 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Reconstructing Dynamic Scenes One D4RT at a Time
Dec 10, 2025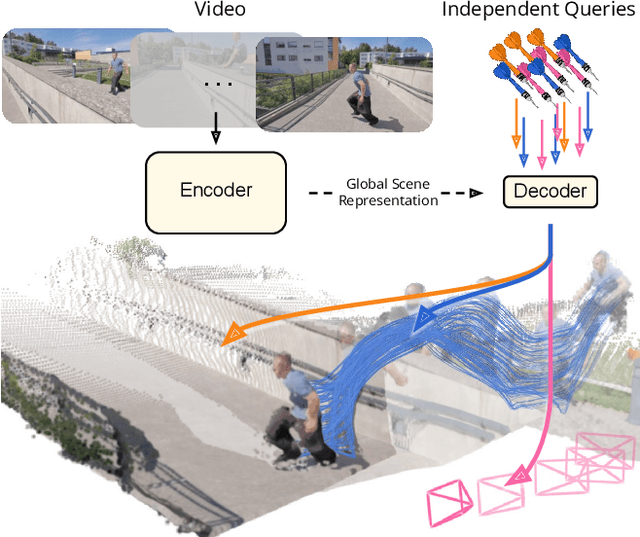

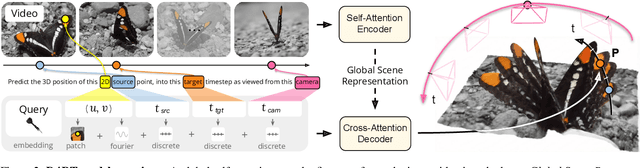
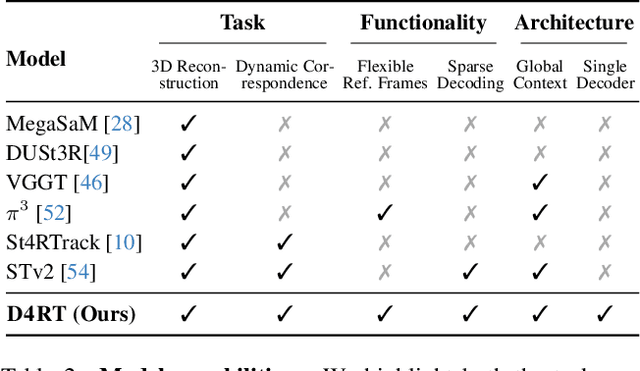
Understanding and reconstructing the complex geometry and motion of dynamic scenes from video remains a formidable challenge in computer vision. This paper introduces D4RT, a simple yet powerful feedforward model designed to efficiently solve this task. D4RT utilizes a unified transformer architecture to jointly infer depth, spatio-temporal correspondence, and full camera parameters from a single video. Its core innovation is a novel querying mechanism that sidesteps the heavy computation of dense, per-frame decoding and the complexity of managing multiple, task-specific decoders. Our decoding interface allows the model to independently and flexibly probe the 3D position of any point in space and time. The result is a lightweight and highly scalable method that enables remarkably efficient training and inference. We demonstrate that our approach sets a new state of the art, outperforming previous methods across a wide spectrum of 4D reconstruction tasks. We refer to the project webpage for animated results: https://d4rt-paper.github.io/.
Direct Motion Models for Assessing Generated Videos
Apr 30, 2025A current limitation of video generative video models is that they generate plausible looking frames, but poor motion -- an issue that is not well captured by FVD and other popular methods for evaluating generated videos. Here we go beyond FVD by developing a metric which better measures plausible object interactions and motion. Our novel approach is based on auto-encoding point tracks and yields motion features that can be used to not only compare distributions of videos (as few as one generated and one ground truth, or as many as two datasets), but also for evaluating motion of single videos. We show that using point tracks instead of pixel reconstruction or action recognition features results in a metric which is markedly more sensitive to temporal distortions in synthetic data, and can predict human evaluations of temporal consistency and realism in generated videos obtained from open-source models better than a wide range of alternatives. We also show that by using a point track representation, we can spatiotemporally localize generative video inconsistencies, providing extra interpretability of generated video errors relative to prior work. An overview of the results and link to the code can be found on the project page: http://trajan-paper.github.io.
TAPNext: Tracking Any Point (TAP) as Next Token Prediction
Apr 08, 2025Tracking Any Point (TAP) in a video is a challenging computer vision problem with many demonstrated applications in robotics, video editing, and 3D reconstruction. Existing methods for TAP rely heavily on complex tracking-specific inductive biases and heuristics, limiting their generality and potential for scaling. To address these challenges, we present TAPNext, a new approach that casts TAP as sequential masked token decoding. Our model is causal, tracks in a purely online fashion, and removes tracking-specific inductive biases. This enables TAPNext to run with minimal latency, and removes the temporal windowing required by many existing state of art trackers. Despite its simplicity, TAPNext achieves a new state-of-the-art tracking performance among both online and offline trackers. Finally, we present evidence that many widely used tracking heuristics emerge naturally in TAPNext through end-to-end training.
