 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating data drift to perform survival analysis on credit risk
Jan 28, 2026Survival analysis has become a standard approach for modelling time to default by time-varying covariates in credit risk. Unlike most existing methods that implicitly assume a stationary data-generating process, in practise, mortgage portfolios are exposed to various forms of data drift caused by changing borrower behaviour, macroeconomic conditions, policy regimes and so on. This study investigates the impact of data drift on survival-based credit risk models and proposes a dynamic joint modelling framework to improve robustness under non-stationary environments. The proposed model integrates a longitudinal behavioural marker derived from balance dynamics with a discrete-time hazard formulation, combined with landmark one-hot encoding and isotonic calibration. Three types of data drift (sudden, incremental and recurring) are simulated and analysed on mortgage loan datasets from Freddie Mac. Experiments and corresponding evidence show that the proposed landmark-based joint model consistently outperforms classical survival models, tree-based drift-adaptive learners and gradient boosting methods in terms of discrimination and calibration across all drift scenarios, which confirms the superiority of our model design.
Variational Quantum Circuit-Based Reinforcement Learning for Dynamic Portfolio Optimization
Jan 20, 2026This paper presents a Quantum Reinforcement Learning (QRL) solution to the dynamic portfolio optimization problem based on Variational Quantum Circuits. The implemented QRL approaches are quantum analogues of the classical neural-network-based Deep Deterministic Policy Gradient and Deep Q-Network algorithms. Through an empirical evaluation on real-world financial data, we show that our quantum agents achieve risk-adjusted performance comparable to, and in some cases exceeding, that of classical Deep RL models with several orders of magnitude more parameters. In addition to improved parameter efficiency, quantum agents exhibit reduced variability across market regimes, indicating robust behaviour under changing conditions. However, while quantum circuit execution is inherently fast at the hardware level, practical deployment on cloud-based quantum systems introduces substantial latency, making end-to-end runtime currently dominated by infrastructural overhead and limiting practical applicability. Taken together, our results suggest that QRL is theoretically competitive with state-of-the-art classical reinforcement learning and may become practically advantageous as deployment overheads diminish. This positions QRL as a promising paradigm for dynamic decision-making in complex, high-dimensional, and non-stationary environments such as financial markets. The complete codebase is released as open source at: https://github.com/VincentGurgul/qrl-dpo-public
Uplift modeling with continuous treatments: A predict-then-optimize approach
Dec 12, 2024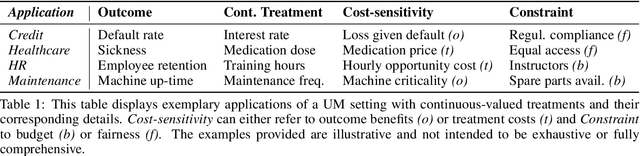
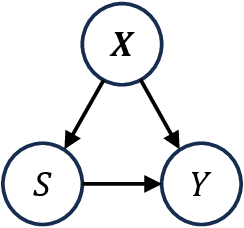

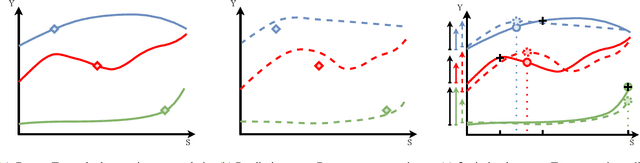
The goal of uplift modeling is to recommend actions that optimize specific outcomes by determining which entities should receive treatment. One common approach involves two steps: first, an inference step that estimates conditional average treatment effects (CATEs), and second, an optimization step that ranks entities based on their CATE values and assigns treatment to the top k within a given budget. While uplift modeling typically focuses on binary treatments, many real-world applications are characterized by continuous-valued treatments, i.e., a treatment dose. This paper presents a predict-then-optimize framework to allow for continuous treatments in uplift modeling. First, in the inference step, conditional average dose responses (CADRs) are estimated from data using causal machine learning techniques. Second, in the optimization step, we frame the assignment task of continuous treatments as a dose-allocation problem and solve it using integer linear programming (ILP). This approach allows decision-makers to efficiently and effectively allocate treatment doses while balancing resource availability, with the possibility of adding extra constraints like fairness considerations or adapting the objective function to take into account instance-dependent costs and benefits to maximize utility. The experiments compare several CADR estimators and illustrate the trade-offs between policy value and fairness, as well as the impact of an adapted objective function. This showcases the framework's advantages and flexibility across diverse applications in healthcare, lending, and human resource management. All code is available on github.com/SimonDeVos/UMCT.
