 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolmoAct: Action Reasoning Models that can Reason in Space
Aug 12, 2025



Reasoning is central to purposeful action, yet most robotic foundation models map perception and instructions directly to control, which limits adaptability, generalization, and semantic grounding. We introduce Action Reasoning Models (ARMs), a class of robotic foundation models that integrate perception, planning, and control through a structured three-stage pipeline. Our model, MolmoAct, encodes observations and instructions into depth-aware perception tokens, generates mid-level spatial plans as editable trajectory traces, and predicts precise low-level actions, enabling explainable and steerable behavior. MolmoAct-7B-D achieves strong performance across simulation and real-world settings: 70.5% zero-shot accuracy on SimplerEnv Visual Matching tasks, surpassing closed-source Pi-0 and GR00T N1; 86.6% average success on LIBERO, including an additional 6.3% gain over ThinkAct on long-horizon tasks; and in real-world fine-tuning, an additional 10% (single-arm) and an additional 22.7% (bimanual) task progression over Pi-0-FAST. It also outperforms baselines by an additional 23.3% on out-of-distribution generalization and achieves top human-preference scores for open-ended instruction following and trajectory steering. Furthermore, we release, for the first time, the MolmoAct Dataset -- a mid-training robot dataset comprising over 10,000 high quality robot trajectories across diverse scenarios and tasks. Training with this dataset yields an average 5.5% improvement in general performance over the base model. We release all model weights, training code, our collected dataset, and our action reasoning dataset, establishing MolmoAct as both a state-of-the-art robotics foundation model and an open blueprint for building ARMs that transform perception into purposeful action through structured reasoning. Blogpost: https://allenai.org/blog/molmoact
PointArena: Probing Multimodal Grounding Through Language-Guided Pointing
May 15, 2025Pointing serves as a fundamental and intuitive mechanism for grounding language within visual contexts, with applications spanning robotics, assistive technologies, and interactive AI systems. While recent multimodal models have started to support pointing capabilities, existing benchmarks typically focus only on referential object localization tasks. We introduce PointArena, a comprehensive platform for evaluating multimodal pointing across diverse reasoning scenarios. PointArena comprises three components: (1) Point-Bench, a curated dataset containing approximately 1,000 pointing tasks across five reasoning categories; (2) Point-Battle, an interactive, web-based arena facilitating blind, pairwise model comparisons, which has already gathered over 4,500 anonymized votes; and (3) Point-Act, a real-world robotic manipulation system allowing users to directly evaluate multimodal model pointing capabilities in practical settings. We conducted extensive evaluations of both state-of-the-art open-source and proprietary multimodal models. Results indicate that Molmo-72B consistently outperforms other models, though proprietary models increasingly demonstrate comparable performance. Additionally, we find that supervised training specifically targeting pointing tasks significantly enhances model performance. Across our multi-stage evaluation pipeline, we also observe strong correlations, underscoring the critical role of precise pointing capabilities in enabling multimodal models to effectively bridge abstract reasoning with concrete, real-world actions. Project page: https://pointarena.github.io/
SAM2Act: Integrating Visual Foundation Model with A Memory Architecture for Robotic Manipulation
Jan 30, 2025



Robotic manipulation systems operating in diverse, dynamic environments must exhibit three critical abilities: multitask interaction, generalization to unseen scenarios, and spatial memory. While significant progress has been made in robotic manipulation, existing approaches often fall short in generalization to complex environmental variations and addressing memory-dependent tasks. To bridge this gap, we introduce SAM2Act, a multi-view robotic transformer-based policy that leverages multi-resolution upsampling with visual representations from large-scale foundation model. SAM2Act achieves a state-of-the-art average success rate of 86.8% across 18 tasks in the RLBench benchmark, and demonstrates robust generalization on The Colosseum benchmark, with only a 4.3% performance gap under diverse environmental perturbations. Building on this foundation, we propose SAM2Act+, a memory-based architecture inspired by SAM2, which incorporates a memory bank, an encoder, and an attention mechanism to enhance spatial memory. To address the need for evaluating memory-dependent tasks, we introduce MemoryBench, a novel benchmark designed to assess spatial memory and action recall in robotic manipulation. SAM2Act+ achieves competitive performance on MemoryBench, significantly outperforming existing approaches and pushing the boundaries of memory-enabled robotic systems. Project page: https://sam2act.github.io/
AHA: A Vision-Language-Model for Detecting and Reasoning Over Failures in Robotic Manipulation
Oct 01, 2024



