 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mixed Diet Makes DINO An Omnivorous Vision Encoder
Feb 27, 2026Pre-trained vision encoders like DINOv2 have demonstrated exceptional performance on unimodal tasks. However, we observe that their feature representations are poorly aligned across different modalities. For instance, the feature embedding for an RGB image and its corresponding depth map of the same scene exhibit a cosine similarity that is nearly identical to that of two random, unrelated images. To address this, we propose the Omnivorous Vision Encoder, a novel framework that learns a modality-agnostic feature space. We train the encoder with a dual objective: first, to maximize the feature alignment between different modalities of the same scene; and second, a distillation objective that anchors the learned representations to the output of a fully frozen teacher such as DINOv2. The resulting student encoder becomes "omnivorous" by producing a consistent, powerful embedding for a given scene, regardless of the input modality (RGB, Depth, Segmentation, etc.). This approach enables robust cross-modal understanding while retaining the discriminative semantics of the original foundation model.
Scaling 4D Representations
Dec 19, 2024



Scaling has not yet been convincingly demonstrated for pure self-supervised learning from video. However, prior work has focused evaluations on semantic-related tasks $\unicode{x2013}$ action classification, ImageNet classification, etc. In this paper we focus on evaluating self-supervised learning on non-semantic vision tasks that are more spatial (3D) and temporal (+1D = 4D), such as camera pose estimation, point and object tracking, and depth estimation. We show that by learning from very large video datasets, masked auto-encoding (MAE) with transformer video models actually scales, consistently improving performance on these 4D tasks, as model size increases from 20M all the way to the largest by far reported self-supervised video model $\unicode{x2013}$ 22B parameters. Rigorous apples-to-apples comparison with many recent image and video models demonstrates the benefits of scaling 4D representations.
Probabilistic Inverse Cameras: Image to 3D via Multiview Geometry
Dec 13, 2024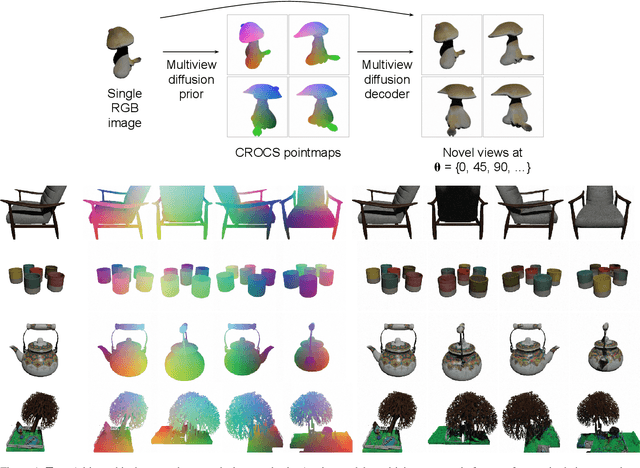

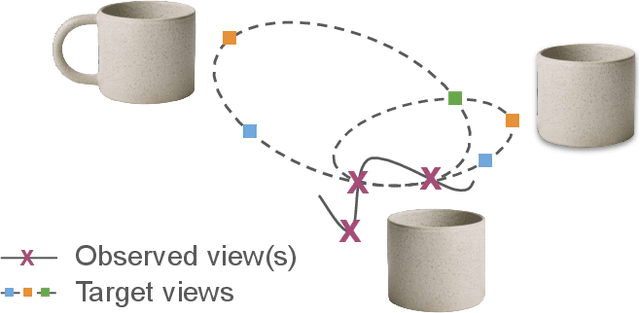

We introduce a hierarchical probabilistic approach to go from a 2D image to multiview 3D: a diffusion "prior" models the unseen 3D geometry, which then conditions a diffusion "decoder" to generate novel views of the subject. We use a pointmap-based geometric representation in a multiview image format to coordinate the generation of multiple target views simultaneously. We facilitate correspondence between views by assuming fixed target camera poses relative to the source camera, and constructing a predictable distribution of geometric features per target. Our modular, geometry-driven approach to novel-view synthesis (called "unPIC") beats SoTA baselines such as CAT3D and One-2-3-45 on held-out objects from ObjaverseXL, as well as real-world objects ranging from Google Scanned Objects, Amazon Berkeley Objects, to the Digital Twin Catalog.
Moving Off-the-Grid: Scene-Grounded Video Representations
Nov 08, 2024



