 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-Scores for (In)Correctness Assessment of Generative Model Outputs
Oct 29, 2025While generative models, especially large language models (LLMs), are ubiquitous in today's world, principled mechanisms to assess their (in)correctness are limited. Using the conformal prediction framework, previous works construct sets of LLM responses where the probability of including an incorrect response, or error, is capped at a desired user-defined tolerance level. However, since these methods are based on p-values, they are susceptible to p-hacking, i.e., choosing the tolerance level post-hoc can invalidate the guarantees. We therefore leverage e-values to complement generative model outputs with e-scores as a measure of incorrectness. In addition to achieving the same statistical guarantees as before, e-scores provide users flexibility in adaptively choosing tolerance levels after observing the e-scores themselves, by upper bounding a post-hoc notion of error called size distortion. We experimentally demonstrate their efficacy in assessing LLM outputs for different correctness types: mathematical factuality and property constraints satisfaction.
Deep Learning Through A Telescoping Lens: A Simple Model Provides Empirical Insights On Grokking, Gradient Boosting & Beyond
Oct 31, 2024



Deep learning sometimes appears to work in unexpected ways. In pursuit of a deeper understanding of its surprising behaviors, we investigate the utility of a simple yet accurate model of a trained neural network consisting of a sequence of first-order approximations telescoping out into a single empirically operational tool for practical analysis. Across three case studies, we illustrate how it can be applied to derive new empirical insights on a diverse range of prominent phenomena in the literature -- including double descent, grokking, linear mode connectivity, and the challenges of applying deep learning on tabular data -- highlighting that this model allows us to construct and extract metrics that help predict and understand the a priori unexpected performance of neural networks. We also demonstrate that this model presents a pedagogical formalism allowing us to isolate components of the training process even in complex contemporary settings, providing a lens to reason about the effects of design choices such as architecture & optimization strategy, and reveals surprising parallels between neural network learning and gradient boosting.
Causal machine learning for predicting treatment outcomes
Oct 11, 2024Causal machine learning (ML) offers flexible, data-driven methods for predicting treatment outcomes including efficacy and toxicity, thereby supporting the assessment and safety of drugs. A key benefit of causal ML is that it allows for estimating individualized treatment effects, so that clinical decision-making can be personalized to individual patient profiles. Causal ML can be used in combination with both clinical trial data and real-world data, such as clinical registries and electronic health records, but caution is needed to avoid biased or incorrect predictions. In this Perspective, we discuss the benefits of causal ML (relative to traditional statistical or ML approaches) and outline the key components and steps. Finally, we provide recommendations for the reliable use of causal ML and effective translation into the clinic.
* Accepted version; not Version of Record
Classical Statistical (In-Sample) Intuitions Don't Generalize Well: A Note on Bias-Variance Tradeoffs, Overfitting and Moving from Fixed to Random Designs
Sep 27, 2024



The sudden appearance of modern machine learning (ML) phenomena like double descent and benign overfitting may leave many classically trained statisticians feeling uneasy -- these phenomena appear to go against the very core of statistical intuitions conveyed in any introductory class on learning from data. The historical lack of earlier observation of such phenomena is usually attributed to today's reliance on more complex ML methods, overparameterization, interpolation and/or higher data dimensionality. In this note, we show that there is another reason why we observe behaviors today that appear at odds with intuitions taught in classical statistics textbooks, which is much simpler to understand yet rarely discussed explicitly. In particular, many intuitions originate in fixed design settings, in which in-sample prediction error (under resampling of noisy outcomes) is of interest, while modern ML evaluates its predictions in terms of generalization error, i.e. out-of-sample prediction error in random designs. Here, we highlight that this simple move from fixed to random designs has (perhaps surprisingly) far-reaching consequences on textbook intuitions relating to the bias-variance tradeoff, and comment on the resulting (im)possibility of observing double descent and benign overfitting in fixed versus random designs.
Defining Expertise: Applications to Treatment Effect Estimation
Mar 01, 2024