Robotic manipulation in open-world settings requires not only task execution but also the ability to detect and learn from failures. While recent advances in vision-language models (VLMs) and large language models (LLMs) have improved robots' spatial reasoning and problem-solving abilities, they still struggle with failure recognition, limiting their real-world applicability. We introduce AHA, an open-source VLM designed to detect and reason about failures in robotic manipulation using natural language. By framing failure detection as a free-form reasoning task, AHA identifies failures and provides detailed, adaptable explanations across different robots, tasks, and environments. We fine-tuned AHA using FailGen, a scalable framework that generates the first large-scale dataset of robotic failure trajectories, the AHA dataset. FailGen achieves this by procedurally perturbing successful demonstrations from simulation. Despite being trained solely on the AHA dataset, AHA generalizes effectively to real-world failure datasets, robotic systems, and unseen tasks. It surpasses the second-best model (GPT-4o in-context learning) by 10.3% and exceeds the average performance of six compared models including five state-of-the-art VLMs by 35.3% across multiple metrics and datasets. We integrate AHA into three manipulation frameworks that utilize LLMs/VLMs for reinforcement learning, task and motion planning, and zero-shot trajectory generation. AHA's failure feedback enhances these policies' performances by refining dense reward functions, optimizing task planning, and improving sub-task verification, boosting task success rates by an average of 21.4% across all three tasks compared to GPT-4 models.
Manipulate-Anything: Automating Real-World Robots using Vision-Language Models
Jun 27, 2024Large-scale endeavors like RT-1 and widespread community efforts such as Open-X-Embodiment have contributed to growing the scale of robot demonstration data. However, there is still an opportunity to improve the quality, quantity, and diversity of robot demonstration data. Although vision-language models have been shown to automatically generate demonstration data, their utility has been limited to environments with privileged state information, they require hand-designed skills, and are limited to interactions with few object instances. We propose Manipulate-Anything, a scalable automated generation method for real-world robotic manipulation. Unlike prior work, our method can operate in real-world environments without any privileged state information, hand-designed skills, and can manipulate any static object. We evaluate our method using two setups. First, Manipulate-Anything successfully generates trajectories for all 5 real-world and 12 simulation tasks, significantly outperforming existing methods like VoxPoser. Second, Manipulate-Anything's demonstrations can train more robust behavior cloning policies than training with human demonstrations, or from data generated by VoxPoser and Code-As-Policies. We believe \methodLong\ can be the scalable method for both generating data for robotics and solving novel tasks in a zero-shot setting.
NEWTON: Are Large Language Models Capable of Physical Reasoning?
Oct 10, 2023

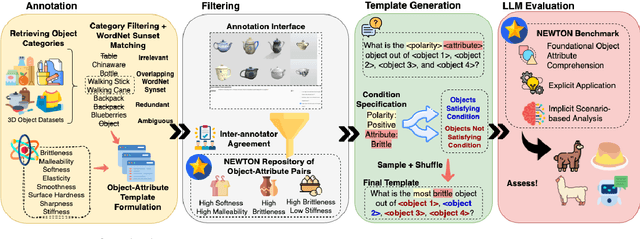
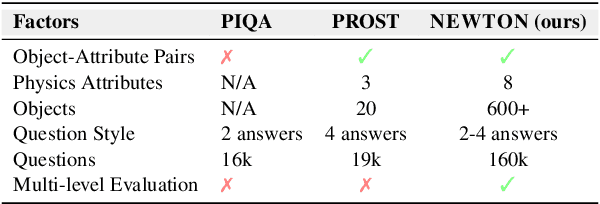
Large Language Models (LLMs), through their contextualized representations, have been empirically proven to encapsulate syntactic, semantic, word sense, and common-sense knowledge. However, there has been limited exploration of their physical reasoning abilities, specifically concerning the crucial attributes for comprehending everyday objects. To address this gap, we introduce NEWTON, a repository and benchmark for evaluating the physics reasoning skills of LLMs. Further, to enable domain-specific adaptation of this benchmark, we present a pipeline to enable researchers to generate a variant of this benchmark that has been customized to the objects and attributes relevant for their application. The NEWTON repository comprises a collection of 2800 object-attribute pairs, providing the foundation for generating infinite-scale assessment templates. The NEWTON benchmark consists of 160K QA questions, curated using the NEWTON repository to investigate the physical reasoning capabilities of several mainstream language models across foundational, explicit, and implicit reasoning tasks. Through extensive empirical analysis, our results highlight the capabilities of LLMs for physical reasoning. We find that LLMs like GPT-4 demonstrate strong reasoning capabilities in scenario-based tasks but exhibit less consistency in object-attribute reasoning compared to humans (50% vs. 84%). Furthermore, the NEWTON platform demonstrates its potential for evaluating and enhancing language models, paving the way for their integration into physically grounded settings, such as robotic manipulation. Project site: https://newtonreasoning.github.io
AR2-D2:Training a Robot Without a Robot
Jun 23, 2023Diligently gathered human demonstrations serve as the unsung heroes empowering the progression of robot learning. Today, demonstrations are collected by training people to use specialized controllers, which (tele-)operate robots to manipulate a small number of objects. By contrast, we introduce AR2-D2: a system for collecting demonstrations which (1) does not require people with specialized training, (2) does not require any real robots during data collection, and therefore, (3) enables manipulation of diverse objects with a real robot. AR2-D2 is a framework in the form of an iOS app that people can use to record a video of themselves manipulating any object while simultaneously capturing essential data modalities for training a real robot. We show that data collected via our system enables the training of behavior cloning agents in manipulating real objects. Our experiments further show that training with our AR data is as effective as training with real-world robot demonstrations. Moreover, our user study indicates that users find AR2-D2 intuitive to use and require no training in contrast to four other frequently employed methods for collecting robot demonstrations.
MVTrans: Multi-View Perception of Transparent Objects
Feb 22, 2023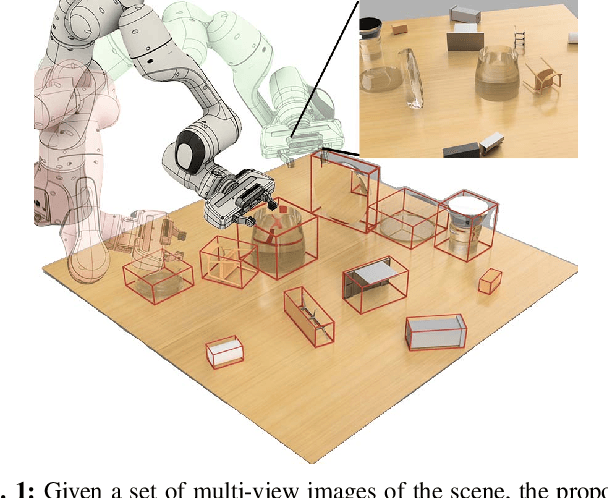