From Image to Video: An Empirical Study of Diffusion Representations
Feb 10, 2025Diffusion models have revolutionized generative modeling, enabling unprecedented realism in image and video synthesis. This success has sparked interest in leveraging their representations for visual understanding tasks. While recent works have explored this potential for image generation, the visual understanding capabilities of video diffusion models remain largely uncharted. To address this gap, we systematically compare the same model architecture trained for video versus image generation, analyzing the performance of their latent representations on various downstream tasks including image classification, action recognition, depth estimation, and tracking. Results show that video diffusion models consistently outperform their image counterparts, though we find a striking range in the extent of this superiority. We further analyze features extracted from different layers and with varying noise levels, as well as the effect of model size and training budget on representation and generation quality. This work marks the first direct comparison of video and image diffusion objectives for visual understanding, offering insights into the role of temporal information in representation learning.
Scaling 4D Representations
Dec 19, 2024



Scaling has not yet been convincingly demonstrated for pure self-supervised learning from video. However, prior work has focused evaluations on semantic-related tasks $\unicode{x2013}$ action classification, ImageNet classification, etc. In this paper we focus on evaluating self-supervised learning on non-semantic vision tasks that are more spatial (3D) and temporal (+1D = 4D), such as camera pose estimation, point and object tracking, and depth estimation. We show that by learning from very large video datasets, masked auto-encoding (MAE) with transformer video models actually scales, consistently improving performance on these 4D tasks, as model size increases from 20M all the way to the largest by far reported self-supervised video model $\unicode{x2013}$ 22B parameters. Rigorous apples-to-apples comparison with many recent image and video models demonstrates the benefits of scaling 4D representations.
TRecViT: A Recurrent Video Transformer
Dec 18, 2024We propose a novel block for video modelling. It relies on a time-space-channel factorisation with dedicated blocks for each dimension: gated linear recurrent units (LRUs) perform information mixing over time, self-attention layers perform mixing over space, and MLPs over channels. The resulting architecture TRecViT performs well on sparse and dense tasks, trained in supervised or self-supervised regimes. Notably, our model is causal and outperforms or is on par with a pure attention model ViViT-L on large scale video datasets (SSv2, Kinetics400), while having $3\times$ less parameters, $12\times$ smaller memory footprint, and $5\times$ lower FLOPs count. Code and checkpoints will be made available online at https://github.com/google-deepmind/trecvit.
Moving Off-the-Grid: Scene-Grounded Video Representations
Nov 08, 2024



Current vision models typically maintain a fixed correspondence between their representation structure and image space. Each layer comprises a set of tokens arranged "on-the-grid," which biases patches or tokens to encode information at a specific spatio(-temporal) location. In this work we present Moving Off-the-Grid (MooG), a self-supervised video representation model that offers an alternative approach, allowing tokens to move "off-the-grid" to better enable them to represent scene elements consistently, even as they move across the image plane through time. By using a combination of cross-attention and positional embeddings we disentangle the representation structure and image structure. We find that a simple self-supervised objective--next frame prediction--trained on video data, results in a set of latent tokens which bind to specific scene structures and track them as they move. We demonstrate the usefulness of MooG's learned representation both qualitatively and quantitatively by training readouts on top of the learned representation on a variety of downstream tasks. We show that MooG can provide a strong foundation for different vision tasks when compared to "on-the-grid" baselines.
DyST: Towards Dynamic Neural Scene Representations on Real-World Videos
Oct 09, 2023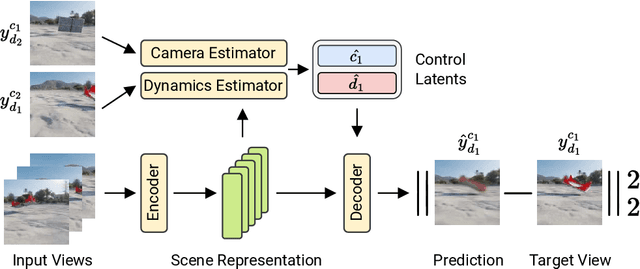
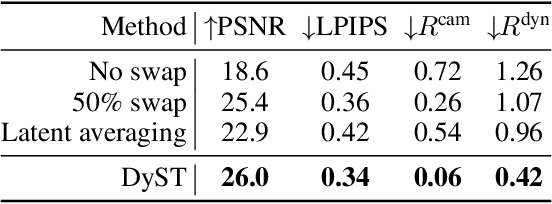


Visual understanding of the world goes beyond the semantics and flat structure of individual images. In this work, we aim to capture both the 3D structure and dynamics of real-world scenes from monocular real-world videos. Our Dynamic Scene Transformer (DyST) model leverages recent work in neural scene representation to learn a latent decomposition of monocular real-world videos into scene content, per-view scene dynamics, and camera pose. This separation is achieved through a novel co-training scheme on monocular videos and our new synthetic dataset DySO. DyST learns tangible latent representations for dynamic scenes that enable view generation with separate control over the camera and the content of the scene.