Leveraging AI and NLP for Bank Marketing: A Systematic Review and Gap Analysis
Nov 17, 2024This paper explores the growing impact of AI and NLP in bank marketing, highlighting their evolving roles in enhancing marketing strategies, improving customer engagement, and creating value within this sector. While AI and NLP have been widely studied in general marketing, there is a notable gap in understanding their specific applications and potential within the banking sector. This research addresses this specific gap by providing a systematic review and strategic analysis of AI and NLP applications in bank marketing, focusing on their integration across the customer journey and operational excellence. Employing the PRISMA methodology, this study systematically reviews existing literature to assess the current landscape of AI and NLP in bank marketing. Additionally, it incorporates semantic mapping using Sentence Transformers and UMAP for strategic gap analysis to identify underexplored areas and opportunities for future research. The systematic review reveals limited research specifically focused on NLP applications in bank marketing. The strategic gap analysis identifies key areas where NLP can further enhance marketing strategies, including customer-centric applications like acquisition, retention, and personalized engagement, offering valuable insights for both academic research and practical implementation. This research contributes to the field of bank marketing by mapping the current state of AI and NLP applications and identifying strategic gaps. The findings provide actionable insights for developing NLP-driven growth and innovation frameworks and highlight the role of NLP in improving operational efficiency and regulatory compliance. This work has broader implications for enhancing customer experience, profitability, and innovation in the banking industry.
Energy Price Modelling: A Comparative Evaluation of four Generations of Forecasting Methods
Nov 05, 2024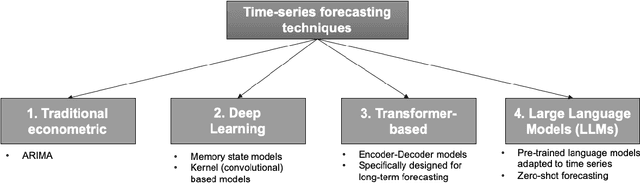


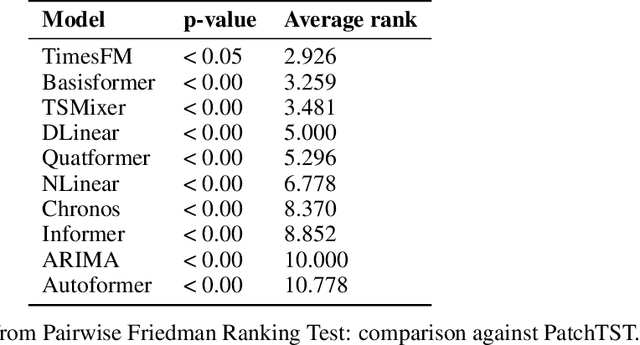
Energy is a critical driver of modern economic systems. Accurate energy price forecasting plays an important role in supporting decision-making at various levels, from operational purchasing decisions at individual business organizations to policy-making. A significant body of literature has looked into energy price forecasting, investigating a wide range of methods to improve accuracy and inform these critical decisions. Given the evolving landscape of forecasting techniques, the literature lacks a thorough empirical comparison that systematically contrasts these methods. This paper provides an in-depth review of the evolution of forecasting modeling frameworks, from well-established econometric models to machine learning methods, early sequence learners such LSTMs, and more recent advancements in deep learning with transformer networks, which represent the cutting edge in forecasting. We offer a detailed review of the related literature and categorize forecasting methodologies into four model families. We also explore emerging concepts like pre-training and transfer learning, which have transformed the analysis of unstructured data and hold significant promise for time series forecasting. We address a gap in the literature by performing a comprehensive empirical analysis on these four family models, using data from the EU energy markets, we conduct a large-scale empirical study, which contrasts the forecasting accuracy of different approaches, focusing especially on alternative propositions for time series transformers.
How much do we really know about Structure Learning from i.i.d. Data? Interpretable, multi-dimensional Performance Indicator for Causal Discovery
Sep 28, 2024Nonlinear causal discovery from observational data imposes strict identifiability assumptions on the formulation of structural equations utilized in the data generating process. The evaluation of structure learning methods under assumption violations requires a rigorous and interpretable approach, which quantifies both the structural similarity of the estimation with the ground truth and the capacity of the discovered graphs to be used for causal inference. Motivated by the lack of unified performance assessment framework, we introduce an interpretable, six-dimensional evaluation metric, i.e., distance to optimal solution (DOS), which is specifically tailored to the field of causal discovery. Furthermore, this is the first research to assess the performance of structure learning algorithms from seven different families on increasing percentage of non-identifiable, nonlinear causal patterns, inspired by real-world processes. Our large-scale simulation study, which incorporates seven experimental factors, shows that besides causal order-based methods, amortized causal discovery delivers results with comparatively high proximity to the optimal solution. In addition to the findings from our sensitivity analysis, we explore interactions effects between the experimental factors of our simulation framework in order to provide transparency about the expected performance of causal discovery techniques in different scenarios.
