 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiPToP: A Modular Open-Vocabulary Planning System for Robotic Manipulation
Mar 10, 2026We present TiPToP, an extensible modular system that combines pretrained vision foundation models with an existing Task and Motion Planner (TAMP) to solve multi-step manipulation tasks directly from input RGB images and natural-language instructions. Our system aims to be simple and easy-to-use: it can be installed and run on a standard DROID setup in under one hour and adapted to new embodiments with minimal effort. We evaluate TiPToP -- which requires zero robot data -- over 28 tabletop manipulation tasks in simulation and the real world and find it matches or outperforms $π_{0.5}\text{-DROID}$, a vision-language-action (VLA) model fine-tuned on 350 hours of embodiment-specific demonstrations. TiPToP's modular architecture enables us to analyze the system's failure modes at the component level. We analyze results from an evaluation of 173 trials and identify directions for improvement. We release TiPToP open-source to further research on modular manipulation systems and tighter integration between learning and planning. Project website and code: https://tiptop-robot.github.io
Follow the Signs: Using Textual Cues and LLMs to Guide Efficient Robot Navigation
Jan 10, 2026Autonomous navigation in unfamiliar environments often relies on geometric mapping and planning strategies that overlook rich semantic cues such as signs, room numbers, and textual labels. We propose a novel semantic navigation framework that leverages large language models (LLMs) to infer patterns from partial observations and predict regions where the goal is most likely located. Our method combines local perceptual inputs with frontier-based exploration and periodic LLM queries, which extract symbolic patterns (e.g., room numbering schemes and building layout structures) and update a confidence grid used to guide exploration. This enables robots to move efficiently toward goal locations labeled with textual identifiers (e.g., "room 8") even before direct observation. We demonstrate that this approach enables more efficient navigation in sparse, partially observable grid environments by exploiting symbolic patterns. Experiments across environments modeled after real floor plans show that our approach consistently achieves near-optimal paths and outperforms baselines by over 25% in Success weighted by Path Length.
Seeing is Believing: Belief-Space Planning with Foundation Models as Uncertainty Estimators
Apr 04, 2025Generalizable robotic mobile manipulation in open-world environments poses significant challenges due to long horizons, complex goals, and partial observability. A promising approach to address these challenges involves planning with a library of parameterized skills, where a task planner sequences these skills to achieve goals specified in structured languages, such as logical expressions over symbolic facts. While vision-language models (VLMs) can be used to ground these expressions, they often assume full observability, leading to suboptimal behavior when the agent lacks sufficient information to evaluate facts with certainty. This paper introduces a novel framework that leverages VLMs as a perception module to estimate uncertainty and facilitate symbolic grounding. Our approach constructs a symbolic belief representation and uses a belief-space planner to generate uncertainty-aware plans that incorporate strategic information gathering. This enables the agent to effectively reason about partial observability and property uncertainty. We demonstrate our system on a range of challenging real-world tasks that require reasoning in partially observable environments. Simulated evaluations show that our approach outperforms both vanilla VLM-based end-to-end planning or VLM-based state estimation baselines by planning for and executing strategic information gathering. This work highlights the potential of VLMs to construct belief-space symbolic scene representations, enabling downstream tasks such as uncertainty-aware planning.
Guided Exploration for Efficient Relational Model Learning
Feb 10, 2025
Efficient exploration is critical for learning relational models in large-scale environments with complex, long-horizon tasks. Random exploration methods often collect redundant or irrelevant data, limiting their ability to learn accurate relational models of the environment. Goal-literal babbling (GLIB) improves upon random exploration by setting and planning to novel goals, but its reliance on random actions and random novel goal selection limits its scalability to larger domains. In this work, we identify the principles underlying efficient exploration in relational domains: (1) operator initialization with demonstrations that cover the distinct lifted effects necessary for planning and (2) refining preconditions to collect maximally informative transitions by selecting informative goal-action pairs and executing plans to them. To demonstrate these principles, we introduce Baking-Large, a challenging domain with extensive state-action spaces and long-horizon tasks. We evaluate methods using oracle-driven demonstrations for operator initialization and precondition-targeting guidance to efficiently gather critical transitions. Experiments show that both the oracle demonstrations and precondition-targeting oracle guidance significantly improve sample efficiency and generalization, paving the way for future methods to use these principles to efficiently learn accurate relational models in complex domains.
