 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Treatment Effects in Networks using Domain Adversarial Training
Oct 24, 2025Estimating heterogeneous treatment effects in network settings is complicated by interference, meaning that the outcome of an instance can be influenced by the treatment status of others. Existing causal machine learning approaches usually assume a known exposure mapping that summarizes how the outcome of a given instance is influenced by others' treatment, a simplification that is often unrealistic. Furthermore, the interaction between homophily -- the tendency of similar instances to connect -- and the treatment assignment mechanism can induce a network-level covariate shift that may lead to inaccurate treatment effect estimates, a phenomenon that has not yet been explicitly studied. To address these challenges, we propose HINet, a novel method that integrates graph neural networks with domain adversarial training. This combination allows estimating treatment effects under unknown exposure mappings while mitigating the impact of (network-level) covariate shift. An extensive empirical evaluation on synthetic and semi-synthetic network datasets demonstrates the effectiveness of our approach.
GARG-AML against Smurfing: A Scalable and Interpretable Graph-Based Framework for Anti-Money Laundering
Jun 04, 2025Money laundering poses a significant challenge as it is estimated to account for 2%-5% of the global GDP. This has compelled regulators to impose stringent controls on financial institutions. One prominent laundering method for evading these controls, called smurfing, involves breaking up large transactions into smaller amounts. Given the complexity of smurfing schemes, which involve multiple transactions distributed among diverse parties, network analytics has become an important anti-money laundering tool. However, recent advances have focused predominantly on black-box network embedding methods, which has hindered their adoption in businesses. In this paper, we introduce GARG-AML, a novel graph-based method that quantifies smurfing risk through a single interpretable metric derived from the structure of the second-order transaction network of each individual node in the network. Unlike traditional methods, GARG-AML strikes an effective balance among computational efficiency, detection power and transparency, which enables its integration into existing AML workflows. To enhance its capabilities, we combine the GARG-AML score calculation with different tree-based methods and also incorporate the scores of the node's neighbours. An experimental evaluation on large-scale synthetic and open-source networks demonstrate that the GARG-AML outperforms the current state-of-the-art smurfing detection methods. By leveraging only the adjacency matrix of the second-order neighbourhood and basic network features, this work highlights the potential of fundamental network properties towards advancing fraud detection.
Decision-centric fairness: Evaluation and optimization for resource allocation problems
Apr 29, 2025



Data-driven decision support tools play an increasingly central role in decision-making across various domains. In this work, we focus on binary classification models for predicting positive-outcome scores and deciding on resource allocation, e.g., credit scores for granting loans or churn propensity scores for targeting customers with a retention campaign. Such models may exhibit discriminatory behavior toward specific demographic groups through their predicted scores, potentially leading to unfair resource allocation. We focus on demographic parity as a fairness metric to compare the proportions of instances that are selected based on their positive outcome scores across groups. In this work, we propose a decision-centric fairness methodology that induces fairness only within the decision-making region -- the range of relevant decision thresholds on the score that may be used to decide on resource allocation -- as an alternative to a global fairness approach that seeks to enforce parity across the entire score distribution. By restricting the induction of fairness to the decision-making region, the proposed decision-centric approach avoids imposing overly restrictive constraints on the model, which may unnecessarily degrade the quality of the predicted scores. We empirically compare our approach to a global fairness approach on multiple (semi-synthetic) datasets to identify scenarios in which focusing on fairness where it truly matters, i.e., decision-centric fairness, proves beneficial.
Beware of "Explanations" of AI
Apr 09, 2025Understanding the decisions made and actions taken by increasingly complex AI system remains a key challenge. This has led to an expanding field of research in explainable artificial intelligence (XAI), highlighting the potential of explanations to enhance trust, support adoption, and meet regulatory standards. However, the question of what constitutes a "good" explanation is dependent on the goals, stakeholders, and context. At a high level, psychological insights such as the concept of mental model alignment can offer guidance, but success in practice is challenging due to social and technical factors. As a result of this ill-defined nature of the problem, explanations can be of poor quality (e.g. unfaithful, irrelevant, or incoherent), potentially leading to substantial risks. Instead of fostering trust and safety, poorly designed explanations can actually cause harm, including wrong decisions, privacy violations, manipulation, and even reduced AI adoption. Therefore, we caution stakeholders to beware of explanations of AI: while they can be vital, they are not automatically a remedy for transparency or responsible AI adoption, and their misuse or limitations can exacerbate harm. Attention to these caveats can help guide future research to improve the quality and impact of AI explanations.
Advances in Continual Graph Learning for Anti-Money Laundering Systems: A Comprehensive Review
Mar 31, 2025Financial institutions are required by regulation to report suspicious financial transactions related to money laundering. Therefore, they need to constantly monitor vast amounts of incoming and outgoing transactions. A particular challenge in detecting money laundering is that money launderers continuously adapt their tactics to evade detection. Hence, detection methods need constant fine-tuning. Traditional machine learning models suffer from catastrophic forgetting when fine-tuning the model on new data, thereby limiting their effectiveness in dynamic environments. Continual learning methods may address this issue and enhance current anti-money laundering (AML) practices, by allowing models to incorporate new information while retaining prior knowledge. Research on continual graph learning for AML, however, is still scarce. In this review, we critically evaluate state-of-the-art continual graph learning approaches for AML applications. We categorise methods into replay-based, regularization-based, and architecture-based strategies within the graph neural network (GNN) framework, and we provide in-depth experimental evaluations on both synthetic and real-world AML data sets that showcase the effect of the different hyperparameters. Our analysis demonstrates that continual learning improves model adaptability and robustness in the face of extreme class imbalances and evolving fraud patterns. Finally, we outline key challenges and propose directions for future research.
Uplift modeling with continuous treatments: A predict-then-optimize approach
Dec 12, 2024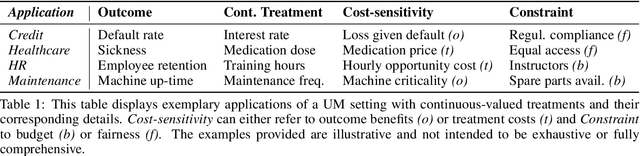

