 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
Computational Pathology: A Survey Review and The Way Forward
Apr 11, 2023



Computational Pathology (CoPath) is an interdisciplinary science that augments developments of computational approaches to analyze and model medical histopathology images. The main objective for CoPath is to develop infrastructure and workflows of digital diagnostics as an assistive CAD system for clinical pathology facilitating transformational changes in the diagnosis and treatment of cancer diseases. With evergrowing developments in deep learning and computer vision algorithms, and the ease of the data flow from digital pathology, currently CoPath is witnessing a paradigm shift. Despite the sheer volume of engineering and scientific works being introduced for cancer image analysis, there is still a considerable gap of adopting and integrating these algorithms in clinical practice. This raises a significant question regarding the direction and trends that are undertaken in CoPath. In this article we provide a comprehensive review of more than 700 papers to address the challenges faced in problem design all-the-way to the application and implementation viewpoints. We have catalogued each paper into a model-card by examining the key works and challenges faced to layout the current landscape in CoPath. We hope this helps the community to locate relevant works and facilitate understanding of the field's future directions. In a nutshell, we oversee the CoPath developments in cycle of stages which are required to be cohesively linked together to address the challenges associated with such multidisciplinary science. We overview this cycle from different perspectives of data-centric, model-centric, and application-centric problems. We finally sketch remaining challenges and provide directions for future technical developments and clinical integration of CoPath.
HistoKT: Cross Knowledge Transfer in Computational Pathology
Jan 27, 2022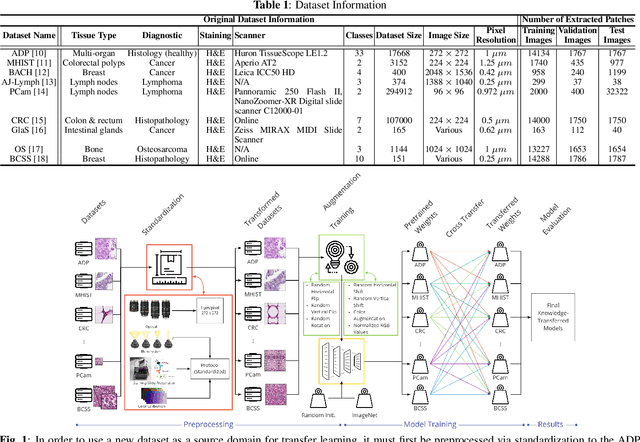



The lack of well-annotated datasets in computational pathology (CPath) obstructs the application of deep learning techniques for classifying medical images. %Since pathologist time is expensive, dataset curation is intrinsically difficult. Many CPath workflows involve transferring learned knowledge between various image domains through transfer learning. Currently, most transfer learning research follows a model-centric approach, tuning network parameters to improve transfer results over few datasets. In this paper, we take a data-centric approach to the transfer learning problem and examine the existence of generalizable knowledge between histopathological datasets. First, we create a standardization workflow for aggregating existing histopathological data. We then measure inter-domain knowledge by training ResNet18 models across multiple histopathological datasets, and cross-transferring between them to determine the quantity and quality of innate shared knowledge. Additionally, we use weight distillation to share knowledge between models without additional training. We find that hard to learn, multi-class datasets benefit most from pretraining, and a two stage learning framework incorporating a large source domain such as ImageNet allows for better utilization of smaller datasets. Furthermore, we find that weight distillation enables models trained on purely histopathological features to outperform models using external natural image data.