 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOOZY: A Patient-First Foundation Model for Computational Pathology
Mar 31, 2026Computational pathology needs whole-slide image (WSI) foundation models that transfer across diverse clinical tasks, yet current approaches remain largely slide-centric, often depend on private data and expensive paired-report supervision, and do not explicitly model relationships among multiple slides from the same patient. We present MOOZY, a patient-first pathology foundation model in which the patient case, not the individual slide, is the core unit of representation. MOOZY explicitly models dependencies across all slides from the same patient via a case transformer during pretraining, combining multi-stage open self-supervision with scaled low-cost task supervision. In Stage 1, we pretrain a vision-only slide encoder on 77,134 public slide feature grids using masked self-distillation. In Stage 2, we align these representations with clinical semantics using a case transformer and multi-task supervision over 333 tasks from 56 public datasets, including 205 classification and 128 survival tasks across four endpoints. Across eight held-out tasks with five-fold frozen-feature probe evaluation, MOOZY achieves best or tied-best performance on most metrics and improves macro averages over TITAN by +7.37%, +5.50%, and +7.83% and over PRISM by +8.83%, +10.70%, and +9.78% for weighted F1, weighted ROC-AUC, and balanced accuracy, respectively. MOOZY is also parameter efficient with 85.77M parameters, 14x smaller than GigaPath. These results demonstrate that open, reproducible patient-level pretraining yields transferable embeddings, providing a practical path toward scalable patient-first histopathology foundation models.
MonoLoss: A Training Objective for Interpretable Monosemantic Representations
Feb 12, 2026Sparse autoencoders (SAEs) decompose polysemantic neural representations, where neurons respond to multiple unrelated concepts, into monosemantic features that capture single, interpretable concepts. However, standard training objectives only weakly encourage this decomposition, and existing monosemanticity metrics require pairwise comparisons across all dataset samples, making them inefficient during training and evaluation. We study a recent MonoScore metric and derive a single-pass algorithm that computes exactly the same quantity, but with a cost that grows linearly, rather than quadratically, with the number of dataset images. On OpenImagesV7, we achieve up to a 1200x speedup wall-clock speedup in evaluation and 159x during training, while adding only ~4% per-epoch overhead. This allows us to treat MonoScore as a training signal: we introduce the Monosemanticity Loss (MonoLoss), a plug-in objective that directly rewards semantically consistent activations for learning interpretable monosemantic representations. Across SAEs trained on CLIP, SigLIP2, and pretrained ViT features, using BatchTopK, TopK, and JumpReLU SAEs, MonoLoss increases MonoScore for most latents. MonoLoss also consistently improves class purity (the fraction of a latent's activating images belonging to its dominant class) across all encoder and SAE combinations, with the largest gain raising baseline purity from 0.152 to 0.723. Used as an auxiliary regularizer during ResNet-50 and CLIP-ViT-B/32 finetuning, MonoLoss yields up to 0.6\% accuracy gains on ImageNet-1K and monosemantic activating patterns on standard benchmark datasets. The code is publicly available at https://github.com/AtlasAnalyticsLab/MonoLoss.
AtlasPatch: An Efficient and Scalable Tool for Whole Slide Image Preprocessing in Computational Pathology
Feb 03, 2026Whole-slide image (WSI) preprocessing, typically comprising tissue detection followed by patch extraction, is foundational to AI-driven computational pathology workflows. This remains a major computational bottleneck as existing tools either rely on inaccurate heuristic thresholding for tissue detection, or adopt AI-based approaches trained on limited-diversity data that operate at the patch level, incurring substantial computational complexity. We present AtlasPatch, an efficient and scalable slide preprocessing framework for accurate tissue detection and high-throughput patch extraction with minimal computational overhead. AtlasPatch's tissue detection module is trained on a heterogeneous and semi-manually annotated dataset of ~30,000 WSI thumbnails, using efficient fine-tuning of the Segment-Anything model. The tool extrapolates tissue masks from thumbnails to full-resolution slides to extract patch coordinates at user-specified magnifications, with options to stream patches directly into common image encoders for embedding or store patch images, all efficiently parallelized across CPUs and GPUs. We assess AtlasPatch across segmentation precision, computational complexity, and downstream multiple-instance learning, matching state-of-the-art performance while operating at a fraction of their computational cost. AtlasPatch is open-source and available at https://github.com/AtlasAnalyticsLab/AtlasPatch.
