 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKinDER: A Physical Reasoning Benchmark for Robot Learning and Planning
Apr 28, 2026Robotic systems that interact with the physical world must reason about kinematic and dynamic constraints imposed by their own embodiment, their environment, and the task at hand. We introduce KinDER, a benchmark for Kinematic and Dynamic Embodied Reasoning that targets physical reasoning challenges arising in robot learning and planning. KinDER comprises 25 procedurally generated environments, a Gymnasium-compatible Python library with parameterized skills and demonstrations, and a standardized evaluation suite with 13 implemented baselines spanning task and motion planning, imitation learning, reinforcement learning, and foundation-model-based approaches. The environments are designed to isolate five core physical reasoning challenges: basic spatial relations, nonprehensile multi-object manipulation, tool use, combinatorial geometric constraints, and dynamic constraints, disentangled from perception, language understanding, and application-specific complexity. Empirical evaluation shows that existing methods struggle to solve many of the environments, indicating substantial gaps in current approaches to physical reasoning. We additionally include real-to-sim-to-real experiments on a mobile manipulator to assess the correspondence between simulation and real-world physical interaction. KinDER is fully open-sourced and intended to enable systematic comparison across diverse paradigms for advancing physical reasoning in robotics. Website and code: https://prpl-group.com/kinder-site/
A Human-in-the-Loop Confidence-Aware Failure Recovery Framework for Modular Robot Policies
Feb 10, 2026Robots operating in unstructured human environments inevitably encounter failures, especially in robot caregiving scenarios. While humans can often help robots recover, excessive or poorly targeted queries impose unnecessary cognitive and physical workload on the human partner. We present a human-in-the-loop failure-recovery framework for modular robotic policies, where a policy is composed of distinct modules such as perception, planning, and control, any of which may fail and often require different forms of human feedback. Our framework integrates calibrated estimates of module-level uncertainty with models of human intervention cost to decide which module to query and when to query the human. It separates these two decisions: a module selector identifies the module most likely responsible for failure, and a querying algorithm determines whether to solicit human input or act autonomously. We evaluate several module-selection strategies and querying algorithms in controlled synthetic experiments, revealing trade-offs between recovery efficiency, robustness to system and user variables, and user workload. Finally, we deploy the framework on a robot-assisted bite acquisition system and demonstrate, in studies involving individuals with both emulated and real mobility limitations, that it improves recovery success while reducing the workload imposed on users. Our results highlight how explicitly reasoning about both robot uncertainty and human effort can enable more efficient and user-centered failure recovery in collaborative robots. Supplementary materials and videos can be found at: http://emprise.cs.cornell.edu/modularhil
Unifying Deep Predicate Invention with Pre-trained Foundation Models
Dec 19, 2025Long-horizon robotic tasks are hard due to continuous state-action spaces and sparse feedback. Symbolic world models help by decomposing tasks into discrete predicates that capture object properties and relations. Existing methods learn predicates either top-down, by prompting foundation models without data grounding, or bottom-up, from demonstrations without high-level priors. We introduce UniPred, a bilevel learning framework that unifies both. UniPred uses large language models (LLMs) to propose predicate effect distributions that supervise neural predicate learning from low-level data, while learned feedback iteratively refines the LLM hypotheses. Leveraging strong visual foundation model features, UniPred learns robust predicate classifiers in cluttered scenes. We further propose a predicate evaluation method that supports symbolic models beyond STRIPS assumptions. Across five simulated and one real-robot domains, UniPred achieves 2-4 times higher success rates than top-down methods and 3-4 times faster learning than bottom-up approaches, advancing scalable and flexible symbolic world modeling for robotics.