Decision-makers are often experts of their domain and take actions based on their domain knowledge. Doctors, for instance, may prescribe treatments by predicting the likely outcome of each available treatment. Actions of an expert thus naturally encode part of their domain knowledge, and can help make inferences within the same domain: Knowing doctors try to prescribe the best treatment for their patients, we can tell treatments prescribed more frequently are likely to be more effective. Yet in machine learning, the fact that most decision-makers are experts is often overlooked, and "expertise" is seldom leveraged as an inductive bias. This is especially true for the literature on treatment effect estimation, where often the only assumption made about actions is that of overlap. In this paper, we argue that expertise - particularly the type of expertise the decision-makers of a domain are likely to have - can be informative in designing and selecting methods for treatment effect estimation. We formally define two types of expertise, predictive and prognostic, and demonstrate empirically that: (i) the prominent type of expertise in a domain significantly influences the performance of different methods in treatment effect estimation, and (ii) it is possible to predict the type of expertise present in a dataset, which can provide a quantitative basis for model selection.
Why do Random Forests Work? Understanding Tree Ensembles as Self-Regularizing Adaptive Smoothers
Feb 02, 2024Despite their remarkable effectiveness and broad application, the drivers of success underlying ensembles of trees are still not fully understood. In this paper, we highlight how interpreting tree ensembles as adaptive and self-regularizing smoothers can provide new intuition and deeper insight to this topic. We use this perspective to show that, when studied as smoothers, randomized tree ensembles not only make predictions that are quantifiably more smooth than the predictions of the individual trees they consist of, but also further regulate their smoothness at test-time based on the dissimilarity between testing and training inputs. First, we use this insight to revisit, refine and reconcile two recent explanations of forest success by providing a new way of quantifying the conjectured behaviors of tree ensembles objectively by measuring the effective degree of smoothing they imply. Then, we move beyond existing explanations for the mechanisms by which tree ensembles improve upon individual trees and challenge the popular wisdom that the superior performance of forests should be understood as a consequence of variance reduction alone. We argue that the current high-level dichotomy into bias- and variance-reduction prevalent in statistics is insufficient to understand tree ensembles -- because the prevailing definition of bias does not capture differences in the expressivity of the hypothesis classes formed by trees and forests. Instead, we show that forests can improve upon trees by three distinct mechanisms that are usually implicitly entangled. In particular, we demonstrate that the smoothing effect of ensembling can reduce variance in predictions due to noise in outcome generation, reduce variability in the quality of the learned function given fixed input data and reduce potential bias in learnable functions by enriching the available hypothesis space.
A Neural Framework for Generalized Causal Sensitivity Analysis
Nov 27, 2023



Unobserved confounding is common in many applications, making causal inference from observational data challenging. As a remedy, causal sensitivity analysis is an important tool to draw causal conclusions under unobserved confounding with mathematical guarantees. In this paper, we propose NeuralCSA, a neural framework for generalized causal sensitivity analysis. Unlike previous work, our framework is compatible with (i) a large class of sensitivity models, including the marginal sensitivity model, f-sensitivity models, and Rosenbaum's sensitivity model; (ii) different treatment types (i.e., binary and continuous); and (iii) different causal queries, including (conditional) average treatment effects and simultaneous effects on multiple outcomes. The generality of \frameworkname is achieved by learning a latent distribution shift that corresponds to a treatment intervention using two conditional normalizing flows. We provide theoretical guarantees that NeuralCSA is able to infer valid bounds on the causal query of interest and also demonstrate this empirically using both simulated and real-world data.
A U-turn on Double Descent: Rethinking Parameter Counting in Statistical Learning
Oct 29, 2023