Fighting Sampling Bias: A Framework for Training and Evaluating Credit Scoring Models
Jul 17, 2024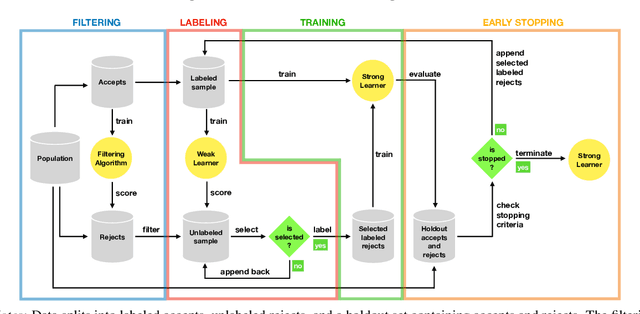

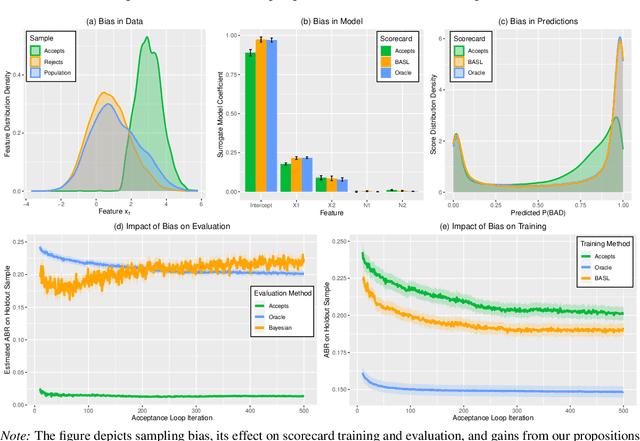
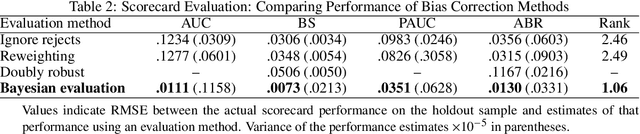
Scoring models support decision-making in financial institutions. Their estimation and evaluation are based on the data of previously accepted applicants with known repayment behavior. This creates sampling bias: the available labeled data offers a partial picture of the distribution of candidate borrowers, which the model is supposed to score. The paper addresses the adverse effect of sampling bias on model training and evaluation. To improve scorecard training, we propose bias-aware self-learning - a reject inference framework that augments the biased training data by inferring labels for selected rejected applications. For scorecard evaluation, we propose a Bayesian framework that extends standard accuracy measures to the biased setting and provides a reliable estimate of future scorecard performance. Extensive experiments on synthetic and real-world data confirm the superiority of our propositions over various benchmarks in predictive performance and profitability. By sensitivity analysis, we also identify boundary conditions affecting their performance. Notably, we leverage real-world data from a randomized controlled trial to assess the novel methodologies on holdout data that represent the true borrower population. Our findings confirm that reject inference is a difficult problem with modest potential to improve scorecard performance. Addressing sampling bias during scorecard evaluation is a much more promising route to improve scoring practices. For example, our results suggest a profit improvement of about eight percent, when using Bayesian evaluation to decide on acceptance rates.
Leveraging Zero-Shot Prompting for Efficient Language Model Distillation
Mar 23, 2024This paper introduces a novel approach for efficiently distilling LLMs into smaller, application-specific models, significantly reducing operational costs and manual labor. Addressing the challenge of deploying computationally intensive LLMs in specific applications or edge devices, this technique utilizes LLMs' reasoning capabilities to generate labels and natural language rationales for unlabeled data. Our approach enhances both finetuning and distillation by employing a multi-task training framework where student models mimic these rationales alongside teacher predictions. Key contributions include the employment of zero-shot prompting to elicit teacher model rationales, reducing the necessity for handcrafted few-shot examples and lowering the overall token count required, which directly translates to cost savings given the pay-per-token billing model of major tech companies' LLM APIs. Additionally, the paper investigates the impact of explanation properties on distillation efficiency, demonstrating that minimal performance loss occurs even when rationale augmentation is not applied across the entire dataset, facilitating further reductions of tokens. This research marks a step toward the efficient training of task-specific models with minimal human intervention, offering substantial cost-savings while maintaining, or even enhancing, performance.
