 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClawBench: Can AI Agents Complete Everyday Online Tasks?
Apr 09, 2026AI agents may be able to automate your inbox, but can they automate other routine aspects of your life? Everyday online tasks offer a realistic yet unsolved testbed for evaluating the next generation of AI agents. To this end, we introduce ClawBench, an evaluation framework of 153 simple tasks that people need to accomplish regularly in their lives and work, spanning 144 live platforms across 15 categories, from completing purchases and booking appointments to submitting job applications. These tasks require demanding capabilities beyond existing benchmarks, such as obtaining relevant information from user-provided documents, navigating multi-step workflows across diverse platforms, and write-heavy operations like filling in many detailed forms correctly. Unlike existing benchmarks that evaluate agents in offline sandboxes with static pages, ClawBench operates on production websites, preserving the full complexity, dynamic nature, and challenges of real-world web interaction. A lightweight interception layer captures and blocks only the final submission request, ensuring safe evaluation without real-world side effects. Our evaluations of 7 frontier models show that both proprietary and open-source models can complete only a small portion of these tasks. For example, Claude Sonnet 4.6 achieves only 33.3%. Progress on ClawBench brings us closer to AI agents that can function as reliable general-purpose assistants.
Watch Before You Answer: Learning from Visually Grounded Post-Training
Apr 06, 2026It is critical for vision-language models (VLMs) to comprehensively understand visual, temporal, and textual cues. However, despite rapid progress in multimodal modeling, video understanding performance still lags behind text-based reasoning. In this work, we find that progress is even worse than previously assumed: commonly reported long video understanding benchmarks contain 40-60% of questions that can be answered using text cues alone. Furthermore, we find that these issues are also pervasive in widely used post-training datasets, potentially undercutting the ability of post-training to improve VLM video understanding performance. Guided by this observation, we introduce VidGround as a simple yet effective solution: using only the actual visually grounded questions without any linguistic biases for post-training. When used in tandem with RL-based post-training algorithms, this simple technique improves performance by up to 6.2 points relative to using the full dataset, while using only 69.1% of the original post-training data. Moreover, we show that data curation with a simple post-training algorithm outperforms several more complex post-training techniques, highlighting that data quality is a major bottleneck for improving video understanding in VLMs. These results underscore the importance of curating post-training data and evaluation benchmarks that truly require visual grounding to advance the development of more capable VLMs. Project page: http://vidground.etuagi.com.
Under the Influence: Quantifying Persuasion and Vigilance in Large Language Models
Feb 26, 2026With increasing integration of Large Language Models (LLMs) into areas of high-stakes human decision-making, it is important to understand the risks they introduce as advisors. To be useful advisors, LLMs must sift through large amounts of content, written with both benevolent and malicious intent, and then use this information to convince a user to take a specific action. This involves two social capacities: vigilance (the ability to determine which information to use, and which to discard) and persuasion (synthesizing the available evidence to make a convincing argument). While existing work has investigated these capacities in isolation, there has been little prior investigation of how these capacities may be linked. Here, we use a simple multi-turn puzzle-solving game, Sokoban, to study LLMs' abilities to persuade and be rationally vigilant towards other LLM agents. We find that puzzle-solving performance, persuasive capability, and vigilance are dissociable capacities in LLMs. Performing well on the game does not automatically mean a model can detect when it is being misled, even if the possibility of deception is explicitly mentioned. However, LLMs do consistently modulate their token use, using fewer tokens to reason when advice is benevolent and more when it is malicious, even if they are still persuaded to take actions leading them to failure. To our knowledge, our work presents the first investigation of the relationship between persuasion, vigilance, and task performance in LLMs, and suggests that monitoring all three independently will be critical for future work in AI safety.
3DSPA: A 3D Semantic Point Autoencoder for Evaluating Video Realism
Feb 23, 2026AI video generation is evolving rapidly. For video generators to be useful for applications ranging from robotics to film-making, they must consistently produce realistic videos. However, evaluating the realism of generated videos remains a largely manual process -- requiring human annotation or bespoke evaluation datasets which have restricted scope. Here we develop an automated evaluation framework for video realism which captures both semantics and coherent 3D structure and which does not require access to a reference video. Our method, 3DSPA, is a 3D spatiotemporal point autoencoder which integrates 3D point trajectories, depth cues, and DINO semantic features into a unified representation for video evaluation. 3DSPA models how objects move and what is happening in the scene, enabling robust assessments of realism, temporal consistency, and physical plausibility. Experiments show that 3DSPA reliably identifies videos which violate physical laws, is more sensitive to motion artifacts, and aligns more closely with human judgments of video quality and realism across multiple datasets. Our results demonstrate that enriching trajectory-based representations with 3D semantics offers a stronger foundation for benchmarking generative video models, and implicitly captures physical rule violations. The code and pretrained model weights will be available at https://github.com/TheProParadox/3dspa_code.
