 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal methods for LLM development and evaluation
May 25, 2026Large language model (LLM) development is currently driven by large-scale empirical iteration over data mixtures, reward models, routing strategies, and evaluation pipelines. Here, we argue that many central questions in LLM development and evaluation are inherently causal: What is the effect of adding a data domain during pretraining? How do annotator preferences change when LLMs generate text in a different style? Should a prompt be routed to a larger or smaller model given inference cost constraints? In general, causal methods are well-suited to such settings where interventions change outcomes but, surprisingly, are underrepresented in LLM development. Our contribution is threefold: (1) We explain how causal methods can help develop modern LLM development and evaluation: LLM development relies heavily on logged data, which are often subject to confounding and distribution shifts; evaluation uses learned but potentially biased judges; and deployment environments are non-stationary. These conditions make purely predictive approaches fragile and create opportunities for principled identification and estimation methods from causal inference. (2) We further map opportunities for causal methods in the entire LLM development pipeline, including pretraining, alignment, routing, agentic workflows, and evaluation. (3) We discuss new research opportunities around leveraging causal methods for LLM development and evaluation. Overall, we argue that causal methods are potentially underutilized for the LLM development and evaluation pipeline, despite the fact that such methods can ensure a reliable and scientifically grounded design.
Adaptive Experimentation for Censored Survival Outcomes
May 18, 2026Adaptive experimentation enables efficient estimation of causal effects, but existing methods are not designed for survival data with censoring, where event times are only partially observed (e.g., overall survival in cancer trials but with dropout). In this paper, we develop a novel framework for adaptive experimentation to estimate causal effects under right censoring. For this, we derive the semiparametric efficiency bound for the average survival effect curve as a function of the treatment allocation policy and thereby obtain a closed-form efficiency-optimal allocation policy. The policy generalizes classical Neyman allocation to survival settings by prioritizing patient strata where both event and censoring dynamics induce high uncertainty. Building on this, we propose the Adaptive Survival Estimator (ASE), an adaptive framework that learns the allocation policy and estimates the average survival effect curve sequentially. Our framework has three main benefits: (i) it accommodates arbitrary machine learning models for nuisance estimation; (ii) it is guided by a closed-form efficiency-optimal allocation policy; and (iii) it admits strong theoretical guarantees, including asymptotic normality via a martingale central limit theorem. We demonstrate our framework across various numerical experiments to show consistent efficiency gains over uniform randomization and censoring-agnostic baselines.
Amortizing Causal Sensitivity Analysis via Prior Data-Fitted Networks
May 11, 2026Causal sensitivity analysis aims to provide bounds for causal effect estimates in the presence of unobserved confounding. However, existing methods for causal sensitivity analysis are per-instance procedures, meaning that changes to the dataset, causal query, sensitivity level, or treatment require new computation. Here, we instead present an in-context learning approach. Specifically, we propose an amortized approach to causal sensitivity analysis based on prior-data fitted networks. A key challenge is that the sensitivity bounds are not directly available when sampling training data. To address this, we develop a general prior-data construction that is applicable across the class of generalized treatment sensitivity models. Our construction involves a Lagrangian scalarization of the objective to generate training labels for the bounds through a tradeoff between causal effect min/max-imization and sensitivity model violation, which avoids model-specific analytical derivations. We further show that, under standard convexity and linearity conditions, our objective recovers the full Pareto frontier of solutions. Empirically, we demonstrate our amortized approach across various datasets, causal queries, and sensitivity levels, where our approach achieves a test-time computation that is orders of magnitude faster than per-instance methods. To the best of our knowledge, ours is the first foundation model for in-context learning for causal sensitivity analysis.
LLM-Driven Treatment Effect Estimation Under Inference Time Text Confounding
Jul 03, 2025Estimating treatment effects is crucial for personalized decision-making in medicine, but this task faces unique challenges in clinical practice. At training time, models for estimating treatment effects are typically trained on well-structured medical datasets that contain detailed patient information. However, at inference time, predictions are often made using textual descriptions (e.g., descriptions with self-reported symptoms), which are incomplete representations of the original patient information. In this work, we make three contributions. (1) We show that the discrepancy between the data available during training time and inference time can lead to biased estimates of treatment effects. We formalize this issue as an inference time text confounding problem, where confounders are fully observed during training time but only partially available through text at inference time. (2) To address this problem, we propose a novel framework for estimating treatment effects that explicitly accounts for inference time text confounding. Our framework leverages large language models together with a custom doubly robust learner to mitigate biases caused by the inference time text confounding. (3) Through a series of experiments, we demonstrate the effectiveness of our framework in real-world applications.
