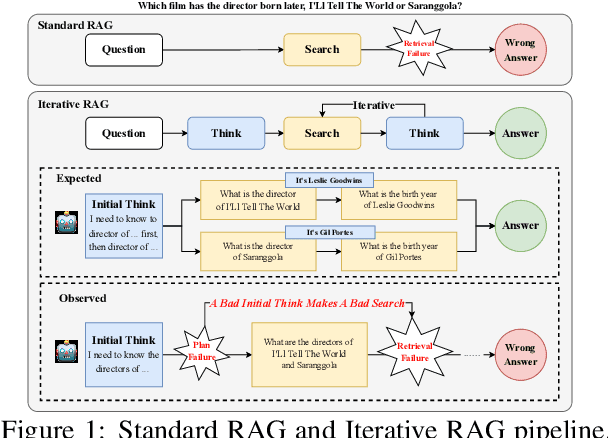

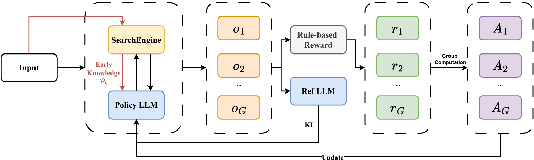
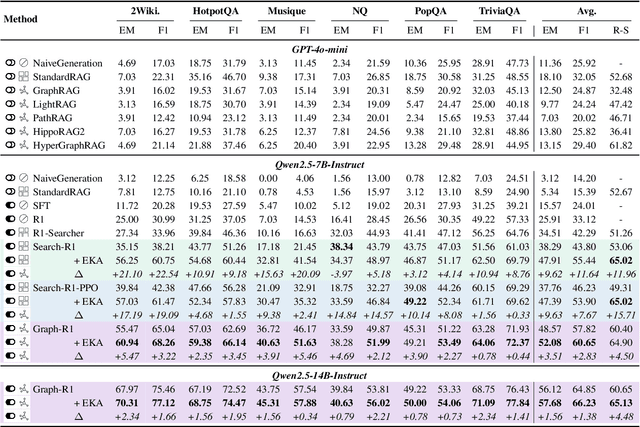
Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm for Large Language Models (LLMs) to address knowledge-intensive queries requiring domain-specific or up-to-date information. To handle complex multi-hop questions that are challenging for single-step retrieval, iterative RAG approaches incorporating reinforcement learning have been proposed. However, existing iterative RAG systems typically plan to decompose questions without leveraging information about the available retrieval corpus, leading to inefficient retrieval and reasoning chains that cascade into suboptimal performance. In this paper, we introduce Early Knowledge Alignment (EKA), a simple but effective module that aligns LLMs with retrieval set before planning in iterative RAG systems with contextually relevant retrieved knowledge. Extensive experiments on six standard RAG datasets demonstrate that by establishing a stronger reasoning foundation, EKA significantly improves retrieval precision, reduces cascading errors, and enhances both performance and efficiency. Our analysis from an entropy perspective demonstrate that incorporating early knowledge reduces unnecessary exploration during the reasoning process, enabling the model to focus more effectively on relevant information subsets. Moreover, EKA proves effective as a versatile, training-free inference strategy that scales seamlessly to large models. Generalization tests across diverse datasets and retrieval corpora confirm the robustness of our approach. Overall, EKA advances the state-of-the-art in iterative RAG systems while illuminating the critical interplay between structured reasoning and efficient exploration in reinforcement learning-augmented frameworks. The code is released at \href{https://github.com/yxzwang/EarlyKnowledgeAlignment}{Github}.
N3D-VLM: Native 3D Grounding Enables Accurate Spatial Reasoning in Vision-Language Models
Dec 18, 2025While current multimodal models can answer questions based on 2D images, they lack intrinsic 3D object perception, limiting their ability to comprehend spatial relationships and depth cues in 3D scenes. In this work, we propose N3D-VLM, a novel unified framework that seamlessly integrates native 3D object perception with 3D-aware visual reasoning, enabling both precise 3D grounding and interpretable spatial understanding. Unlike conventional end-to-end models that directly predict answers from RGB/RGB-D inputs, our approach equips the model with native 3D object perception capabilities, enabling it to directly localize objects in 3D space based on textual descriptions. Building upon accurate 3D object localization, the model further performs explicit reasoning in 3D, achieving more interpretable and structured spatial understanding. To support robust training for these capabilities, we develop a scalable data construction pipeline that leverages depth estimation to lift large-scale 2D annotations into 3D space, significantly increasing the diversity and coverage for 3D object grounding data, yielding over six times larger than the largest existing single-image 3D detection dataset. Moreover, the pipeline generates spatial question-answering datasets that target chain-of-thought (CoT) reasoning in 3D, facilitating joint training for both 3D object localization and 3D spatial reasoning. Experimental results demonstrate that our unified framework not only achieves state-of-the-art performance on 3D grounding tasks, but also consistently surpasses existing methods in 3D spatial reasoning in vision-language model.