Predicate Invention from Pixels via Pretrained Vision-Language Models
Dec 31, 2024



Our aim is to learn to solve long-horizon decision-making problems in highly-variable, combinatorially-complex robotics domains given raw sensor input in the form of images. Previous work has shown that one way to achieve this aim is to learn a structured abstract transition model in the form of symbolic predicates and operators, and then plan within this model to solve novel tasks at test time. However, these learned models do not ground directly into pixels from just a handful of demonstrations. In this work, we propose to invent predicates that operate directly over input images by leveraging the capabilities of pretrained vision-language models (VLMs). Our key idea is that, given a set of demonstrations, a VLM can be used to propose a set of predicates that are potentially relevant for decision-making and then to determine the truth values of these predicates in both the given demonstrations and new image inputs. We build upon an existing framework for predicate invention, which generates feature-based predicates operating on object-centric states, to also generate visual predicates that operate on images. Experimentally, we show that our approach -- pix2pred -- is able to invent semantically meaningful predicates that enable generalization to novel, complex, and long-horizon tasks across two simulated robotic environments.
Open-World Task and Motion Planning via Vision-Language Model Inferred Constraints
Nov 13, 2024Foundation models trained on internet-scale data, such as Vision-Language Models (VLMs), excel at performing tasks involving common sense, such as visual question answering. Despite their impressive capabilities, these models cannot currently be directly applied to challenging robot manipulation problems that require complex and precise continuous reasoning. Task and Motion Planning (TAMP) systems can control high-dimensional continuous systems over long horizons through combining traditional primitive robot operations. However, these systems require detailed model of how the robot can impact its environment, preventing them from directly interpreting and addressing novel human objectives, for example, an arbitrary natural language goal. We propose deploying VLMs within TAMP systems by having them generate discrete and continuous language-parameterized constraints that enable TAMP to reason about open-world concepts. Specifically, we propose algorithms for VLM partial planning that constrain a TAMP system's discrete temporal search and VLM continuous constraints interpretation to augment the traditional manipulation constraints that TAMP systems seek to satisfy. We demonstrate our approach on two robot embodiments, including a real world robot, across several manipulation tasks, where the desired objectives are conveyed solely through language.
