 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFighting Sampling Bias: A Framework for Training and Evaluating Credit Scoring Models
Jul 17, 2024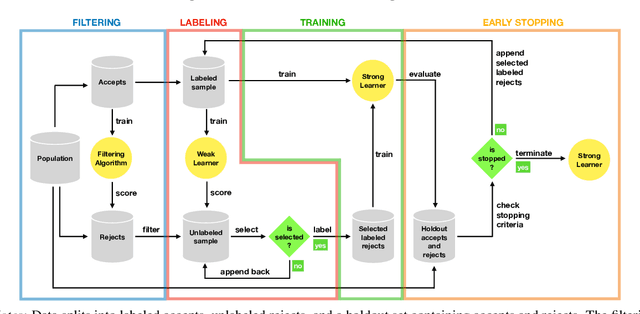

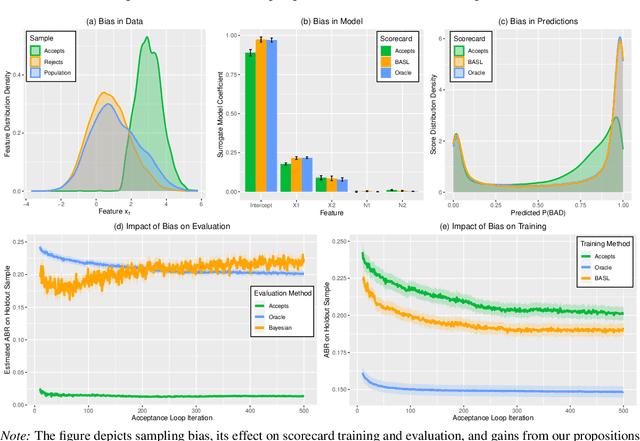
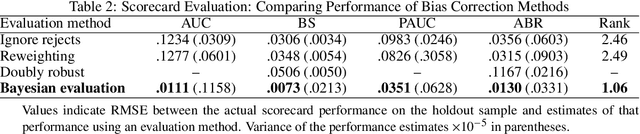
Scoring models support decision-making in financial institutions. Their estimation and evaluation are based on the data of previously accepted applicants with known repayment behavior. This creates sampling bias: the available labeled data offers a partial picture of the distribution of candidate borrowers, which the model is supposed to score. The paper addresses the adverse effect of sampling bias on model training and evaluation. To improve scorecard training, we propose bias-aware self-learning - a reject inference framework that augments the biased training data by inferring labels for selected rejected applications. For scorecard evaluation, we propose a Bayesian framework that extends standard accuracy measures to the biased setting and provides a reliable estimate of future scorecard performance. Extensive experiments on synthetic and real-world data confirm the superiority of our propositions over various benchmarks in predictive performance and profitability. By sensitivity analysis, we also identify boundary conditions affecting their performance. Notably, we leverage real-world data from a randomized controlled trial to assess the novel methodologies on holdout data that represent the true borrower population. Our findings confirm that reject inference is a difficult problem with modest potential to improve scorecard performance. Addressing sampling bias during scorecard evaluation is a much more promising route to improve scoring practices. For example, our results suggest a profit improvement of about eight percent, when using Bayesian evaluation to decide on acceptance rates.