FEAST: A Flexible Mealtime-Assistance System Towards In-the-Wild Personalization
Jun 17, 2025Physical caregiving robots hold promise for improving the quality of life of millions worldwide who require assistance with feeding. However, in-home meal assistance remains challenging due to the diversity of activities (e.g., eating, drinking, mouth wiping), contexts (e.g., socializing, watching TV), food items, and user preferences that arise during deployment. In this work, we propose FEAST, a flexible mealtime-assistance system that can be personalized in-the-wild to meet the unique needs of individual care recipients. Developed in collaboration with two community researchers and informed by a formative study with a diverse group of care recipients, our system is guided by three key tenets for in-the-wild personalization: adaptability, transparency, and safety. FEAST embodies these principles through: (i) modular hardware that enables switching between assisted feeding, drinking, and mouth-wiping, (ii) diverse interaction methods, including a web interface, head gestures, and physical buttons, to accommodate diverse functional abilities and preferences, and (iii) parameterized behavior trees that can be safely and transparently adapted using a large language model. We evaluate our system based on the personalization requirements identified in our formative study, demonstrating that FEAST offers a wide range of transparent and safe adaptations and outperforms a state-of-the-art baseline limited to fixed customizations. To demonstrate real-world applicability, we conduct an in-home user study with two care recipients (who are community researchers), feeding them three meals each across three diverse scenarios. We further assess FEAST's ecological validity by evaluating with an Occupational Therapist previously unfamiliar with the system. In all cases, users successfully personalize FEAST to meet their individual needs and preferences. Website: https://emprise.cs.cornell.edu/feast
CLAMP: Crowdsourcing a LArge-scale in-the-wild haptic dataset with an open-source device for Multimodal robot Perception
May 27, 2025


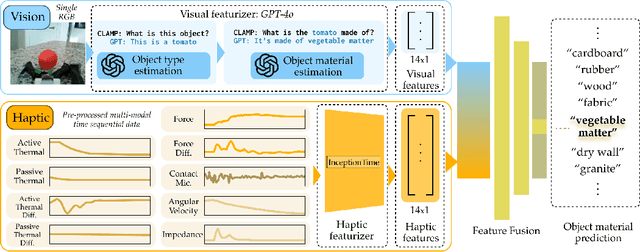
Robust robot manipulation in unstructured environments often requires understanding object properties that extend beyond geometry, such as material or compliance-properties that can be challenging to infer using vision alone. Multimodal haptic sensing provides a promising avenue for inferring such properties, yet progress has been constrained by the lack of large, diverse, and realistic haptic datasets. In this work, we introduce the CLAMP device, a low-cost (<\$200) sensorized reacher-grabber designed to collect large-scale, in-the-wild multimodal haptic data from non-expert users in everyday settings. We deployed 16 CLAMP devices to 41 participants, resulting in the CLAMP dataset, the largest open-source multimodal haptic dataset to date, comprising 12.3 million datapoints across 5357 household objects. Using this dataset, we train a haptic encoder that can infer material and compliance object properties from multimodal haptic data. We leverage this encoder to create the CLAMP model, a visuo-haptic perception model for material recognition that generalizes to novel objects and three robot embodiments with minimal finetuning. We also demonstrate the effectiveness of our model in three real-world robot manipulation tasks: sorting recyclable and non-recyclable waste, retrieving objects from a cluttered bag, and distinguishing overripe from ripe bananas. Our results show that large-scale, in-the-wild haptic data collection can unlock new capabilities for generalizable robot manipulation. Website: https://emprise.cs.cornell.edu/clamp/
Coloring Between the Lines: Personalization in the Null Space of Planning Constraints
May 21, 2025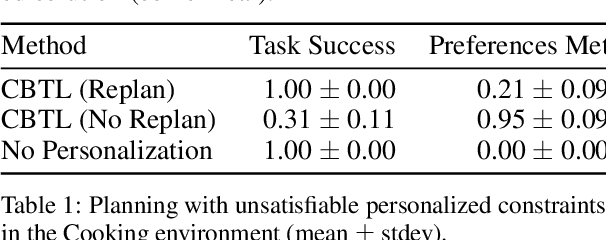


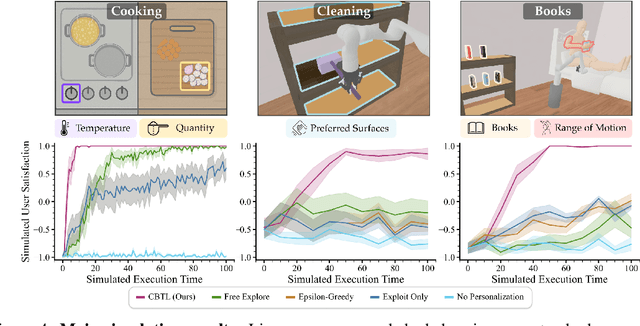
Generalist robots must personalize in-the-wild to meet the diverse needs and preferences of long-term users. How can we enable flexible personalization without sacrificing safety or competency? This paper proposes Coloring Between the Lines (CBTL), a method for personalization that exploits the null space of constraint satisfaction problems (CSPs) used in robot planning. CBTL begins with a CSP generator that ensures safe and competent behavior, then incrementally personalizes behavior by learning parameterized constraints from online interaction. By quantifying uncertainty and leveraging the compositionality of planning constraints, CBTL achieves sample-efficient adaptation without environment resets. We evaluate CBTL in (1) three diverse simulation environments; (2) a web-based user study; and (3) a real-robot assisted feeding system, finding that CBTL consistently achieves more effective personalization with fewer interactions than baselines. Our results demonstrate that CBTL provides a unified and practical approach for continual, flexible, active, and safe robot personalization. Website: https://emprise.cs.cornell.edu/cbtl/
Seeing is Believing: Belief-Space Planning with Foundation Models as Uncertainty Estimators
Apr 04, 2025Generalizable robotic mobile manipulation in open-world environments poses significant challenges due to long horizons, complex goals, and partial observability. A promising approach to address these challenges involves planning with a library of parameterized skills, where a task planner sequences these skills to achieve goals specified in structured languages, such as logical expressions over symbolic facts. While vision-language models (VLMs) can be used to ground these expressions, they often assume full observability, leading to suboptimal behavior when the agent lacks sufficient information to evaluate facts with certainty. This paper introduces a novel framework that leverages VLMs as a perception module to estimate uncertainty and facilitate symbolic grounding. Our approach constructs a symbolic belief representation and uses a belief-space planner to generate uncertainty-aware plans that incorporate strategic information gathering. This enables the agent to effectively reason about partial observability and property uncertainty. We demonstrate our system on a range of challenging real-world tasks that require reasoning in partially observable environments. Simulated evaluations show that our approach outperforms both vanilla VLM-based end-to-end planning or VLM-based state estimation baselines by planning for and executing strategic information gathering. This work highlights the potential of VLMs to construct belief-space symbolic scene representations, enabling downstream tasks such as uncertainty-aware planning.