Treatment Effect Estimation for Optimal Decision-Making
May 19, 2025Decision-making across various fields, such as medicine, heavily relies on conditional average treatment effects (CATEs). Practitioners commonly make decisions by checking whether the estimated CATE is positive, even though the decision-making performance of modern CATE estimators is poorly understood from a theoretical perspective. In this paper, we study optimal decision-making based on two-stage CATE estimators (e.g., DR-learner), which are considered state-of-the-art and widely used in practice. We prove that, while such estimators may be optimal for estimating CATE, they can be suboptimal when used for decision-making. Intuitively, this occurs because such estimators prioritize CATE accuracy in regions far away from the decision boundary, which is ultimately irrelevant to decision-making. As a remedy, we propose a novel two-stage learning objective that retargets the CATE to balance CATE estimation error and decision performance. We then propose a neural method that optimizes an adaptively-smoothed approximation of our learning objective. Finally, we confirm the effectiveness of our method both empirically and theoretically. In sum, our work is the first to show how two-stage CATE estimators can be adapted for optimal decision-making.
Orthogonal Representation Learning for Estimating Causal Quantities
Feb 06, 2025Representation learning is widely used for estimating causal quantities (e.g., the conditional average treatment effect) from observational data. While existing representation learning methods have the benefit of allowing for end-to-end learning, they do not have favorable theoretical properties of Neyman-orthogonal learners, such as double robustness and quasi-oracle efficiency. Also, such representation learning methods often employ additional constraints, like balancing, which may even lead to inconsistent estimation. In this paper, we propose a novel class of Neyman-orthogonal learners for causal quantities defined at the representation level, which we call OR-learners. Our OR-learners have several practical advantages: they allow for consistent estimation of causal quantities based on any learned representation, while offering favorable theoretical properties including double robustness and quasi-oracle efficiency. In multiple experiments, we show that, under certain regularity conditions, our OR-learners improve existing representation learning methods and achieve state-of-the-art performance. To the best of our knowledge, our OR-learners are the first work to offer a unified framework of representation learning methods and Neyman-orthogonal learners for causal quantities estimation.
Constructing Confidence Intervals for Average Treatment Effects from Multiple Datasets
Dec 16, 2024



Constructing confidence intervals (CIs) for the average treatment effect (ATE) from patient records is crucial to assess the effectiveness and safety of drugs. However, patient records typically come from different hospitals, thus raising the question of how multiple observational datasets can be effectively combined for this purpose. In our paper, we propose a new method that estimates the ATE from multiple observational datasets and provides valid CIs. Our method makes little assumptions about the observational datasets and is thus widely applicable in medical practice. The key idea of our method is that we leverage prediction-powered inferences and thereby essentially `shrink' the CIs so that we offer more precise uncertainty quantification as compared to na\"ive approaches. We further prove the unbiasedness of our method and the validity of our CIs. We confirm our theoretical results through various numerical experiments. Finally, we provide an extension of our method for constructing CIs from combinations of experimental and observational datasets.
Causal machine learning for predicting treatment outcomes
Oct 11, 2024Causal machine learning (ML) offers flexible, data-driven methods for predicting treatment outcomes including efficacy and toxicity, thereby supporting the assessment and safety of drugs. A key benefit of causal ML is that it allows for estimating individualized treatment effects, so that clinical decision-making can be personalized to individual patient profiles. Causal ML can be used in combination with both clinical trial data and real-world data, such as clinical registries and electronic health records, but caution is needed to avoid biased or incorrect predictions. In this Perspective, we discuss the benefits of causal ML (relative to traditional statistical or ML approaches) and outline the key components and steps. Finally, we provide recommendations for the reliable use of causal ML and effective translation into the clinic.
