 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeer Grading in a Course on Algorithms and Data Structures: Machine Learning Algorithms do not Improve over Simple Baselines
Paper and Code
Feb 10, 2016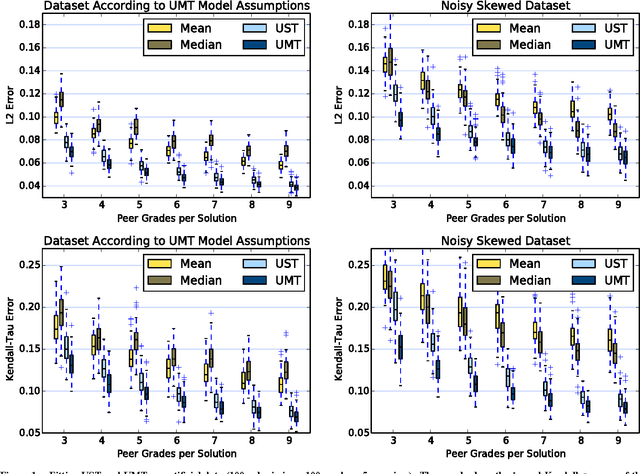
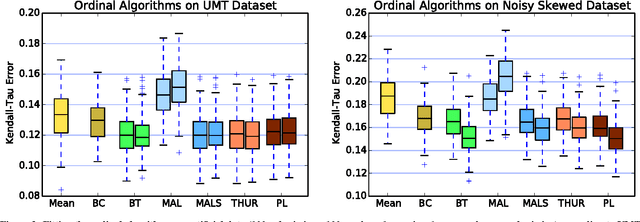
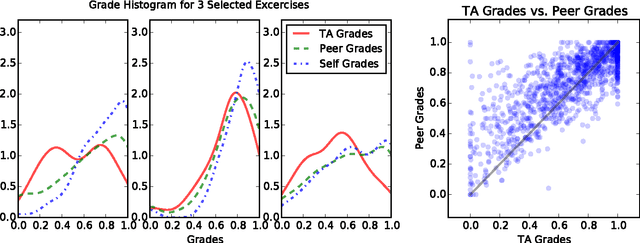
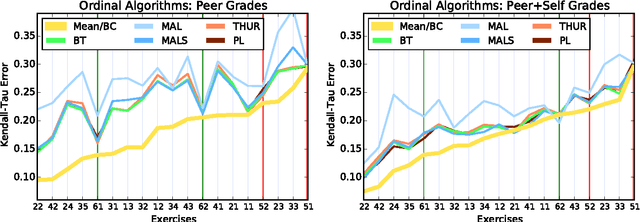
Peer grading is the process of students reviewing each others' work, such as homework submissions, and has lately become a popular mechanism used in massive open online courses (MOOCs). Intrigued by this idea, we used it in a course on algorithms and data structures at the University of Hamburg. Throughout the whole semester, students repeatedly handed in submissions to exercises, which were then evaluated both by teaching assistants and by a peer grading mechanism, yielding a large dataset of teacher and peer grades. We applied different statistical and machine learning methods to aggregate the peer grades in order to come up with accurate final grades for the submissions (supervised and unsupervised, methods based on numeric scores and ordinal rankings). Surprisingly, none of them improves over the baseline of using the mean peer grade as the final grade. We discuss a number of possible explanations for these results and present a thorough analysis of the generated dataset.