Current vision models typically maintain a fixed correspondence between their representation structure and image space. Each layer comprises a set of tokens arranged "on-the-grid," which biases patches or tokens to encode information at a specific spatio(-temporal) location. In this work we present Moving Off-the-Grid (MooG), a self-supervised video representation model that offers an alternative approach, allowing tokens to move "off-the-grid" to better enable them to represent scene elements consistently, even as they move across the image plane through time. By using a combination of cross-attention and positional embeddings we disentangle the representation structure and image structure. We find that a simple self-supervised objective--next frame prediction--trained on video data, results in a set of latent tokens which bind to specific scene structures and track them as they move. We demonstrate the usefulness of MooG's learned representation both qualitatively and quantitatively by training readouts on top of the learned representation on a variety of downstream tasks. We show that MooG can provide a strong foundation for different vision tasks when compared to "on-the-grid" baselines.
PaliGemma: A versatile 3B VLM for transfer
Jul 10, 2024



PaliGemma is an open Vision-Language Model (VLM) that is based on the SigLIP-So400m vision encoder and the Gemma-2B language model. It is trained to be a versatile and broadly knowledgeable base model that is effective to transfer. It achieves strong performance on a wide variety of open-world tasks. We evaluate PaliGemma on almost 40 diverse tasks including standard VLM benchmarks, but also more specialized tasks such as remote-sensing and segmentation.
Neural Assets: 3D-Aware Multi-Object Scene Synthesis with Image Diffusion Models
Jun 13, 2024
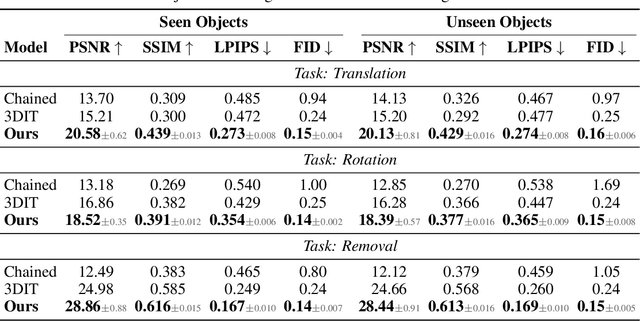