MARAG-R1: Beyond Single Retriever via Reinforcement-Learned Multi-Tool Agentic Retrieval
Oct 31, 2025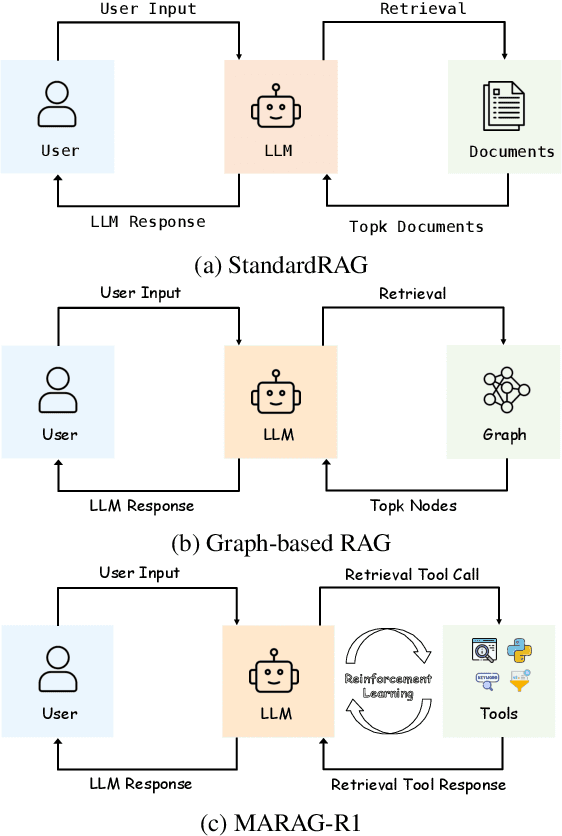
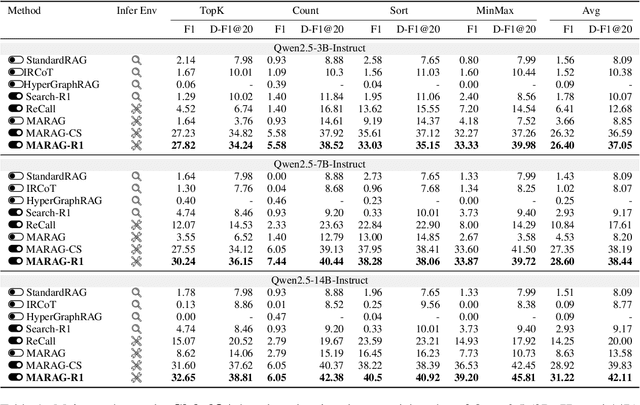
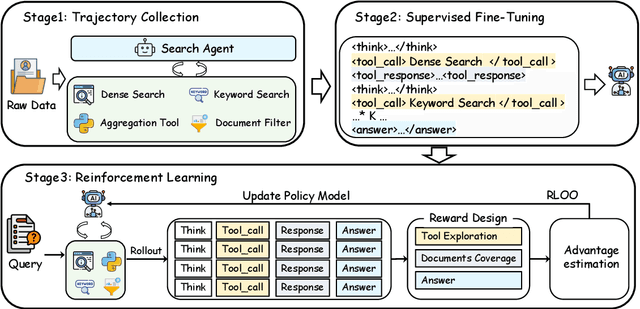
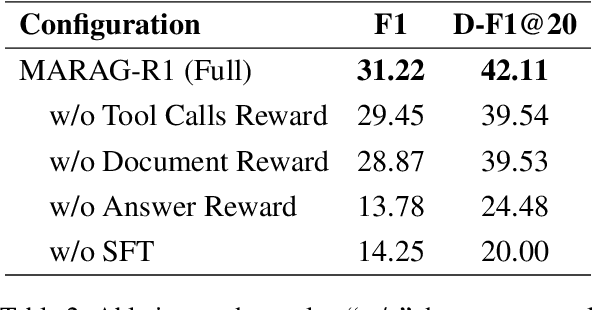
Large Language Models (LLMs) excel at reasoning and generation but are inherently limited by static pretraining data, resulting in factual inaccuracies and weak adaptability to new information. Retrieval-Augmented Generation (RAG) addresses this issue by grounding LLMs in external knowledge; However, the effectiveness of RAG critically depends on whether the model can adequately access relevant information. Existing RAG systems rely on a single retriever with fixed top-k selection, restricting access to a narrow and static subset of the corpus. As a result, this single-retriever paradigm has become the primary bottleneck for comprehensive external information acquisition, especially in tasks requiring corpus-level reasoning. To overcome this limitation, we propose MARAG-R1, a reinforcement-learned multi-tool RAG framework that enables LLMs to dynamically coordinate multiple retrieval mechanisms for broader and more precise information access. MARAG-R1 equips the model with four retrieval tools -- semantic search, keyword search, filtering, and aggregation -- and learns both how and when to use them through a two-stage training process: supervised fine-tuning followed by reinforcement learning. This design allows the model to interleave reasoning and retrieval, progressively gathering sufficient evidence for corpus-level synthesis. Experiments on GlobalQA, HotpotQA, and 2WikiMultiHopQA demonstrate that MARAG-R1 substantially outperforms strong baselines and achieves new state-of-the-art results in corpus-level reasoning tasks.