AI Gamestore: Scalable, Open-Ended Evaluation of Machine General Intelligence with Human Games
Feb 19, 2026Rigorously evaluating machine intelligence against the broad spectrum of human general intelligence has become increasingly important and challenging in this era of rapid technological advance. Conventional AI benchmarks typically assess only narrow capabilities in a limited range of human activity. Most are also static, quickly saturating as developers explicitly or implicitly optimize for them. We propose that a more promising way to evaluate human-like general intelligence in AI systems is through a particularly strong form of general game playing: studying how and how well they play and learn to play \textbf{all conceivable human games}, in comparison to human players with the same level of experience, time, or other resources. We define a "human game" to be a game designed by humans for humans, and argue for the evaluative suitability of this space of all such games people can imagine and enjoy -- the "Multiverse of Human Games". Taking a first step towards this vision, we introduce the AI GameStore, a scalable and open-ended platform that uses LLMs with humans-in-the-loop to synthesize new representative human games, by automatically sourcing and adapting standardized and containerized variants of game environments from popular human digital gaming platforms. As a proof of concept, we generated 100 such games based on the top charts of Apple App Store and Steam, and evaluated seven frontier vision-language models (VLMs) on short episodes of play. The best models achieved less than 10\% of the human average score on the majority of the games, and especially struggled with games that challenge world-model learning, memory and planning. We conclude with a set of next steps for building out the AI GameStore as a practical way to measure and drive progress toward human-like general intelligence in machines.
Neural Assets: 3D-Aware Multi-Object Scene Synthesis with Image Diffusion Models
Jun 13, 2024
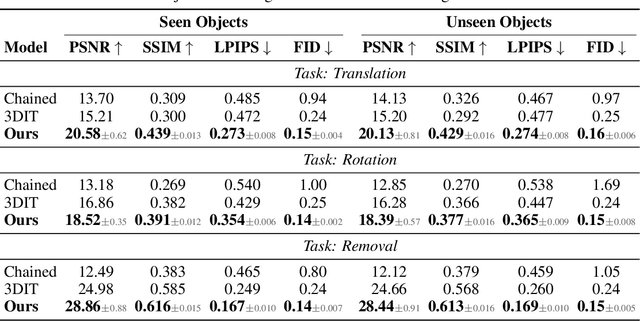

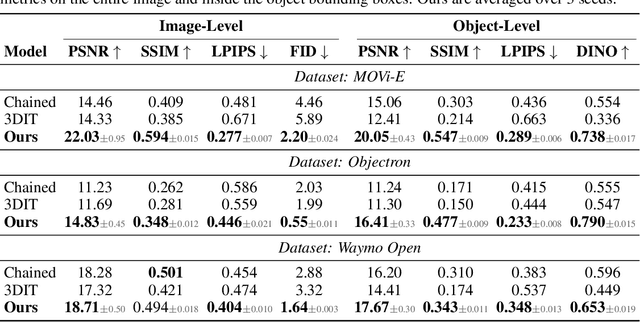
We address the problem of multi-object 3D pose control in image diffusion models. Instead of conditioning on a sequence of text tokens, we propose to use a set of per-object representations, Neural Assets, to control the 3D pose of individual objects in a scene. Neural Assets are obtained by pooling visual representations of objects from a reference image, such as a frame in a video, and are trained to reconstruct the respective objects in a different image, e.g., a later frame in the video. Importantly, we encode object visuals from the reference image while conditioning on object poses from the target frame. This enables learning disentangled appearance and pose features. Combining visual and 3D pose representations in a sequence-of-tokens format allows us to keep the text-to-image architecture of existing models, with Neural Assets in place of text tokens. By fine-tuning a pre-trained text-to-image diffusion model with this information, our approach enables fine-grained 3D pose and placement control of individual objects in a scene. We further demonstrate that Neural Assets can be transferred and recomposed across different scenes. Our model achieves state-of-the-art multi-object editing results on both synthetic 3D scene datasets, as well as two real-world video datasets (Objectron, Waymo Open).
Learning rigid-body simulators over implicit shapes for large-scale scenes and vision
May 22, 2024Simulating large scenes with many rigid objects is crucial for a variety of applications, such as robotics, engineering, film and video games. Rigid interactions are notoriously hard to model: small changes to the initial state or the simulation parameters can lead to large changes in the final state. Recently, learned simulators based on graph networks (GNNs) were developed as an alternative to hand-designed simulators like MuJoCo and PyBullet. They are able to accurately capture dynamics of real objects directly from real-world observations. However, current state-of-the-art learned simulators operate on meshes and scale poorly to scenes with many objects or detailed shapes. Here we present SDF-Sim, the first learned rigid-body simulator designed for scale. We use learned signed-distance functions (SDFs) to represent the object shapes and to speed up distance computation. We design the simulator to leverage SDFs and avoid the fundamental bottleneck of the previous simulators associated with collision detection. For the first time in literature, we demonstrate that we can scale the GNN-based simulators to scenes with hundreds of objects and up to 1.1 million nodes, where mesh-based approaches run out of memory. Finally, we show that SDF-Sim can be applied to real world scenes by extracting SDFs from multi-view images.