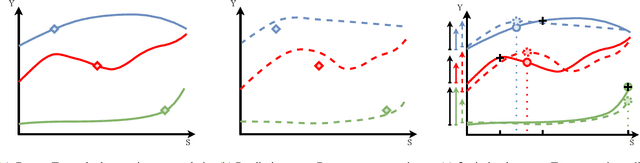
The goal of uplift modeling is to recommend actions that optimize specific outcomes by determining which entities should receive treatment. One common approach involves two steps: first, an inference step that estimates conditional average treatment effects (CATEs), and second, an optimization step that ranks entities based on their CATE values and assigns treatment to the top k within a given budget. While uplift modeling typically focuses on binary treatments, many real-world applications are characterized by continuous-valued treatments, i.e., a treatment dose. This paper presents a predict-then-optimize framework to allow for continuous treatments in uplift modeling. First, in the inference step, conditional average dose responses (CADRs) are estimated from data using causal machine learning techniques. Second, in the optimization step, we frame the assignment task of continuous treatments as a dose-allocation problem and solve it using integer linear programming (ILP). This approach allows decision-makers to efficiently and effectively allocate treatment doses while balancing resource availability, with the possibility of adding extra constraints like fairness considerations or adapting the objective function to take into account instance-dependent costs and benefits to maximize utility. The experiments compare several CADR estimators and illustrate the trade-offs between policy value and fairness, as well as the impact of an adapted objective function. This showcases the framework's advantages and flexibility across diverse applications in healthcare, lending, and human resource management. All code is available on github.com/SimonDeVos/UMCT.
Using dynamic loss weighting to boost improvements in forecast stability
Sep 26, 2024



Rolling origin forecast instability refers to variability in forecasts for a specific period induced by updating the forecast when new data points become available. Recently, an extension to the N-BEATS model for univariate time series point forecasting was proposed to include forecast stability as an additional optimization objective, next to accuracy. It was shown that more stable forecasts can be obtained without harming accuracy by minimizing a composite loss function that contains both a forecast error and a forecast instability component, with a static hyperparameter to control the impact of stability. In this paper, we empirically investigate whether further improvements in stability can be obtained without compromising accuracy by applying dynamic loss weighting algorithms, which change the loss weights during training. We show that some existing dynamic loss weighting methods achieve this objective. However, our proposed extension to the Random Weighting approach -- Task-Aware Random Weighting -- shows the best performance.
Sources of Gain: Decomposing Performance in Conditional Average Dose Response Estimation
Jun 12, 2024