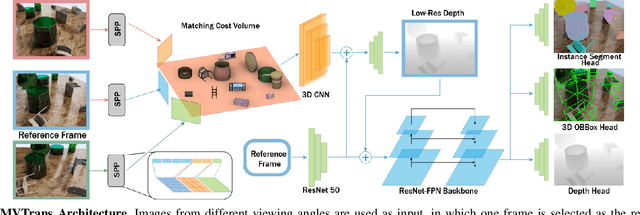

Transparent object perception is a crucial skill for applications such as robot manipulation in household and laboratory settings. Existing methods utilize RGB-D or stereo inputs to handle a subset of perception tasks including depth and pose estimation. However, transparent object perception remains to be an open problem. In this paper, we forgo the unreliable depth map from RGB-D sensors and extend the stereo based method. Our proposed method, MVTrans, is an end-to-end multi-view architecture with multiple perception capabilities, including depth estimation, segmentation, and pose estimation. Additionally, we establish a novel procedural photo-realistic dataset generation pipeline and create a large-scale transparent object detection dataset, Syn-TODD, which is suitable for training networks with all three modalities, RGB-D, stereo and multi-view RGB. Project Site: https://ac-rad.github.io/MVTrans/
CONetV2: Efficient Auto-Channel Size Optimization for CNNs
Oct 13, 2021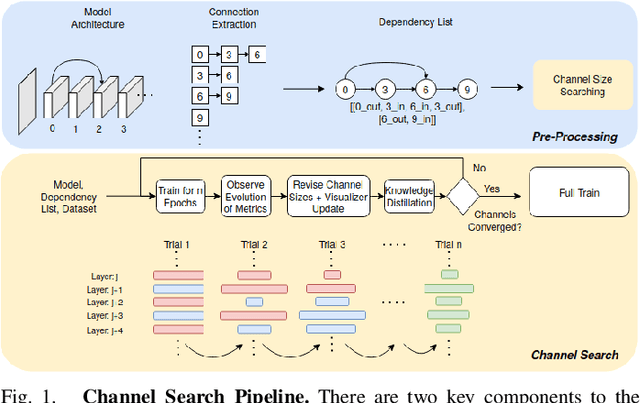
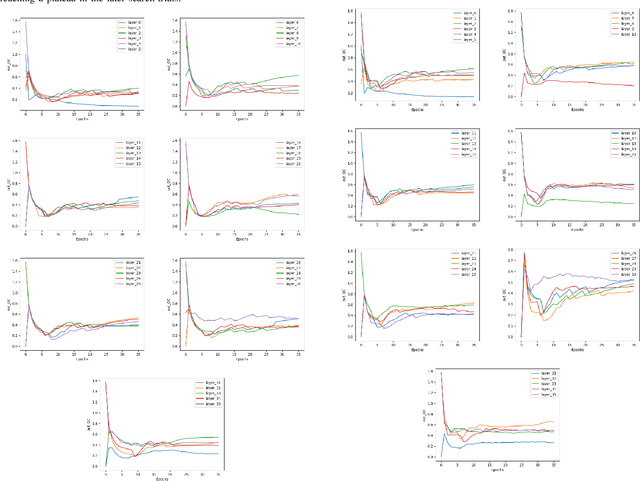


