 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Analysis of Diffusion Generative Models in Computational Pathology
Nov 24, 2024



Diffusion Generative Models (DGM) have rapidly surfaced as emerging topics in the field of computer vision, garnering significant interest across a wide array of deep learning applications. Despite their high computational demand, these models are extensively utilized for their superior sample quality and robust mode coverage. While research in diffusion generative models is advancing, exploration within the domain of computational pathology and its large-scale datasets has been comparatively gradual. Bridging the gap between the high-quality generation capabilities of Diffusion Generative Models and the intricate nature of pathology data, this paper presents an in-depth comparative analysis of diffusion methods applied to a pathology dataset. Our analysis extends to datasets with varying Fields of View (FOV), revealing that DGMs are highly effective in producing high-quality synthetic data. An ablative study is also conducted, followed by a detailed discussion on the impact of various methods on the synthesized histopathology images. One striking observation from our experiments is how the adjustment of image size during data generation can simulate varying fields of view. These findings underscore the potential of DGMs to enhance the quality and diversity of synthetic pathology data, especially when used with real data, ultimately increasing accuracy of deep learning models in histopathology. Code is available from https://github.com/AtlasAnalyticsLab/Diffusion4Path
Efficient Self-Supervised Barlow Twins from Limited Tissue Slide Cohorts for Colonic Pathology Diagnostics
Nov 08, 2024



Colorectal cancer (CRC) is one of the few cancers that have an established dysplasia-carcinoma sequence that benefits from screening. Everyone over 50 years of age in Canada is eligible for CRC screening. About 20\% of those people will undergo a biopsy for a pre-neoplastic polyp and, in many cases, multiple polyps. As such, these polyp biopsies make up the bulk of a pathologist's workload. Developing an efficient computational model to help screen these polyp biopsies can improve the pathologist's workflow and help guide their attention to critical areas on the slide. DL models face significant challenges in computational pathology (CPath) because of the gigapixel image size of whole-slide images and the scarcity of detailed annotated datasets. It is, therefore, crucial to leverage self-supervised learning (SSL) methods to alleviate the burden and cost of data annotation. However, current research lacks methods to apply SSL frameworks to analyze pathology data effectively. This paper aims to propose an optimized Barlow Twins framework for colorectal polyps screening. We adapt its hyperparameters, augmentation strategy and encoder to the specificity of the pathology data to enhance performance. Additionally, we investigate the best Field of View (FoV) for colorectal polyps screening and propose a new benchmark dataset for CRC screening, made of four types of colorectal polyps and normal tissue, by performing downstream tasking on MHIST and NCT-CRC-7K datasets. Furthermore, we show that the SSL representations are more meaningful and qualitative than the supervised ones and that Barlow Twins benefits from the Swin Transformer when applied to pathology data. Codes are avaialble from https://github.com/AtlasAnalyticsLab/PathBT.
HistoKT: Cross Knowledge Transfer in Computational Pathology
Jan 27, 2022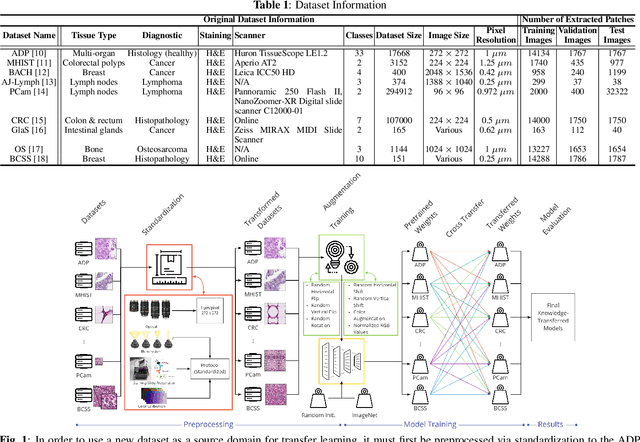



The lack of well-annotated datasets in computational pathology (CPath) obstructs the application of deep learning techniques for classifying medical images. %Since pathologist time is expensive, dataset curation is intrinsically difficult. Many CPath workflows involve transferring learned knowledge between various image domains through transfer learning. Currently, most transfer learning research follows a model-centric approach, tuning network parameters to improve transfer results over few datasets. In this paper, we take a data-centric approach to the transfer learning problem and examine the existence of generalizable knowledge between histopathological datasets. First, we create a standardization workflow for aggregating existing histopathological data. We then measure inter-domain knowledge by training ResNet18 models across multiple histopathological datasets, and cross-transferring between them to determine the quantity and quality of innate shared knowledge. Additionally, we use weight distillation to share knowledge between models without additional training. We find that hard to learn, multi-class datasets benefit most from pretraining, and a two stage learning framework incorporating a large source domain such as ImageNet allows for better utilization of smaller datasets. Furthermore, we find that weight distillation enables models trained on purely histopathological features to outperform models using external natural image data.
Probeable DARTS with Application to Computational Pathology
Aug 16, 2021



AI technology has made remarkable achievements in computational pathology (CPath), especially with the help of deep neural networks. However, the network performance is highly related to architecture design, which commonly requires human experts with domain knowledge. In this paper, we combat this challenge with the recent advance in neural architecture search (NAS) to find an optimal network for CPath applications. In particular, we use differentiable architecture search (DARTS) for its efficiency. We first adopt a probing metric to show that the original DARTS lacks proper hyperparameter tuning on the CIFAR dataset, and how the generalization issue can be addressed using an adaptive optimization strategy. We then apply our searching framework on CPath applications by searching for the optimum network architecture on a histological tissue type dataset (ADP). Results show that the searched network outperforms state-of-the-art networks in terms of prediction accuracy and computation complexity. We further conduct extensive experiments to demonstrate the transferability of the searched network to new CPath applications, the robustness against downscaled inputs, as well as the reliability of predictions.