VisualPredicator: Learning Abstract World Models with Neuro-Symbolic Predicates for Robot Planning
Oct 30, 2024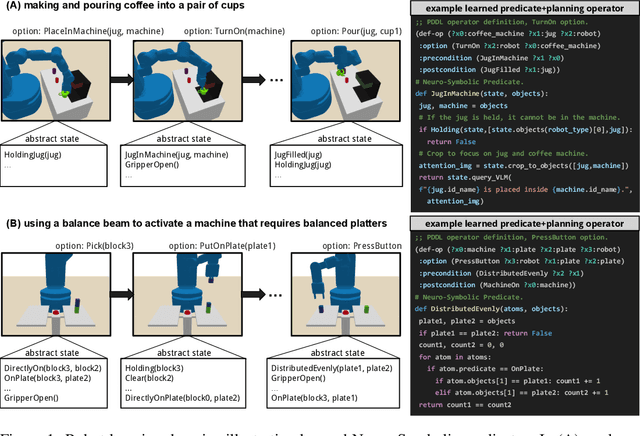
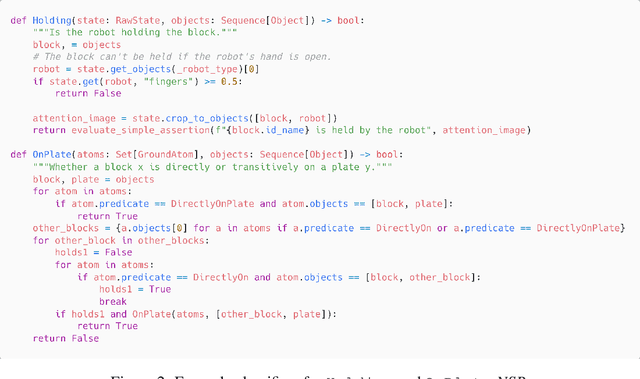
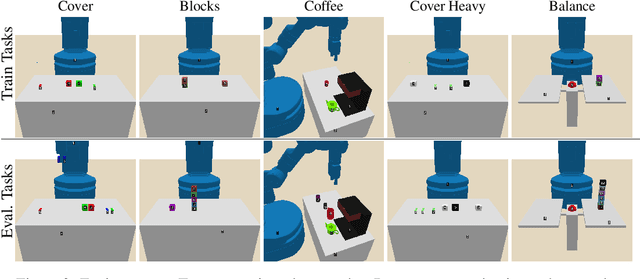
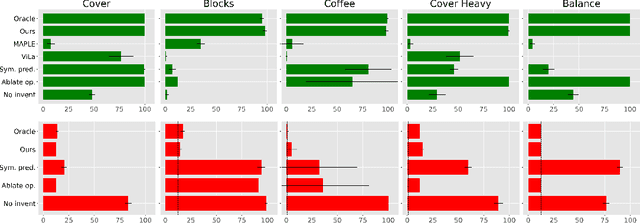
Broadly intelligent agents should form task-specific abstractions that selectively expose the essential elements of a task, while abstracting away the complexity of the raw sensorimotor space. In this work, we present Neuro-Symbolic Predicates, a first-order abstraction language that combines the strengths of symbolic and neural knowledge representations. We outline an online algorithm for inventing such predicates and learning abstract world models. We compare our approach to hierarchical reinforcement learning, vision-language model planning, and symbolic predicate invention approaches, on both in- and out-of-distribution tasks across five simulated robotic domains. Results show that our approach offers better sample complexity, stronger out-of-distribution generalization, and improved interpretability.
AHA: A Vision-Language-Model for Detecting and Reasoning Over Failures in Robotic Manipulation
Oct 01, 2024



Robotic manipulation in open-world settings requires not only task execution but also the ability to detect and learn from failures. While recent advances in vision-language models (VLMs) and large language models (LLMs) have improved robots' spatial reasoning and problem-solving abilities, they still struggle with failure recognition, limiting their real-world applicability. We introduce AHA, an open-source VLM designed to detect and reason about failures in robotic manipulation using natural language. By framing failure detection as a free-form reasoning task, AHA identifies failures and provides detailed, adaptable explanations across different robots, tasks, and environments. We fine-tuned AHA using FailGen, a scalable framework that generates the first large-scale dataset of robotic failure trajectories, the AHA dataset. FailGen achieves this by procedurally perturbing successful demonstrations from simulation. Despite being trained solely on the AHA dataset, AHA generalizes effectively to real-world failure datasets, robotic systems, and unseen tasks. It surpasses the second-best model (GPT-4o in-context learning) by 10.3% and exceeds the average performance of six compared models including five state-of-the-art VLMs by 35.3% across multiple metrics and datasets. We integrate AHA into three manipulation frameworks that utilize LLMs/VLMs for reinforcement learning, task and motion planning, and zero-shot trajectory generation. AHA's failure feedback enhances these policies' performances by refining dense reward functions, optimizing task planning, and improving sub-task verification, boosting task success rates by an average of 21.4% across all three tasks compared to GPT-4 models.