Neural Architecture Search (NAS) has been pivotal in finding optimal network configurations for Convolution Neural Networks (CNNs). While many methods explore NAS from a global search-space perspective, the employed optimization schemes typically require heavy computational resources. This work introduces a method that is efficient in computationally constrained environments by examining the micro-search space of channel size. In tackling channel-size optimization, we design an automated algorithm to extract the dependencies within different connected layers of the network. In addition, we introduce the idea of knowledge distillation, which enables preservation of trained weights, admist trials where the channel sizes are changing. Further, since the standard performance indicators (accuracy, loss) fail to capture the performance of individual network components (providing an overall network evaluation), we introduce a novel metric that highly correlates with test accuracy and enables analysis of individual network layers. Combining dependency extraction, metrics, and knowledge distillation, we introduce an efficient searching algorithm, with simulated annealing inspired stochasticity, and demonstrate its effectiveness in finding optimal architectures that outperform baselines by a large margin.
Seeing Glass: Joint Point Cloud and Depth Completion for Transparent Objects
Sep 30, 2021
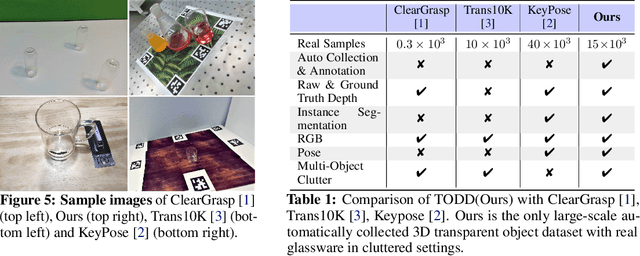
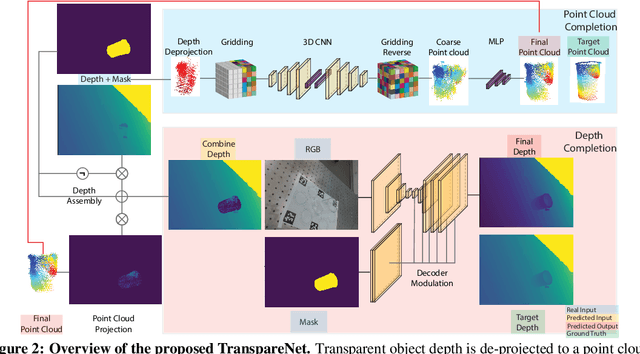
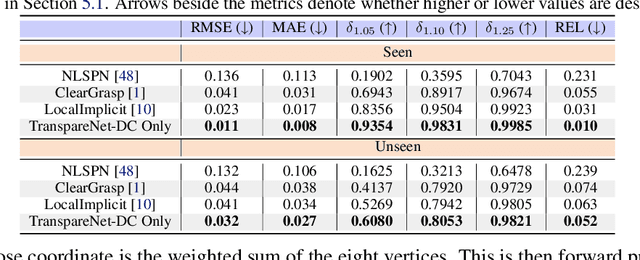
The basis of many object manipulation algorithms is RGB-D input. Yet, commodity RGB-D sensors can only provide distorted depth maps for a wide range of transparent objects due light refraction and absorption. To tackle the perception challenges posed by transparent objects, we propose TranspareNet, a joint point cloud and depth completion method, with the ability to complete the depth of transparent objects in cluttered and complex scenes, even with partially filled fluid contents within the vessels. To address the shortcomings of existing transparent object data collection schemes in literature, we also propose an automated dataset creation workflow that consists of robot-controlled image collection and vision-based automatic annotation. Through this automated workflow, we created Toronto Transparent Objects Depth Dataset (TODD), which consists of nearly 15000 RGB-D images. Our experimental evaluation demonstrates that TranspareNet outperforms existing state-of-the-art depth completion methods on multiple datasets, including ClearGrasp, and that it also handles cluttered scenes when trained on TODD. Code and dataset will be released at https://www.pair.toronto.edu/TranspareNet/