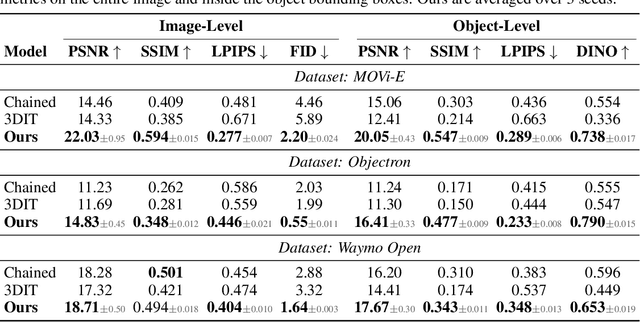
We address the problem of multi-object 3D pose control in image diffusion models. Instead of conditioning on a sequence of text tokens, we propose to use a set of per-object representations, Neural Assets, to control the 3D pose of individual objects in a scene. Neural Assets are obtained by pooling visual representations of objects from a reference image, such as a frame in a video, and are trained to reconstruct the respective objects in a different image, e.g., a later frame in the video. Importantly, we encode object visuals from the reference image while conditioning on object poses from the target frame. This enables learning disentangled appearance and pose features. Combining visual and 3D pose representations in a sequence-of-tokens format allows us to keep the text-to-image architecture of existing models, with Neural Assets in place of text tokens. By fine-tuning a pre-trained text-to-image diffusion model with this information, our approach enables fine-grained 3D pose and placement control of individual objects in a scene. We further demonstrate that Neural Assets can be transferred and recomposed across different scenes. Our model achieves state-of-the-art multi-object editing results on both synthetic 3D scene datasets, as well as two real-world video datasets (Objectron, Waymo Open).
Evaluating VLMs for Score-Based, Multi-Probe Annotation of 3D Objects
Nov 29, 2023Unlabeled 3D objects present an opportunity to leverage pretrained vision language models (VLMs) on a range of annotation tasks -- from describing object semantics to physical properties. An accurate response must take into account the full appearance of the object in 3D, various ways of phrasing the question/prompt, and changes in other factors that affect the response. We present a method to marginalize over any factors varied across VLM queries, utilizing the VLM's scores for sampled responses. We first show that this probabilistic aggregation can outperform a language model (e.g., GPT4) for summarization, for instance avoiding hallucinations when there are contrasting details between responses. Secondly, we show that aggregated annotations are useful for prompt-chaining; they help improve downstream VLM predictions (e.g., of object material when the object's type is specified as an auxiliary input in the prompt). Such auxiliary inputs allow ablating and measuring the contribution of visual reasoning over language-only reasoning. Using these evaluations, we show how VLMs can approach, without additional training or in-context learning, the quality of human-verified type and material annotations on the large-scale Objaverse dataset.
Constellation: Learning relational abstractions over objects for compositional imagination
Jul 23, 2021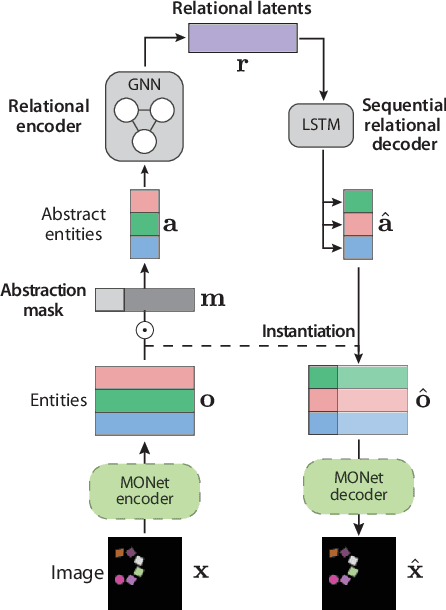
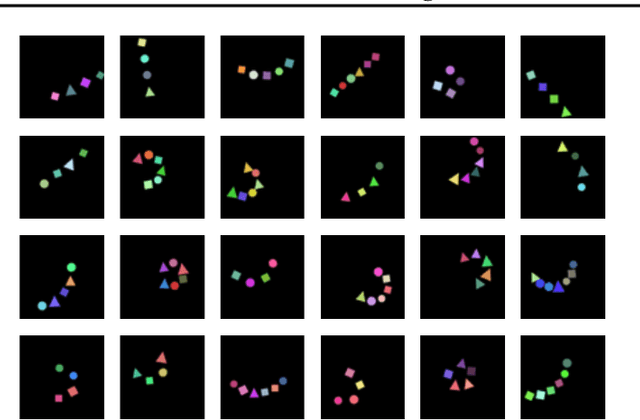


Learning structured representations of visual scenes is currently a major bottleneck to bridging perception with reasoning. While there has been exciting progress with slot-based models, which learn to segment scenes into sets of objects, learning configurational properties of entire groups of objects is still under-explored. To address this problem, we introduce Constellation, a network that learns relational abstractions of static visual scenes, and generalises these abstractions over sensory particularities, thus offering a potential basis for abstract relational reasoning. We further show that this basis, along with language association, provides a means to imagine sensory content in new ways. This work is a first step in the explicit representation of visual relationships and using them for complex cognitive procedures.
SIMONe: View-Invariant, Temporally-Abstracted Object Representations via Unsupervised Video Decomposition
Jun 07, 2021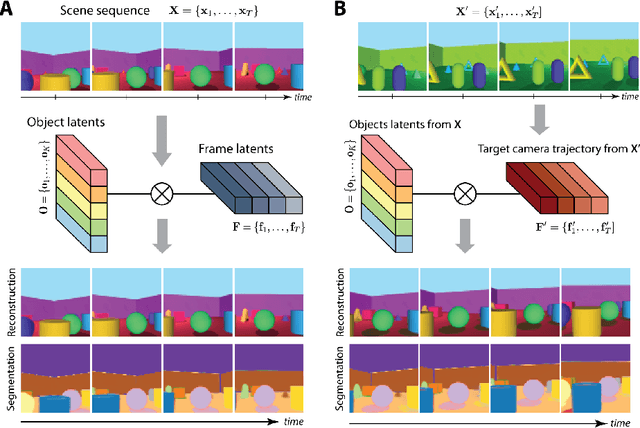
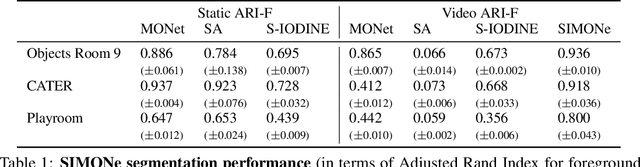
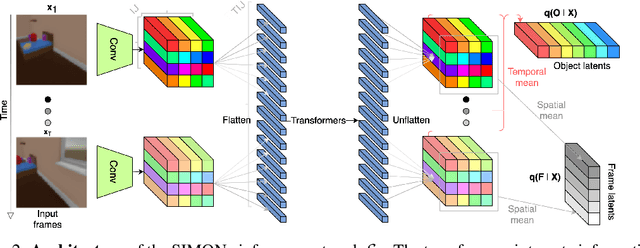