Investigating Zero-Shot Diagnostic Pathology in Vision-Language Models with Efficient Prompt Design
Apr 30, 2025



Vision-language models (VLMs) have gained significant attention in computational pathology due to their multimodal learning capabilities that enhance big-data analytics of giga-pixel whole slide image (WSI). However, their sensitivity to large-scale clinical data, task formulations, and prompt design remains an open question, particularly in terms of diagnostic accuracy. In this paper, we present a systematic investigation and analysis of three state of the art VLMs for histopathology, namely Quilt-Net, Quilt-LLAVA, and CONCH, on an in-house digestive pathology dataset comprising 3,507 WSIs, each in giga-pixel form, across distinct tissue types. Through a structured ablative study on cancer invasiveness and dysplasia status, we develop a comprehensive prompt engineering framework that systematically varies domain specificity, anatomical precision, instructional framing, and output constraints. Our findings demonstrate that prompt engineering significantly impacts model performance, with the CONCH model achieving the highest accuracy when provided with precise anatomical references. Additionally, we identify the critical importance of anatomical context in histopathological image analysis, as performance consistently degraded when reducing anatomical precision. We also show that model complexity alone does not guarantee superior performance, as effective domain alignment and domain-specific training are critical. These results establish foundational guidelines for prompt engineering in computational pathology and highlight the potential of VLMs to enhance diagnostic accuracy when properly instructed with domain-appropriate prompts.
Segment Any Crack: Deep Semantic Segmentation Adaptation for Crack Detection
Apr 19, 2025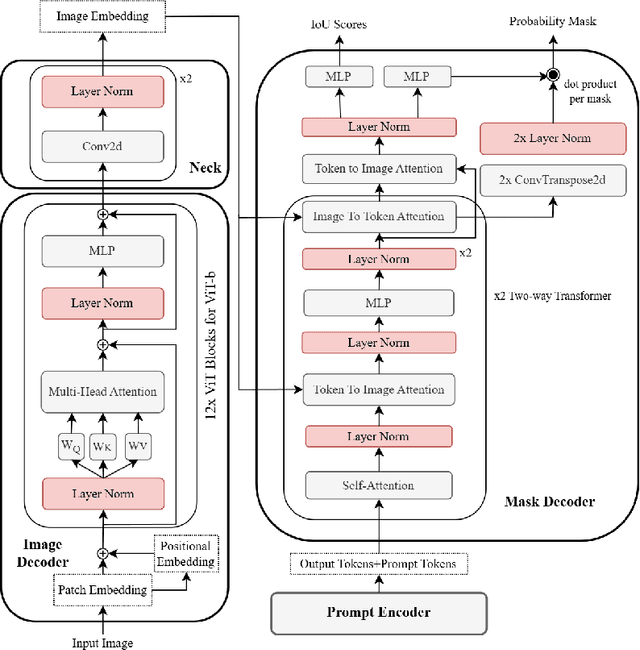
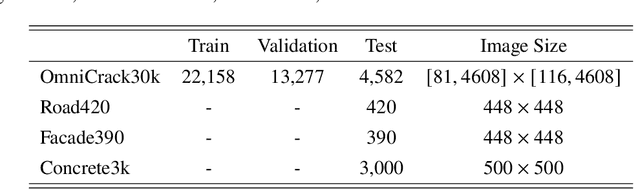


Image-based crack detection algorithms are increasingly in demand in infrastructure monitoring, as early detection of cracks is of paramount importance for timely maintenance planning. While deep learning has significantly advanced crack detection algorithms, existing models often require extensive labeled datasets and high computational costs for fine-tuning, limiting their adaptability across diverse conditions. This study introduces an efficient selective fine-tuning strategy, focusing on tuning normalization components, to enhance the adaptability of segmentation models for crack detection. The proposed method is applied to the Segment Anything Model (SAM) and five well-established segmentation models. Experimental results demonstrate that selective fine-tuning of only normalization parameters outperforms full fine-tuning and other common fine-tuning techniques in both performance and computational efficiency, while improving generalization. The proposed approach yields a SAM-based model, Segment Any Crack (SAC), achieving a 61.22\% F1-score and 44.13\% IoU on the OmniCrack30k benchmark dataset, along with the highest performance across three zero-shot datasets and the lowest standard deviation. The results highlight the effectiveness of the adaptation approach in improving segmentation accuracy while significantly reducing computational overhead.
Ultrasound Image Generation using Latent Diffusion Models
Feb 12, 2025Diffusion models for image generation have been a subject of increasing interest due to their ability to generate diverse, high-quality images. Image generation has immense potential in medical imaging because open-source medical images are difficult to obtain compared to natural images, especially for rare conditions. The generated images can be used later to train classification and segmentation models. In this paper, we propose simulating realistic ultrasound (US) images by successive fine-tuning of large diffusion models on different publicly available databases. To do so, we fine-tuned Stable Diffusion, a state-of-the-art latent diffusion model, on BUSI (Breast US Images) an ultrasound breast image dataset. We successfully generated high-quality US images of the breast using simple prompts that specify the organ and pathology, which appeared realistic to three experienced US scientists and a US radiologist. Additionally, we provided user control by conditioning the model with segmentations through ControlNet. We will release the source code at http://code.sonography.ai/ to allow fast US image generation to the scientific community.