Peer Grading in a Course on Algorithms and Data Structures: Machine Learning Algorithms do not Improve over Simple Baselines
Feb 10, 2016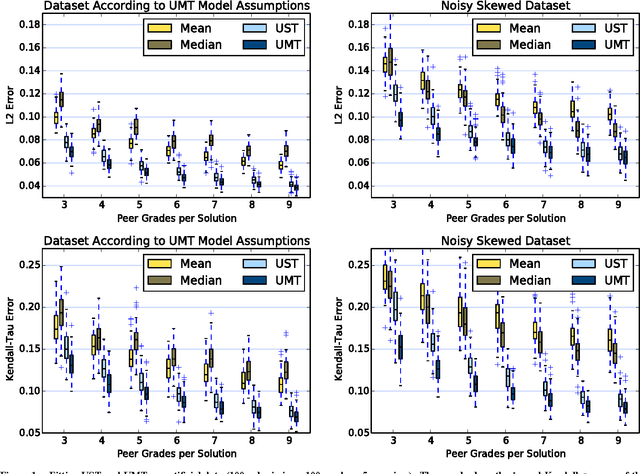
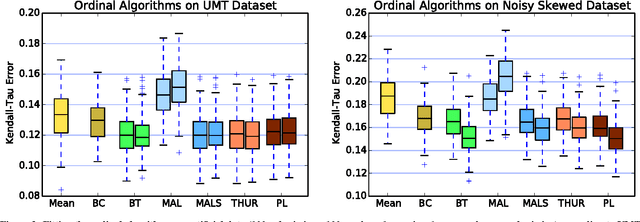
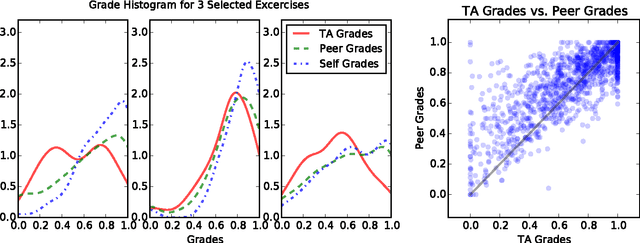
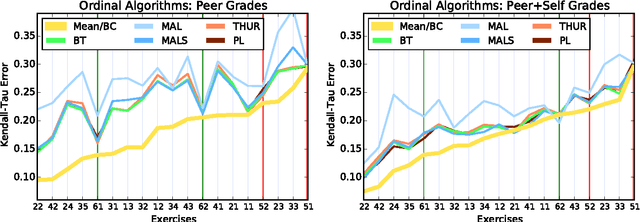
Peer grading is the process of students reviewing each others' work, such as homework submissions, and has lately become a popular mechanism used in massive open online courses (MOOCs). Intrigued by this idea, we used it in a course on algorithms and data structures at the University of Hamburg. Throughout the whole semester, students repeatedly handed in submissions to exercises, which were then evaluated both by teaching assistants and by a peer grading mechanism, yielding a large dataset of teacher and peer grades. We applied different statistical and machine learning methods to aggregate the peer grades in order to come up with accurate final grades for the submissions (supervised and unsupervised, methods based on numeric scores and ordinal rankings). Surprisingly, none of them improves over the baseline of using the mean peer grade as the final grade. We discuss a number of possible explanations for these results and present a thorough analysis of the generated dataset.
Shortest path distance in random k-nearest neighbor graphs
Jul 09, 2012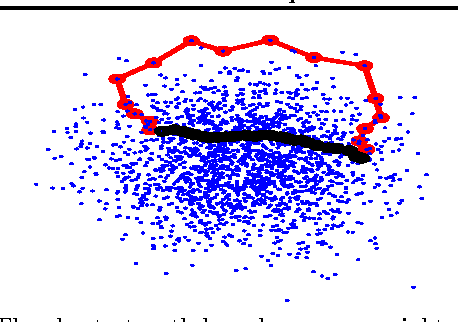

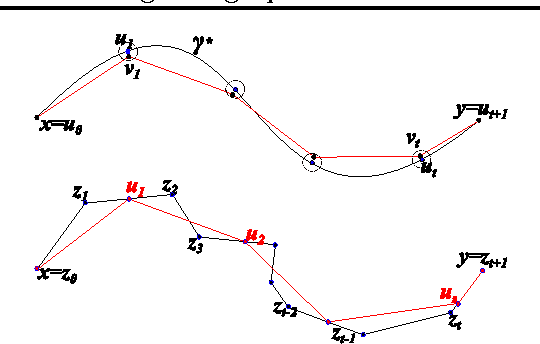
Consider a weighted or unweighted k-nearest neighbor graph that has been built on n data points drawn randomly according to some density p on R^d. We study the convergence of the shortest path distance in such graphs as the sample size tends to infinity. We prove that for unweighted kNN graphs, this distance converges to an unpleasant distance function on the underlying space whose properties are detrimental to machine learning. We also study the behavior of the shortest path distance in weighted kNN graphs.