DORSal: Diffusion for Object-centric Representations of Scenes $\textit{et al.}$
Jun 13, 2023Recent progress in 3D scene understanding enables scalable learning of representations across large datasets of diverse scenes. As a consequence, generalization to unseen scenes and objects, rendering novel views from just a single or a handful of input images, and controllable scene generation that supports editing, is now possible. However, training jointly on a large number of scenes typically compromises rendering quality when compared to single-scene optimized models such as NeRFs. In this paper, we leverage recent progress in diffusion models to equip 3D scene representation learning models with the ability to render high-fidelity novel views, while retaining benefits such as object-level scene editing to a large degree. In particular, we propose DORSal, which adapts a video diffusion architecture for 3D scene generation conditioned on object-centric slot-based representations of scenes. On both complex synthetic multi-object scenes and on the real-world large-scale Street View dataset, we show that DORSal enables scalable neural rendering of 3D scenes with object-level editing and improves upon existing approaches.
Sensitivity of Slot-Based Object-Centric Models to their Number of Slots
May 30, 2023
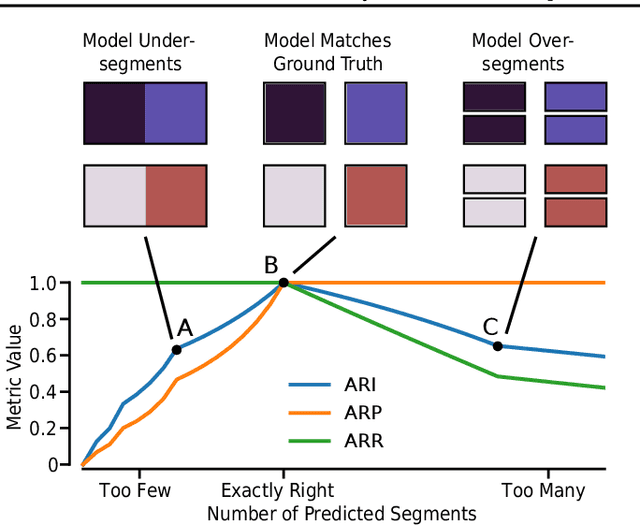
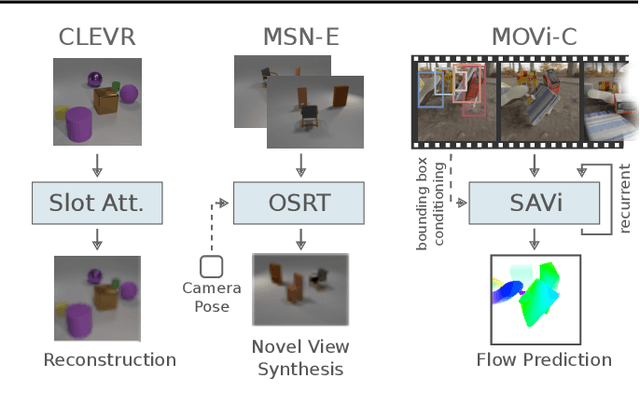
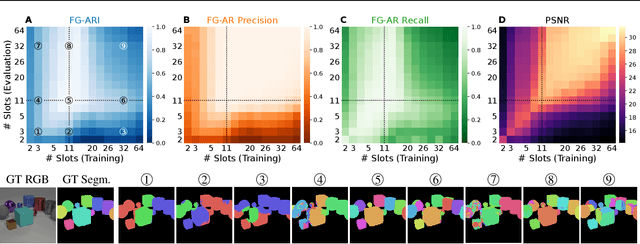
Self-supervised methods for learning object-centric representations have recently been applied successfully to various datasets. This progress is largely fueled by slot-based methods, whose ability to cluster visual scenes into meaningful objects holds great promise for compositional generalization and downstream learning. In these methods, the number of slots (clusters) $K$ is typically chosen to match the number of ground-truth objects in the data, even though this quantity is unknown in real-world settings. Indeed, the sensitivity of slot-based methods to $K$, and how this affects their learned correspondence to objects in the data has largely been ignored in the literature. In this work, we address this issue through a systematic study of slot-based methods. We propose using analogs to precision and recall based on the Adjusted Rand Index to accurately quantify model behavior over a large range of $K$. We find that, especially during training, incorrect choices of $K$ do not yield the desired object decomposition and, in fact, cause substantial oversegmentation or merging of separate objects (undersegmentation). We demonstrate that the choice of the objective function and incorporating instance-level annotations can moderately mitigate this behavior while still falling short of fully resolving this issue. Indeed, we show how this issue persists across multiple methods and datasets and stress its importance for future slot-based models.