2DMamba: Efficient State Space Model for Image Representation with Applications on Giga-Pixel Whole Slide Image Classification
Dec 01, 2024Efficiently modeling large 2D contexts is essential for various fields including Giga-Pixel Whole Slide Imaging (WSI) and remote sensing. Transformer-based models offer high parallelism but face challenges due to their quadratic complexity for handling long sequences. Recently, Mamba introduced a selective State Space Model (SSM) with linear complexity and high parallelism, enabling effective and efficient modeling of wide context in 1D sequences. However, extending Mamba to vision tasks, which inherently involve 2D structures, results in spatial discrepancies due to the limitations of 1D sequence processing. On the other hand, current 2D SSMs inherently model 2D structures but they suffer from prohibitively slow computation due to the lack of efficient parallel algorithms. In this work, we propose 2DMamba, a novel 2D selective SSM framework that incorporates the 2D spatial structure of images into Mamba, with a highly optimized hardware-aware operator, adopting both spatial continuity and computational efficiency. We validate the versatility of our approach on both WSIs and natural images. Extensive experiments on 10 public datasets for WSI classification and survival analysis show that 2DMamba~improves up to $2.48\%$ in AUC, $3.11\%$ in F1 score, $2.47\%$ in accuracy and $5.52\%$ in C-index. Additionally, integrating our method with VMamba for natural imaging yields $0.5$ to $0.7$ improvements in mIoU on the ADE20k semantic segmentation dataset, and $0.2\%$ accuracy improvement on ImageNet-1K classification dataset. Our code is available at https://github.com/AtlasAnalyticsLab/2DMamba.
Comparative Analysis of Diffusion Generative Models in Computational Pathology
Nov 24, 2024



Diffusion Generative Models (DGM) have rapidly surfaced as emerging topics in the field of computer vision, garnering significant interest across a wide array of deep learning applications. Despite their high computational demand, these models are extensively utilized for their superior sample quality and robust mode coverage. While research in diffusion generative models is advancing, exploration within the domain of computational pathology and its large-scale datasets has been comparatively gradual. Bridging the gap between the high-quality generation capabilities of Diffusion Generative Models and the intricate nature of pathology data, this paper presents an in-depth comparative analysis of diffusion methods applied to a pathology dataset. Our analysis extends to datasets with varying Fields of View (FOV), revealing that DGMs are highly effective in producing high-quality synthetic data. An ablative study is also conducted, followed by a detailed discussion on the impact of various methods on the synthesized histopathology images. One striking observation from our experiments is how the adjustment of image size during data generation can simulate varying fields of view. These findings underscore the potential of DGMs to enhance the quality and diversity of synthetic pathology data, especially when used with real data, ultimately increasing accuracy of deep learning models in histopathology. Code is available from https://github.com/AtlasAnalyticsLab/Diffusion4Path
Efficient Self-Supervised Barlow Twins from Limited Tissue Slide Cohorts for Colonic Pathology Diagnostics
Nov 08, 2024



Colorectal cancer (CRC) is one of the few cancers that have an established dysplasia-carcinoma sequence that benefits from screening. Everyone over 50 years of age in Canada is eligible for CRC screening. About 20\% of those people will undergo a biopsy for a pre-neoplastic polyp and, in many cases, multiple polyps. As such, these polyp biopsies make up the bulk of a pathologist's workload. Developing an efficient computational model to help screen these polyp biopsies can improve the pathologist's workflow and help guide their attention to critical areas on the slide. DL models face significant challenges in computational pathology (CPath) because of the gigapixel image size of whole-slide images and the scarcity of detailed annotated datasets. It is, therefore, crucial to leverage self-supervised learning (SSL) methods to alleviate the burden and cost of data annotation. However, current research lacks methods to apply SSL frameworks to analyze pathology data effectively. This paper aims to propose an optimized Barlow Twins framework for colorectal polyps screening. We adapt its hyperparameters, augmentation strategy and encoder to the specificity of the pathology data to enhance performance. Additionally, we investigate the best Field of View (FoV) for colorectal polyps screening and propose a new benchmark dataset for CRC screening, made of four types of colorectal polyps and normal tissue, by performing downstream tasking on MHIST and NCT-CRC-7K datasets. Furthermore, we show that the SSL representations are more meaningful and qualitative than the supervised ones and that Barlow Twins benefits from the Swin Transformer when applied to pathology data. Codes are avaialble from https://github.com/AtlasAnalyticsLab/PathBT.
Vision Mamba for Classification of Breast Ultrasound Images
Jul 04, 2024Mamba-based models, VMamba and Vim, are a recent family of vision encoders that offer promising performance improvements in many computer vision tasks. This paper compares Mamba-based models with traditional Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) using the breast ultrasound BUSI and B datasets. Our evaluation, which includes multiple runs of experiments and statistical significance analysis, demonstrates that Mamba-based architectures frequently outperform CNN and ViT models with statistically significant results. These Mamba-based models effectively capture long-range dependencies while maintaining inductive biases, making them suitable for applications with limited data.