Conventional statistical wisdom established a well-understood relationship between model complexity and prediction error, typically presented as a U-shaped curve reflecting a transition between under- and overfitting regimes. However, motivated by the success of overparametrized neural networks, recent influential work has suggested this theory to be generally incomplete, introducing an additional regime that exhibits a second descent in test error as the parameter count p grows past sample size n - a phenomenon dubbed double descent. While most attention has naturally been given to the deep-learning setting, double descent was shown to emerge more generally across non-neural models: known cases include linear regression, trees, and boosting. In this work, we take a closer look at evidence surrounding these more classical statistical machine learning methods and challenge the claim that observed cases of double descent truly extend the limits of a traditional U-shaped complexity-generalization curve therein. We show that once careful consideration is given to what is being plotted on the x-axes of their double descent plots, it becomes apparent that there are implicitly multiple complexity axes along which the parameter count grows. We demonstrate that the second descent appears exactly (and only) when and where the transition between these underlying axes occurs, and that its location is thus not inherently tied to the interpolation threshold p=n. We then gain further insight by adopting a classical nonparametric statistics perspective. We interpret the investigated methods as smoothers and propose a generalized measure for the effective number of parameters they use on unseen examples, using which we find that their apparent double descent curves indeed fold back into more traditional convex shapes - providing a resolution to tensions between double descent and statistical intuition.
Accounting For Informative Sampling When Learning to Forecast Treatment Outcomes Over Time
Jun 07, 2023
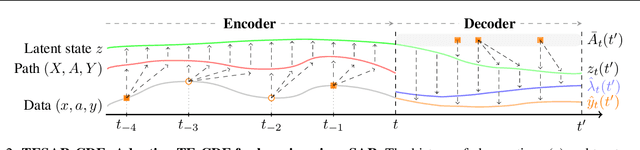

Machine learning (ML) holds great potential for accurately forecasting treatment outcomes over time, which could ultimately enable the adoption of more individualized treatment strategies in many practical applications. However, a significant challenge that has been largely overlooked by the ML literature on this topic is the presence of informative sampling in observational data. When instances are observed irregularly over time, sampling times are typically not random, but rather informative -- depending on the instance's characteristics, past outcomes, and administered treatments. In this work, we formalize informative sampling as a covariate shift problem and show that it can prohibit accurate estimation of treatment outcomes if not properly accounted for. To overcome this challenge, we present a general framework for learning treatment outcomes in the presence of informative sampling using inverse intensity-weighting, and propose a novel method, TESAR-CDE, that instantiates this framework using Neural CDEs. Using a simulation environment based on a clinical use case, we demonstrate the effectiveness of our approach in learning under informative sampling.
Understanding the Impact of Competing Events on Heterogeneous Treatment Effect Estimation from Time-to-Event Data
Feb 23, 2023


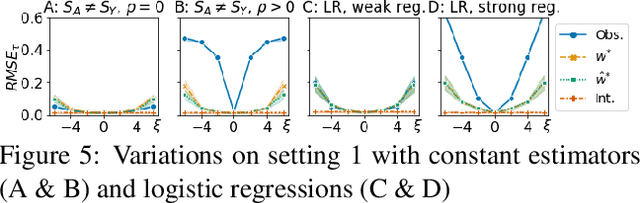
We study the problem of inferring heterogeneous treatment effects (HTEs) from time-to-event data in the presence of competing events. Albeit its great practical relevance, this problem has received little attention compared to its counterparts studying HTE estimation without time-to-event data or competing events. We take an outcome modeling approach to estimating HTEs, and consider how and when existing prediction models for time-to-event data can be used as plug-in estimators for potential outcomes. We then investigate whether competing events present new challenges for HTE estimation -- in addition to the standard confounding problem --, and find that, because there are multiple definitions of causal effects in this setting -- namely total, direct and separable effects --, competing events can act as an additional source of covariate shift depending on the desired treatment effect interpretation and associated estimand. We theoretically analyze and empirically illustrate when and how these challenges play a role when using generic machine learning prediction models for the estimation of HTEs.