Bilevel Learning for Bilevel Planning
Feb 12, 2025A robot that learns from demonstrations should not just imitate what it sees -- it should understand the high-level concepts that are being demonstrated and generalize them to new tasks. Bilevel planning is a hierarchical model-based approach where predicates (relational state abstractions) can be leveraged to achieve compositional generalization. However, previous bilevel planning approaches depend on predicates that are either hand-engineered or restricted to very simple forms, limiting their scalability to sophisticated, high-dimensional state spaces. To address this limitation, we present IVNTR, the first bilevel planning approach capable of learning neural predicates directly from demonstrations. Our key innovation is a neuro-symbolic bilevel learning framework that mirrors the structure of bilevel planning. In IVNTR, symbolic learning of the predicate "effects" and neural learning of the predicate "functions" alternate, with each providing guidance for the other. We evaluate IVNTR in six diverse robot planning domains, demonstrating its effectiveness in abstracting various continuous and high-dimensional states. While most existing approaches struggle to generalize (with <35% success rate), our IVNTR achieves an average of 77% success rate on unseen tasks. Additionally, we showcase IVNTR on a mobile manipulator, where it learns to perform real-world mobile manipulation tasks and generalizes to unseen test scenarios that feature new objects, new states, and longer task horizons. Our findings underscore the promise of learning and planning with abstractions as a path towards high-level generalization.
GRACE: Generalizing Robot-Assisted Caregiving with User Functionality Embeddings
Jan 29, 2025
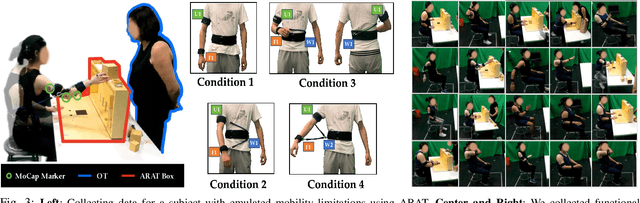


Robot caregiving should be personalized to meet the diverse needs of care recipients -- assisting with tasks as needed, while taking user agency in action into account. In physical tasks such as handover, bathing, dressing, and rehabilitation, a key aspect of this diversity is the functional range of motion (fROM), which can vary significantly between individuals. In this work, we learn to predict personalized fROM as a way to generalize robot decision-making in a wide range of caregiving tasks. We propose a novel data-driven method for predicting personalized fROM using functional assessment scores from occupational therapy. We develop a neural model that learns to embed functional assessment scores into a latent representation of the user's physical function. The model is trained using motion capture data collected from users with emulated mobility limitations. After training, the model predicts personalized fROM for new users without motion capture. Through simulated experiments and a real-robot user study, we show that the personalized fROM predictions from our model enable the robot to provide personalized and effective assistance while improving the user's agency in action. See our website for more visualizations: https://emprise.cs.cornell.edu/grace/.
CART-MPC: Coordinating Assistive Devices for Robot-Assisted Transferring with Multi-Agent Model Predictive Control
Jan 19, 2025



Bed-to-wheelchair transferring is a ubiquitous activity of daily living (ADL), but especially challenging for caregiving robots with limited payloads. We develop a novel algorithm that leverages the presence of other assistive devices: a Hoyer sling and a wheelchair for coarse manipulation of heavy loads, alongside a robot arm for fine-grained manipulation of deformable objects (Hoyer sling straps). We instrument the Hoyer sling and wheelchair with actuators and sensors so that they can become intelligent agents in the algorithm. We then focus on one subtask of the transferring ADL -- tying Hoyer sling straps to the sling bar -- that exemplifies the challenges of transfer: multi-agent planning, deformable object manipulation, and generalization to varying hook shapes, sling materials, and care recipient bodies. To address these challenges, we propose CART-MPC, a novel algorithm based on turn-taking multi-agent model predictive control that uses a learned neural dynamics model for a keypoint-based representation of the deformable Hoyer sling strap, and a novel cost function that leverages linking numbers from knot theory and neural amortization to accelerate inference. We validate it in both RCareWorld simulation and real-world environments. In simulation, CART-MPC successfully generalizes across diverse hook designs, sling materials, and care recipient body shapes. In the real world, we show zero-shot sim-to-real generalization capabilities to tie deformable Hoyer sling straps on a sling bar towards transferring a manikin from a hospital bed to a wheelchair. See our website for supplementary materials: https://emprise.cs.cornell.edu/cart-mpc/.