Estimating conditional average dose responses (CADR) is an important but challenging problem. Estimators must correctly model the potentially complex relationships between covariates, interventions, doses, and outcomes. In recent years, the machine learning community has shown great interest in developing tailored CADR estimators that target specific challenges. Their performance is typically evaluated against other methods on (semi-) synthetic benchmark datasets. Our paper analyses this practice and shows that using popular benchmark datasets without further analysis is insufficient to judge model performance. Established benchmarks entail multiple challenges, whose impacts must be disentangled. Therefore, we propose a novel decomposition scheme that allows the evaluation of the impact of five distinct components contributing to CADR estimator performance. We apply this scheme to eight popular CADR estimators on four widely-used benchmark datasets, running nearly 1,500 individual experiments. Our results reveal that most established benchmarks are challenging for reasons different from their creators' claims. Notably, confounding, the key challenge tackled by most estimators, is not an issue in any of the considered datasets. We discuss the major implications of our findings and present directions for future research.
Network Analytics for Anti-Money Laundering -- A Systematic Literature Review and Experimental Evaluation
May 31, 2024Money laundering presents a pervasive challenge, burdening society by financing illegal activities. To more effectively combat and detect money laundering, the use of network information is increasingly being explored, exploiting that money laundering necessarily involves interconnected parties. This has lead to a surge in literature on network analytics (NA) for anti-money laundering (AML). The literature, however, is fragmented and a comprehensive overview of existing work is missing. This results in limited understanding of the methods that may be applied and their comparative detection power. Therefore, this paper presents an extensive and systematic review of the literature. We identify and analyse 97 papers in the Web of Science and Scopus databases, resulting in a taxonomy of approaches following the fraud analytics framework of Bockel-Rickermann et al.. Moreover, this paper presents a comprehensive experimental framework to evaluate and compare the performance of prominent NA methods in a uniform setup. The framework is applied on the publicly available Elliptic data set and implements manual feature engineering, random walk-based methods, and deep learning GNNs. We conclude from the results that network analytics increases the predictive power of the AML model with graph neural networks giving the best results. An open source implementation of the experimental framework is provided to facilitate researchers and practitioners to extend upon these results and experiment on proprietary data. As such, we aim to promote a standardised approach towards the analysis and evaluation of network analytics for AML.
Metalearners for Ranking Treatment Effects
May 03, 2024
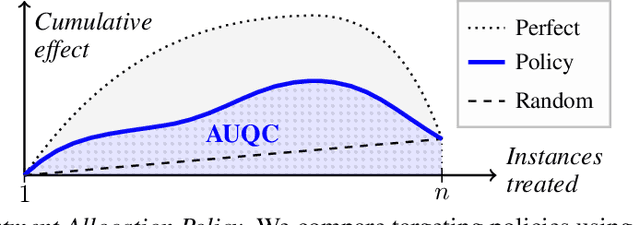

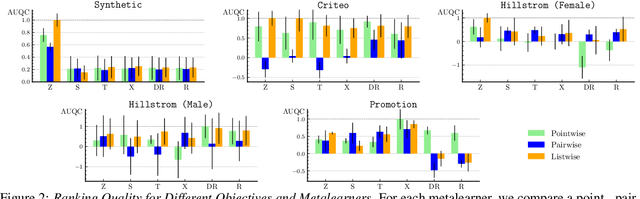
Efficiently allocating treatments with a budget constraint constitutes an important challenge across various domains. In marketing, for example, the use of promotions to target potential customers and boost conversions is limited by the available budget. While much research focuses on estimating causal effects, there is relatively limited work on learning to allocate treatments while considering the operational context. Existing methods for uplift modeling or causal inference primarily estimate treatment effects, without considering how this relates to a profit maximizing allocation policy that respects budget constraints. The potential downside of using these methods is that the resulting predictive model is not aligned with the operational context. Therefore, prediction errors are propagated to the optimization of the budget allocation problem, subsequently leading to a suboptimal allocation policy. We propose an alternative approach based on learning to rank. Our proposed methodology directly learns an allocation policy by prioritizing instances in terms of their incremental profit. We propose an efficient sampling procedure for the optimization of the ranking model to scale our methodology to large-scale data sets. Theoretically, we show how learning to rank can maximize the area under a policy's incremental profit curve. Empirically, we validate our methodology and show its effectiveness in practice through a series of experiments on both synthetic and real-world data.