Learning to Bridge the Gap: Efficient Novelty Recovery with Planning and Reinforcement Learning
Sep 28, 2024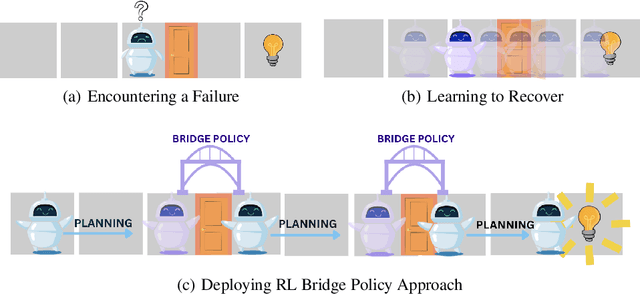

The real world is unpredictable. Therefore, to solve long-horizon decision-making problems with autonomous robots, we must construct agents that are capable of adapting to changes in the environment during deployment. Model-based planning approaches can enable robots to solve complex, long-horizon tasks in a variety of environments. However, such approaches tend to be brittle when deployed into an environment featuring a novel situation that their underlying model does not account for. In this work, we propose to learn a ``bridge policy'' via Reinforcement Learning (RL) to adapt to such novelties. We introduce a simple formulation for such learning, where the RL problem is constructed with a special ``CallPlanner'' action that terminates the bridge policy and hands control of the agent back to the planner. This allows the RL policy to learn the set of states in which querying the planner and following the returned plan will achieve the goal. We show that this formulation enables the agent to rapidly learn by leveraging the planner's knowledge to avoid challenging long-horizon exploration caused by sparse reward. In experiments across three different simulated domains of varying complexity, we demonstrate that our approach is able to learn policies that adapt to novelty more efficiently than several baselines, including a pure RL baseline. We also demonstrate that the learned bridge policy is generalizable in that it can be combined with the planner to enable the agent to solve more complex tasks with multiple instances of the encountered novelty.
Adaptive Language-Guided Abstraction from Contrastive Explanations
Sep 12, 2024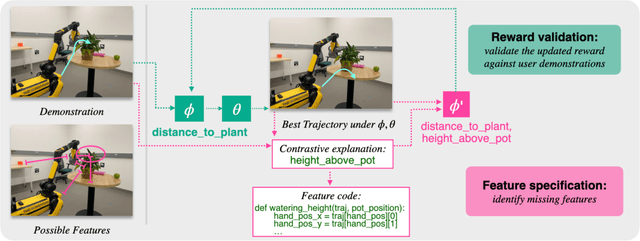
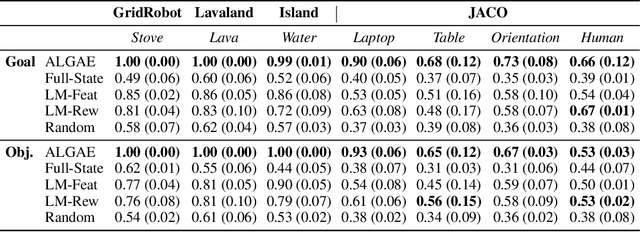

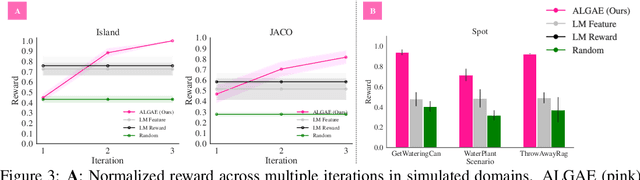
Many approaches to robot learning begin by inferring a reward function from a set of human demonstrations. To learn a good reward, it is necessary to determine which features of the environment are relevant before determining how these features should be used to compute reward. End-to-end methods for joint feature and reward learning (e.g., using deep networks or program synthesis techniques) often yield brittle reward functions that are sensitive to spurious state features. By contrast, humans can often generalizably learn from a small number of demonstrations by incorporating strong priors about what features of a demonstration are likely meaningful for a task of interest. How do we build robots that leverage this kind of background knowledge when learning from new demonstrations? This paper describes a method named ALGAE (Adaptive Language-Guided Abstraction from [Contrastive] Explanations) which alternates between using language models to iteratively identify human-meaningful features needed to explain demonstrated behavior, then standard inverse reinforcement learning techniques to assign weights to these features. Experiments across a variety of both simulated and real-world robot environments show that ALGAE learns generalizable reward functions defined on interpretable features using only small numbers of demonstrations. Importantly, ALGAE can recognize when features are missing, then extract and define those features without any human input -- making it possible to quickly and efficiently acquire rich representations of user behavior.