Scaling Face Interaction Graph Networks to Real World Scenes
Jan 22, 2024Accurately simulating real world object dynamics is essential for various applications such as robotics, engineering, graphics, and design. To better capture complex real dynamics such as contact and friction, learned simulators based on graph networks have recently shown great promise. However, applying these learned simulators to real scenes comes with two major challenges: first, scaling learned simulators to handle the complexity of real world scenes which can involve hundreds of objects each with complicated 3D shapes, and second, handling inputs from perception rather than 3D state information. Here we introduce a method which substantially reduces the memory required to run graph-based learned simulators. Based on this memory-efficient simulation model, we then present a perceptual interface in the form of editable NeRFs which can convert real-world scenes into a structured representation that can be processed by graph network simulator. We show that our method uses substantially less memory than previous graph-based simulators while retaining their accuracy, and that the simulators learned in synthetic environments can be applied to real world scenes captured from multiple camera angles. This paves the way for expanding the application of learned simulators to settings where only perceptual information is available at inference time.
Learning 3D Particle-based Simulators from RGB-D Videos
Dec 08, 2023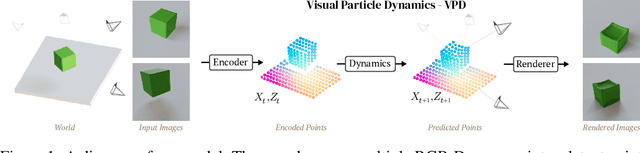

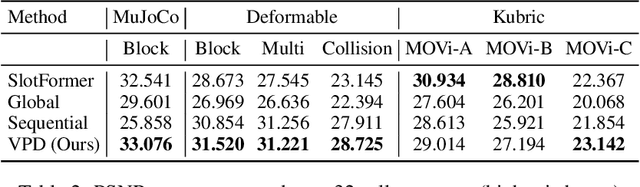
Realistic simulation is critical for applications ranging from robotics to animation. Traditional analytic simulators sometimes struggle to capture sufficiently realistic simulation which can lead to problems including the well known "sim-to-real" gap in robotics. Learned simulators have emerged as an alternative for better capturing real-world physical dynamics, but require access to privileged ground truth physics information such as precise object geometry or particle tracks. Here we propose a method for learning simulators directly from observations. Visual Particle Dynamics (VPD) jointly learns a latent particle-based representation of 3D scenes, a neural simulator of the latent particle dynamics, and a renderer that can produce images of the scene from arbitrary views. VPD learns end to end from posed RGB-D videos and does not require access to privileged information. Unlike existing 2D video prediction models, we show that VPD's 3D structure enables scene editing and long-term predictions. These results pave the way for downstream applications ranging from video editing to robotic planning.
Learning rigid dynamics with face interaction graph networks
Dec 07, 2022



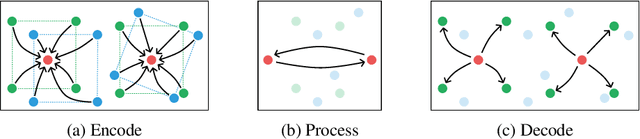
Simulating rigid collisions among arbitrary shapes is notoriously difficult due to complex geometry and the strong non-linearity of the interactions. While graph neural network (GNN)-based models are effective at learning to simulate complex physical dynamics, such as fluids, cloth and articulated bodies, they have been less effective and efficient on rigid-body physics, except with very simple shapes. Existing methods that model collisions through the meshes' nodes are often inaccurate because they struggle when collisions occur on faces far from nodes. Alternative approaches that represent the geometry densely with many particles are prohibitively expensive for complex shapes. Here we introduce the Face Interaction Graph Network (FIGNet) which extends beyond GNN-based methods, and computes interactions between mesh faces, rather than nodes. Compared to learned node- and particle-based methods, FIGNet is around 4x more accurate in simulating complex shape interactions, while also 8x more computationally efficient on sparse, rigid meshes. Moreover, FIGNet can learn frictional dynamics directly from real-world data, and can be more accurate than analytical solvers given modest amounts of training data. FIGNet represents a key step forward in one of the few remaining physical domains which have seen little competition from learned simulators, and offers allied fields such as robotics, graphics and mechanical design a new tool for simulation and model-based planning.