The impact of heteroskedasticity on uplift modeling
Dec 08, 2023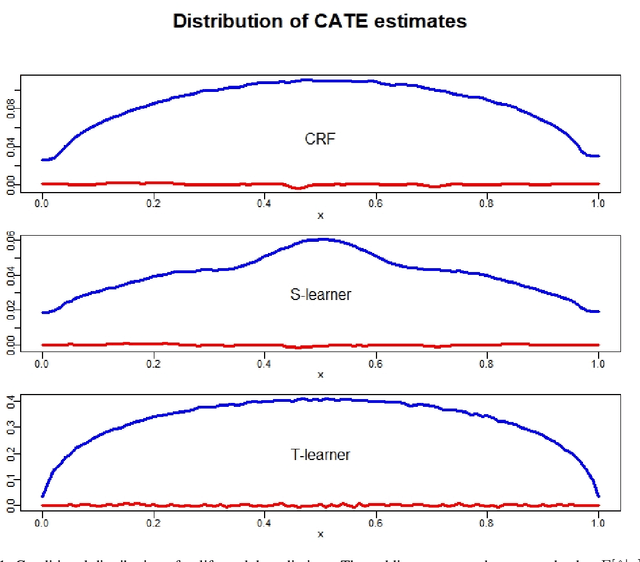
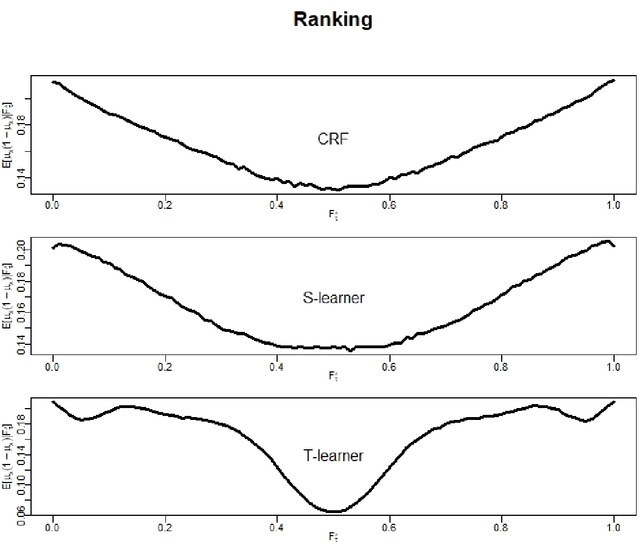
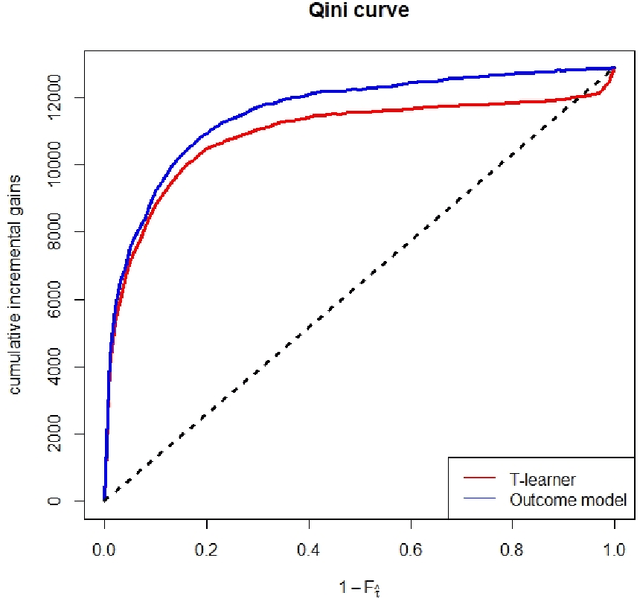
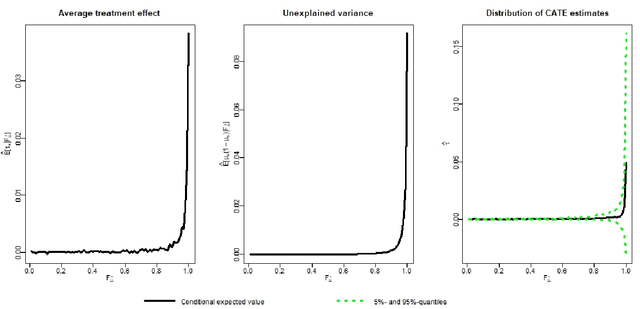
There are various applications, where companies need to decide to which individuals they should best allocate treatment. To support such decisions, uplift models are applied to predict treatment effects on an individual level. Based on the predicted treatment effects, individuals can be ranked and treatment allocation can be prioritized according to this ranking. An implicit assumption, which has not been doubted in the previous uplift modeling literature, is that this treatment prioritization approach tends to bring individuals with high treatment effects to the top and individuals with low treatment effects to the bottom of the ranking. In our research, we show that heteroskedastictity in the training data can cause a bias of the uplift model ranking: individuals with the highest treatment effects can get accumulated in large numbers at the bottom of the ranking. We explain theoretically how heteroskedasticity can bias the ranking of uplift models and show this process in a simulation and on real-world data. We argue that this problem of ranking bias due to heteroskedasticity might occur in many real-world applications and requires modification of the treatment prioritization to achieve an efficient treatment allocation.
