 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding the Sweet Spot: Trading Quality, Cost, and Speed During Inference-Time LLM Reflection
Oct 23, 2025As Large Language Models (LLMs) continue to evolve, practitioners face increasing options for enhancing inference-time performance without model retraining, including budget tuning and multi-step techniques like self-reflection. While these methods improve output quality, they create complex trade-offs among accuracy, cost, and latency that remain poorly understood across different domains. This paper systematically compares self-reflection and budget tuning across mathematical reasoning and translation tasks. We evaluate prominent LLMs, including Anthropic Claude, Amazon Nova, and Mistral families, along with other models under varying reflection depths and compute budgets to derive Pareto optimal performance frontiers. Our analysis reveals substantial domain dependent variation in self-reflection effectiveness, with performance gains up to 220\% in mathematical reasoning. We further investigate how reflection round depth and feedback mechanism quality influence performance across model families. To validate our findings in a real-world setting, we deploy a self-reflection enhanced marketing content localisation system at Lounge by Zalando, where it shows market-dependent effectiveness, reinforcing the importance of domain specific evaluation when deploying these techniques. Our results provide actionable guidance for selecting optimal inference strategies given specific domains and resource constraints. We open source our self-reflection implementation for reproducibility at https://github.com/aws-samples/sample-genai-reflection-for-bedrock.
Fighting Sampling Bias: A Framework for Training and Evaluating Credit Scoring Models
Jul 17, 2024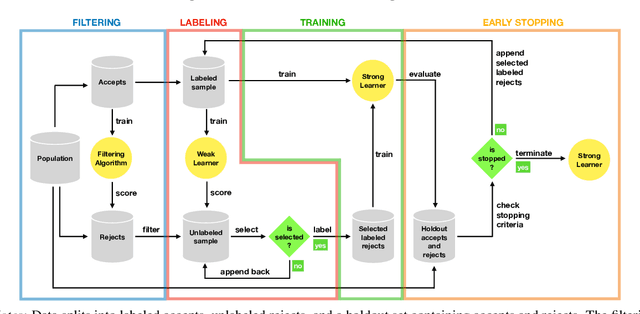

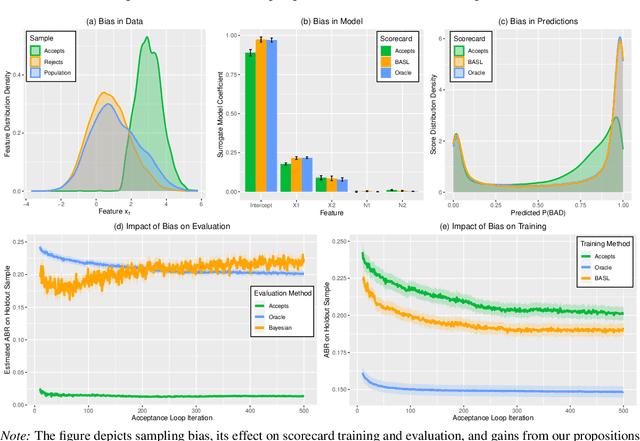
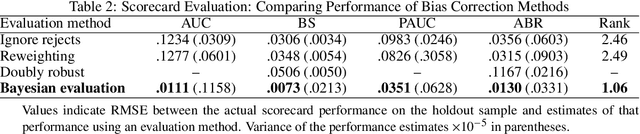
Scoring models support decision-making in financial institutions. Their estimation and evaluation are based on the data of previously accepted applicants with known repayment behavior. This creates sampling bias: the available labeled data offers a partial picture of the distribution of candidate borrowers, which the model is supposed to score. The paper addresses the adverse effect of sampling bias on model training and evaluation. To improve scorecard training, we propose bias-aware self-learning - a reject inference framework that augments the biased training data by inferring labels for selected rejected applications. For scorecard evaluation, we propose a Bayesian framework that extends standard accuracy measures to the biased setting and provides a reliable estimate of future scorecard performance. Extensive experiments on synthetic and real-world data confirm the superiority of our propositions over various benchmarks in predictive performance and profitability. By sensitivity analysis, we also identify boundary conditions affecting their performance. Notably, we leverage real-world data from a randomized controlled trial to assess the novel methodologies on holdout data that represent the true borrower population. Our findings confirm that reject inference is a difficult problem with modest potential to improve scorecard performance. Addressing sampling bias during scorecard evaluation is a much more promising route to improve scoring practices. For example, our results suggest a profit improvement of about eight percent, when using Bayesian evaluation to decide on acceptance rates.