* Accepted version; not Version of Record
Learning Representations of Instruments for Partial Identification of Treatment Effects
Oct 11, 2024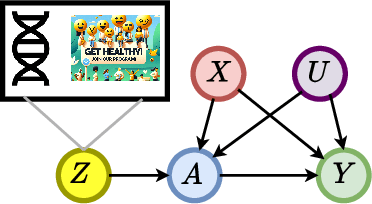
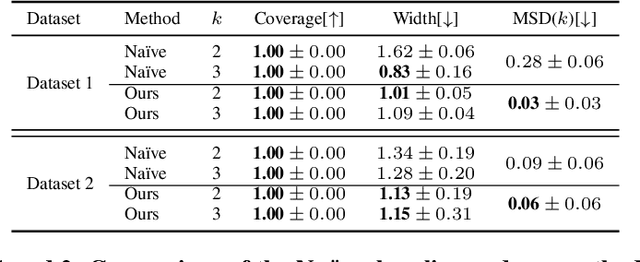
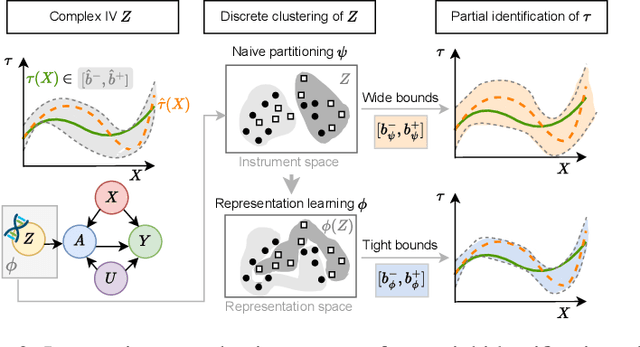
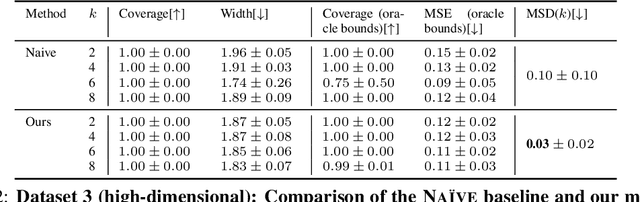
Reliable estimation of treatment effects from observational data is important in many disciplines such as medicine. However, estimation is challenging when unconfoundedness as a standard assumption in the causal inference literature is violated. In this work, we leverage arbitrary (potentially high-dimensional) instruments to estimate bounds on the conditional average treatment effect (CATE). Our contributions are three-fold: (1) We propose a novel approach for partial identification through a mapping of instruments to a discrete representation space so that we yield valid bounds on the CATE. This is crucial for reliable decision-making in real-world applications. (2) We derive a two-step procedure that learns tight bounds using a tailored neural partitioning of the latent instrument space. As a result, we avoid instability issues due to numerical approximations or adversarial training. Furthermore, our procedure aims to reduce the estimation variance in finite-sample settings to yield more reliable estimates. (3) We show theoretically that our procedure obtains valid bounds while reducing estimation variance. We further perform extensive experiments to demonstrate the effectiveness across various settings. Overall, our procedure offers a novel path for practitioners to make use of potentially high-dimensional instruments (e.g., as in Mendelian randomization).
DiffPO: A causal diffusion model for learning distributions of potential outcomes
Oct 11, 2024


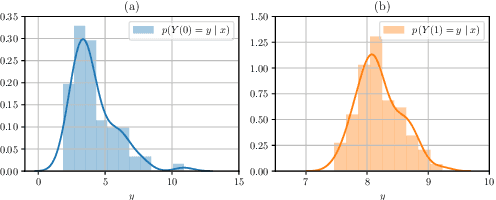
Predicting potential outcomes of interventions from observational data is crucial for decision-making in medicine, but the task is challenging due to the fundamental problem of causal inference. Existing methods are largely limited to point estimates of potential outcomes with no uncertain quantification; thus, the full information about the distributions of potential outcomes is typically ignored. In this paper, we propose a novel causal diffusion model called DiffPO, which is carefully designed for reliable inferences in medicine by learning the distribution of potential outcomes. In our DiffPO, we leverage a tailored conditional denoising diffusion model to learn complex distributions, where we address the selection bias through a novel orthogonal diffusion loss. Another strength of our DiffPO method is that it is highly flexible (e.g., it can also be used to estimate different causal quantities such as CATE). Across a wide range of experiments, we show that our method achieves state-of-the-art performance.