 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-centric fairness: Evaluation and optimization for resource allocation problems
Apr 29, 2025



Data-driven decision support tools play an increasingly central role in decision-making across various domains. In this work, we focus on binary classification models for predicting positive-outcome scores and deciding on resource allocation, e.g., credit scores for granting loans or churn propensity scores for targeting customers with a retention campaign. Such models may exhibit discriminatory behavior toward specific demographic groups through their predicted scores, potentially leading to unfair resource allocation. We focus on demographic parity as a fairness metric to compare the proportions of instances that are selected based on their positive outcome scores across groups. In this work, we propose a decision-centric fairness methodology that induces fairness only within the decision-making region -- the range of relevant decision thresholds on the score that may be used to decide on resource allocation -- as an alternative to a global fairness approach that seeks to enforce parity across the entire score distribution. By restricting the induction of fairness to the decision-making region, the proposed decision-centric approach avoids imposing overly restrictive constraints on the model, which may unnecessarily degrade the quality of the predicted scores. We empirically compare our approach to a global fairness approach on multiple (semi-synthetic) datasets to identify scenarios in which focusing on fairness where it truly matters, i.e., decision-centric fairness, proves beneficial.
Uplift modeling with continuous treatments: A predict-then-optimize approach
Dec 12, 2024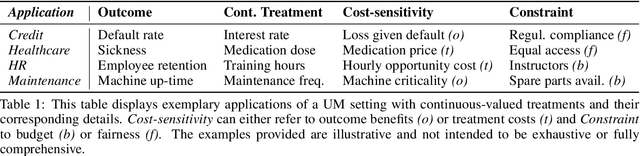
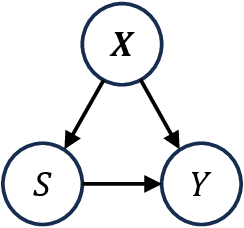

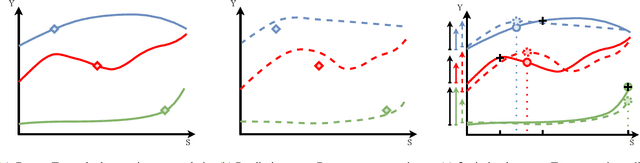
The goal of uplift modeling is to recommend actions that optimize specific outcomes by determining which entities should receive treatment. One common approach involves two steps: first, an inference step that estimates conditional average treatment effects (CATEs), and second, an optimization step that ranks entities based on their CATE values and assigns treatment to the top k within a given budget. While uplift modeling typically focuses on binary treatments, many real-world applications are characterized by continuous-valued treatments, i.e., a treatment dose. This paper presents a predict-then-optimize framework to allow for continuous treatments in uplift modeling. First, in the inference step, conditional average dose responses (CADRs) are estimated from data using causal machine learning techniques. Second, in the optimization step, we frame the assignment task of continuous treatments as a dose-allocation problem and solve it using integer linear programming (ILP). This approach allows decision-makers to efficiently and effectively allocate treatment doses while balancing resource availability, with the possibility of adding extra constraints like fairness considerations or adapting the objective function to take into account instance-dependent costs and benefits to maximize utility. The experiments compare several CADR estimators and illustrate the trade-offs between policy value and fairness, as well as the impact of an adapted objective function. This showcases the framework's advantages and flexibility across diverse applications in healthcare, lending, and human resource management. All code is available on github.com/SimonDeVos/UMCT.
Achieving Group Fairness through Independence in Predictive Process Monitoring
Dec 06, 2024Predictive process monitoring focuses on forecasting future states of ongoing process executions, such as predicting the outcome of a particular case. In recent years, the application of machine learning models in this domain has garnered significant scientific attention. When using historical execution data, which may contain biases or exhibit unfair behavior, these biases may be encoded into the trained models. Consequently, when such models are deployed to make decisions or guide interventions for new cases, they risk perpetuating this unwanted behavior. This work addresses group fairness in predictive process monitoring by investigating independence, i.e. ensuring predictions are unaffected by sensitive group membership. We explore independence through metrics for demographic parity such as $\Delta$DP, as well as recently introduced, threshold-independent distribution-based alternatives. Additionally, we propose a composite loss functions existing of binary cross-entropy and a distribution-based loss (Wasserstein) to train models that balance predictive performance and fairness, and allow for customizable trade-offs. The effectiveness of both the fairness metrics and the composite loss functions is validated through a controlled experimental setup.
Using dynamic loss weighting to boost improvements in forecast stability
Sep 26, 2024



Rolling origin forecast instability refers to variability in forecasts for a specific period induced by updating the forecast when new data points become available. Recently, an extension to the N-BEATS model for univariate time series point forecasting was proposed to include forecast stability as an additional optimization objective, next to accuracy. It was shown that more stable forecasts can be obtained without harming accuracy by minimizing a composite loss function that contains both a forecast error and a forecast instability component, with a static hyperparameter to control the impact of stability. In this paper, we empirically investigate whether further improvements in stability can be obtained without compromising accuracy by applying dynamic loss weighting algorithms, which change the loss weights during training. We show that some existing dynamic loss weighting methods achieve this objective. However, our proposed extension to the Random Weighting approach -- Task-Aware Random Weighting -- shows the best performance.