Forecasting Cryptocurrency Prices Using Deep Learning: Integrating Financial, Blockchain, and Text Data
Nov 23, 2023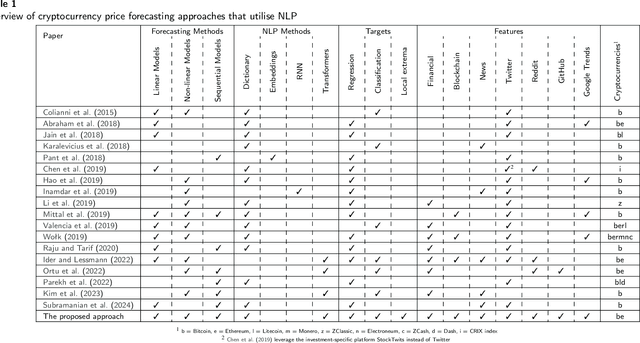
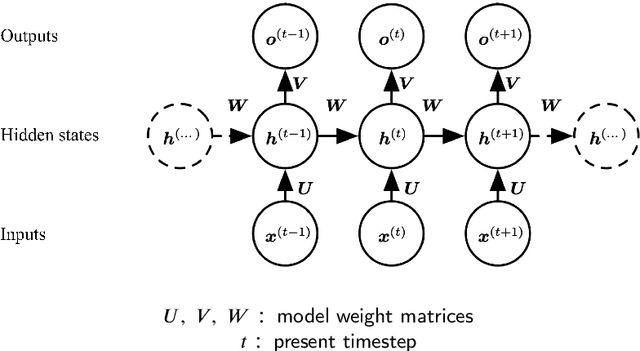
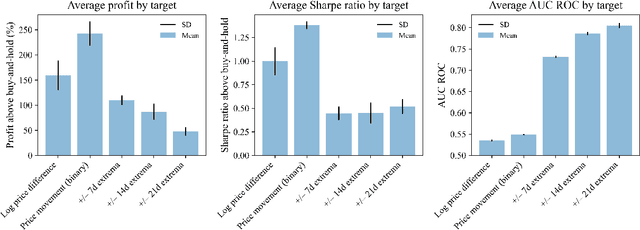
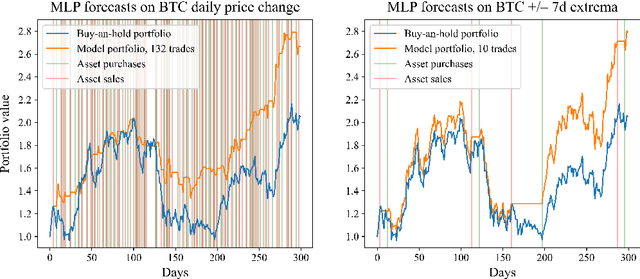
This paper explores the application of Machine Learning (ML) and Natural Language Processing (NLP) techniques in cryptocurrency price forecasting, specifically Bitcoin (BTC) and Ethereum (ETH). Focusing on news and social media data, primarily from Twitter and Reddit, we analyse the influence of public sentiment on cryptocurrency valuations using advanced deep learning NLP methods. Alongside conventional price regression, we treat cryptocurrency price forecasting as a classification problem. This includes both the prediction of price movements (up or down) and the identification of local extrema. We compare the performance of various ML models, both with and without NLP data integration. Our findings reveal that incorporating NLP data significantly enhances the forecasting performance of our models. We discover that pre-trained models, such as Twitter-RoBERTa and BART MNLI, are highly effective in capturing market sentiment, and that fine-tuning Large Language Models (LLMs) also yields substantial forecasting improvements. Notably, the BART MNLI zero-shot classification model shows considerable proficiency in extracting bullish and bearish signals from textual data. All of our models consistently generate profit across different validation scenarios, with no observed decline in profits or reduction in the impact of NLP data over time. The study highlights the potential of text analysis in improving financial forecasts and demonstrates the effectiveness of various NLP techniques in capturing nuanced market sentiment.