To help agents reason about scenes in terms of their building blocks, we wish to extract the compositional structure of any given scene (in particular, the configuration and characteristics of objects comprising the scene). This problem is especially difficult when scene structure needs to be inferred while also estimating the agent's location/viewpoint, as the two variables jointly give rise to the agent's observations. We present an unsupervised variational approach to this problem. Leveraging the shared structure that exists across different scenes, our model learns to infer two sets of latent representations from RGB video input alone: a set of "object" latents, corresponding to the time-invariant, object-level contents of the scene, as well as a set of "frame" latents, corresponding to global time-varying elements such as viewpoint. This factorization of latents allows our model, SIMONe, to represent object attributes in an allocentric manner which does not depend on viewpoint. Moreover, it allows us to disentangle object dynamics and summarize their trajectories as time-abstracted, view-invariant, per-object properties. We demonstrate these capabilities, as well as the model's performance in terms of view synthesis and instance segmentation, across three procedurally generated video datasets.
Unsupervised Object-Based Transition Models for 3D Partially Observable Environments
Mar 08, 2021
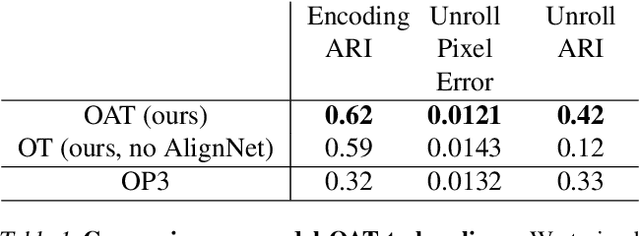
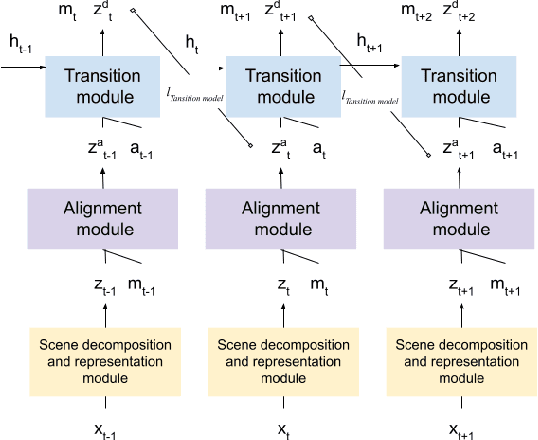

We present a slot-wise, object-based transition model that decomposes a scene into objects, aligns them (with respect to a slot-wise object memory) to maintain a consistent order across time, and predicts how those objects evolve over successive frames. The model is trained end-to-end without supervision using losses at the level of the object-structured representation rather than pixels. Thanks to its alignment module, the model deals properly with two issues that are not handled satisfactorily by other transition models, namely object persistence and object identity. We show that the combination of an object-level loss and correct object alignment over time enables the model to outperform a state-of-the-art baseline, and allows it to deal well with object occlusion and re-appearance in partially observable environments.