Probabilistic Demand Forecasting with Graph Neural Networks
Jan 23, 2024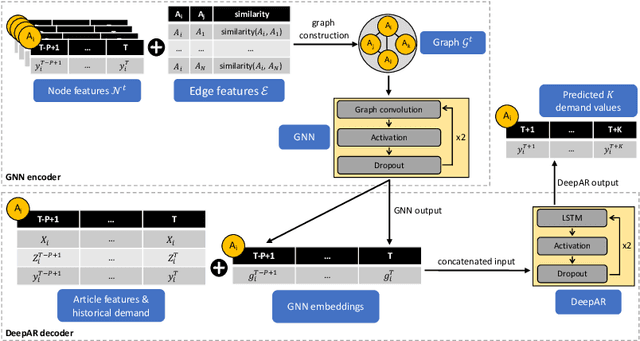



Demand forecasting is a prominent business use case that allows retailers to optimize inventory planning, logistics, and core business decisions. One of the key challenges in demand forecasting is accounting for relationships and interactions between articles. Most modern forecasting approaches provide independent article-level predictions that do not consider the impact of related articles. Recent research has attempted addressing this challenge using Graph Neural Networks (GNNs) and showed promising results. This paper builds on previous research on GNNs and makes two contributions. First, we integrate a GNN encoder into a state-of-the-art DeepAR model. The combined model produces probabilistic forecasts, which are crucial for decision-making under uncertainty. Second, we propose to build graphs using article attribute similarity, which avoids reliance on a pre-defined graph structure. Experiments on three real-world datasets show that the proposed approach consistently outperforms non-graph benchmarks. We also show that our approach produces article embeddings that encode article similarity and demand dynamics and are useful for other downstream business tasks beyond forecasting.
Fairness in Credit Scoring: Assessment, Implementation and Profit Implications
Mar 04, 2021
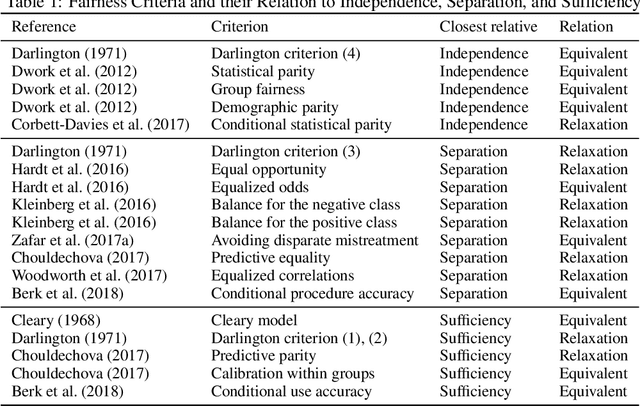
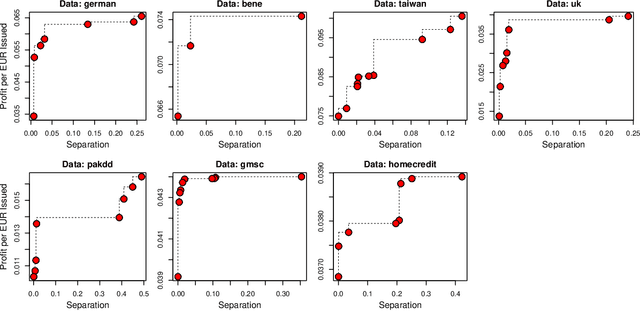

The rise of algorithmic decision-making has spawned much research on fair machine learning (ML). Financial institutions use ML for building risk scorecards that support a range of credit-related decisions. Yet, the literature on fair ML in credit scoring is scarce. The paper makes two contributions. First, we provide a systematic overview of algorithmic options for incorporating fairness goals in the ML model development pipeline. In this scope, we also consolidate the space of statistical fairness criteria and examine their adequacy for credit scoring. Second, we perform an empirical study of different fairness processors in a profit-oriented credit scoring setup using seven real-world data sets. The empirical results substantiate the evaluation of fairness measures, identify more and less suitable options to implement fair credit scoring, and clarify the profit-fairness trade-off in lending decisions. Specifically, we find that multiple fairness criteria can be approximately satisfied at once and identify separation as a proper criterion for measuring the fairness of a scorecard. We also find fair in-processors to deliver a good balance between profit and fairness. More generally, we show that algorithmic discrimination can be reduced to a reasonable level at a relatively low cost.
Shallow Self-Learning for Reject Inference in Credit Scoring
Sep 13, 2019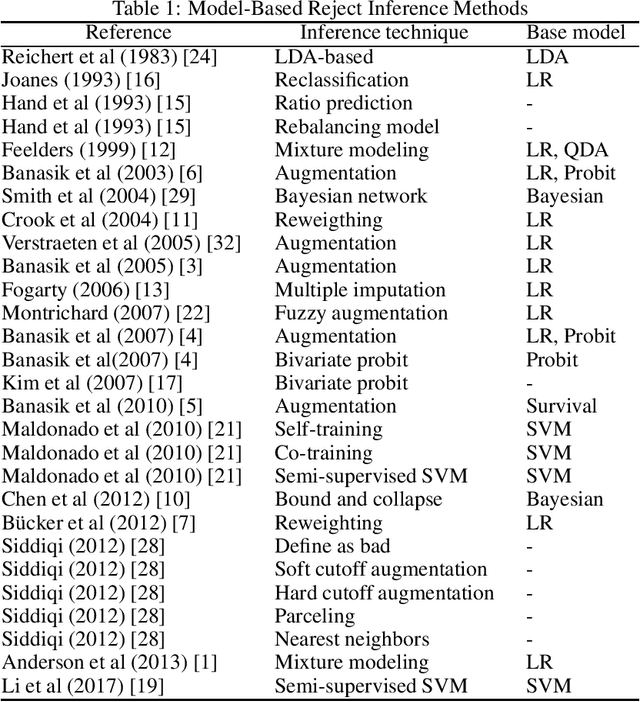



Credit scoring models support loan approval decisions in the financial services industry. Lenders train these models on data from previously granted credit applications, where the borrowers' repayment behavior has been observed. This approach creates sample bias. The scoring model (i.e., classifier) is trained on accepted cases only. Applying the resulting model to screen credit applications from the population of all borrowers degrades model performance. Reject inference comprises techniques to overcome sampling bias through assigning labels to rejected cases. The paper makes two contributions. First, we propose a self-learning framework for reject inference. The framework is geared toward real-world credit scoring requirements through considering distinct training regimes for iterative labeling and model training. Second, we introduce a new measure to assess the effectiveness of reject inference strategies. Our measure leverages domain knowledge to avoid artificial labeling of rejected cases during strategy evaluation. We demonstrate this approach to offer a robust and operational assessment of reject inference strategies. Experiments on a real-world credit scoring data set confirm the superiority of the adjusted self-learning framework over regular self-learning and previous reject inference strategies. We also find strong evidence in favor of the proposed evaluation measure assessing reject inference strategies more reliably, raising the performance of the eventual credit scoring model.